English version of the materials are work in progress!
Expect bugs, typos, and other issues. The English version is expected to be completed during spring 2026.
Theoretical Basis of the Relational Model
The relational model is a theory written by Edgar F. Codd, published in 1970 [6], which forms the theoretical basis of relational databases. The theory behind the model is based on set theory and is strong compared to other database paradigms. In this material, the basic theory of the relational database is approached through examples and by comparing it to familiar concepts. The material does not delve into the details of the theory, such as relational algebra – those interested can familiarize themselves with Codd's [6] original paper.
The relational model is a logical-level data model: it describes what kind of data structures data is stored in.
Basic Structure of the Relational Model
In the everyday world, relations can be compared to Excel spreadsheets. The concepts of the relational model and their comparison to tables are presented in the figure below.
Esimerkki
The relation SUPPLIER below describes suppliers of products. The relation is described in the form of a table, and relation concepts are marked next to it.
Relations can thus mostly be thought of in practice as Excel spreadsheets.
Let's go through all concepts with so-called "official" definitions:
Relation (cf. "table")
 is a pair
is a pair  , which consists of a body
, which consists of a body  , which is a set of tuples (cf. "rows") and a header (cf. "header row")
, which is a set of tuples (cf. "rows") and a header (cf. "header row")  . It is said that " is the header of " and "Attributes of are attributes of ". A relation whose header consists of
. It is said that " is the header of " and "Attributes of are attributes of ". A relation whose header consists of  attributes (cf. " columns") is said to be of degree .
attributes (cf. " columns") is said to be of degree .Attribute (cf. "column") is a pair
 , which consists of an attribute name
, which consists of an attribute name  and a value
and a value  .
.An attribute is a property of a single entity, for example, a single supplier has the attribute
City(attribute name) and its value is "Kalej" (attribute value).If the content of an entity's property is unknown or not relevant, value
is called a null value (often marked as NULL). Considering null values e.g. in storing data and queries is discussed in more detail in Part 4.Header (cf. "table header row") is a set of attribute names related to one relation. The relation header is the names of all attributes of the relation.
Tuple (cf. "table data row") is a set of ordered pairs
") according to header . A single pair consists of an attribute name
according to header . A single pair consists of an attribute name  and its corresponding value
and its corresponding value  .
.Relational Database
 consists of relations and integrity constraints related to them. Integrity constraints are discussed in their own subchapter.
consists of relations and integrity constraints related to them. Integrity constraints are discussed in their own subchapter.
The following auxiliary concepts are also used in the material and in different contexts:
- Relation Schema or Structure of a Relation is a collective name for the relation name and header.
- Relation Body is the set of tuples in the relation. In other words, the relation body is the same as the rows in the table.
- Cardinality of a Relation means the number of tuples stored in it. In other words, how many rows are in the table.
- Cardinality of an Attribute means the number of its different stored values. In other words, how many different values are in the column.
Esimerkki
Let's examine the relation DELIVERY, which describes deliveries made by suppliers.
Let's examine the concepts above through examples:
The relation schema of the relation is:
DELIVERY(supplier_no, part_no, project_no, quantity)In this material, relations are described henceforth mainly only with relation schemas.
The header of the relation is the headers on the table header row, i.e.,
supplier_no,part_no,project_noandquantitytogether are the header.The relation has five tuples i.e. data rows.
For example:
(<supplier_no, 1>; <part_no, 2>; <project_no, 'p123'>; <quantity, 17>)is the tuple corresponding to the first data row. A tuple could be written shorter by omitting attribute names:
(1, 2, 'p123', 17)Every tuple always has four attributes. In the example above
<supplier_no, 1>is an attribute of the first row's tuple, whose name is
supplier_noand value1.The cardinality of attribute
quantityis 5, as there are five distinct values in thequantitycolumn in the relation:17,23,9,4,12.
Core Properties of the Relational Model
From a conceptual point of view, relations and tables are thus somewhat comparable to each other. However, relations differ from tables with the important restrictions below.
According to the relational model, the following core properties apply always to a relation described as a table with degree .
- Every tuple represents a so-called "-tuple" of . In other words, every row has exactly the amount of columns () worth of values (or null values
NULL). - The order of tuples does not matter. In other words, the meaning of the information in the relation does not change even if the rows were mixed into different orders.
- Every tuple is distinguishable from others. In other words, there are no two identical rows in the relation. Instead, there is one or a set of more columns with whose values rows can be distinguished from each other.
- The order of the header does not matter, as long as the connection between a certain attribute name and its value can be unequivocally understood. In other words, the order of columns does not matter, as long as column names correspond to values.
- The meaning of an attribute is evident at least partially from its name. The column name thus tells its meaning.
Esimerkki
Let's return for a moment to the table DELIVERY:
We see that this is a sensible relation:
- Every row has the same amount of values as there are columns. For every column, there is some value on the row.
- The interpretation of delivery information does not change even if the rows were in a different order.
- No row is exactly the same. For example, even though the first two rows have the same
supplier_no, they have a differentpart_no. - The interpretation of delivery information does not change even if the columns were in a different order.
- Values on the row are well understandable based on column names.
What kind of table would not be a good relation then? Here is an example where all rules are broken:
The TOP5_SUPPLIERS relation above does not, however, represent a suitable relation. No property holds for the following reasons:
- Not all rows have values in all columns. The last two rows have a value in the column
quantity, but others do not. If a value is missing or is not relevant, the value in the relation should be a null valueNULL. - It has probably been thought in the table that the supplier's rank in the top 5 list is the location of the supplier's tuple in the table. This is not acceptable in relations, as the position of rows in the table should not matter for the meaning of the information. So there should be some column
rankthat would tell the supplier's position in the top 5 table. - The table has two exactly identical rows that cannot be distinguished from each other.
- The table has two columns named
time. Maybe it has been thought that they would mean a time interval (minimum time, maximum time), but now based on column names they cannot be distinguished from each other. This would be fixed by naming columns more clearly. - Related to the same, it is not completely clear what
timemeans: delivery time in minutes, processing time in hours, or something else. Although this would become clear from the requirements specification or by naming columns more descriptively.
Integrity Constraints
Integrity constraints are an essential part of a relational database: they describe connections between data in different relations and generally define what kind of data can be stored in tuples. More precisely, integrity constraints are various techniques to ensure referential integrity in a relational database. The most important integrity constraints of the relational model are introduced below. Some integrity constraints are database management system specific; they are introduced in more detail in Part 4.
Primary Key
According to the core properties above, every tuple of a relation must be identifiable (i.e., every row should be somehow different in the table). In other words, the relation has a set of one or more attributes with respect to whose value all tuples differ from each other.
An attribute set (with one or more attributes) that identifies relation tuples is called a candidate key (CK). A candidate key must have the following properties:
- A candidate key is unique, i.e., two tuples do not have the same value. A candidate key cannot receive even partially a null value, i.e., no value of an attribute in a candidate key can be
NULL. - A candidate key is indivisible. In other words, none of the attributes belonging to a candidate key can be removed without preserving identifiability. So if one attribute were removed from a candidate key, property 1 could no longer hold true.
From the set of candidate keys, one is chosen as the relation's primary key (PK). A primary key is likewise an attribute set that unequivocally identifies relation tuples. An additional requirement is often attached to a primary key that its value should be immutable for every tuple. However, this is not always possible, and one may have to choose an attribute set whose value may change as a primary key.
In a relation schema, a primary key is usually marked by underlining attributes belonging to the primary key, for example
RELATION(attribute_1, attribute_2, attribute_3)
Esimerkki
Let's examine the relation STUDENT, which describes University of Jyväskylä student information in the student register (cf. Sisu). In its simplicity, the relation schema could be the following:
STUDENT(std_no, ssn, first_name, last_name, postal_code, city)
where std_no is the university's internal student number, ssn the student's social security number, first_name and last_name the student's first and last name, postal_code the student's address postal code and city the student's address city.
Based on the domain, the following candidate keys are found:
{std_no}, as every student has their own student number;{ssn}, as every person has their own social security number and no two different people have the same social security number.
The following attribute sets are not candidate keys:
{std_no, ssn}: although bothstd_noandssnidentify students, either one can be removed and still preserve identifiability (i.e., property 2 does not hold);{first_name},{last_name},{postal_code},{city}or{first_name, last_name}or a similar combination of these: none of these is identifying, i.e., two different students can have the same first name, last name, postal code, city, and a combination of these (i.e., property 1 does not hold);{std_no, first_name},{ssn, last_name}and others similar: again, attributes can be removed from the set and still preserve identifiability.
Of these two, the most sensible choice for a primary key is likely {std_no}. Although {ssn} is unique, it can change for a student.
Generally, it is usually better to choose a candidate key that does not change as a primary key. This cannot always be fully guaranteed; in that case, it may be justified to invent come id attribute, which can be, for example, a sequential number or some randomly generated identifier (see UUID, Snowflake ID, NanoID).
Foreign Key
In domains described by relations, it is common that one entity (e.g., employee) must be able to refer to other entities (e.g., project to which the employee belongs). This reference is usually done by adding attributes of another relation to the relation.
Foreign Key (FK) is an attribute set of relation R, whose values originate from the value set of an attribute or attribute set of some other relation S. In other words, the value set of the foreign key of relation R is a subset of the value set of the attribute set of relation S. The purpose of a foreign key is to enable describing relationships between data in different relations, but at the same time ensure that absurd relationships cannot arise in the database (e.g., ordering a product that does not exist).
A foreign key is usually the primary key of another relation, but in practice, it can be any attribute (set) of another relation. A foreign key can thus consist of one or more attributes. A foreign key can refer to any other relation, also to another attribute of the same relation.
A foreign key can be marked in connection with a relation schema with arrow markings:
R(a, b, c)
S(d, e, a, b)S.a -> R.a
S.b -> R.b
Esimerkki
Finally, let's examine the relation schemas of this chapter together as part of a relational database:
In the relational database schema described above, there are five relation schemas. In the DELIVERY relation, there are three foreign keys, and in the EMPLOYEE relation one. Foreign keys refer to key attributes of other relations.
Finally, let's look at the whole database as tables:
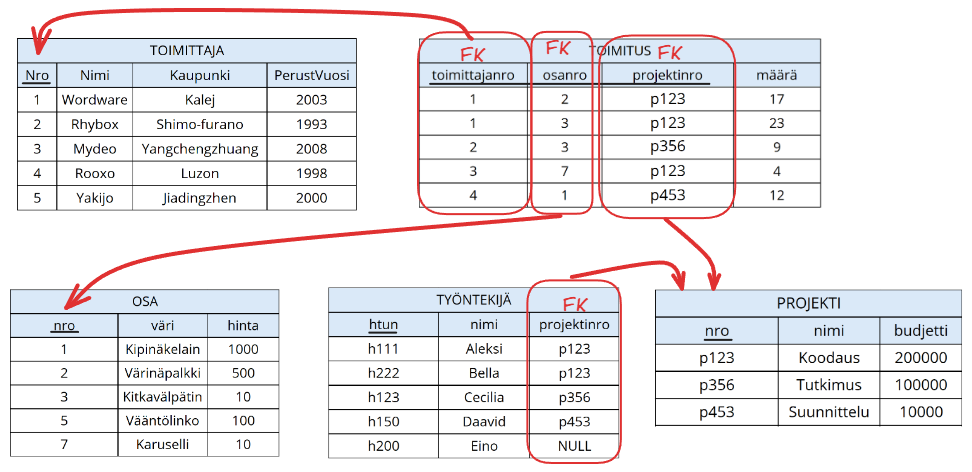
In the figure, attributes belonging to the primary key are underlined, and foreign keys and their relationship to other relations marked with an arrow.
Note especially the following things:
- Attributes of a primary key can also be foreign keys. For example, all attributes belonging to the primary key of the
DELIVERYattribute are at the same time foreign keys to other relations. - Unlike with a primary key, values of attributes belonging to a foreign key can be null values (i.e.
NULL). For example, an employee whoseemp_idish200hasNULLas the value ofproject_no. - Attributes belonging to a foreign key do not need to be unique either. For example, two employees have the same project number (can be interpreted that employees belong to the same project).
- The purpose of a foreign key is to ensure the referential integrity of the database. For example, the database would prevent setting an employee's project number to
p400, as such a project does not exist in the database.
Generally, the DBMS handles checking the referential integrity of foreign keys. DBMSs usually also allow defining how to proceed if changes occur in the referenced relation (e.g., a project with employees is deleted from the database). In principle, a DBMS has three ways to handle changes to tuples to which there are references from other relations:
- The change can be restricted, in which case deleting a tuple or deleting a foreign key value is prevented from the referenced relation.
- If a tuple of the referenced relation is deleted, corresponding foreign key values in the referencing relation are nullified by setting them to
NULL. - The change can be cascaded, in which case tuple values in the referenced relation are changed (if the referenced value changed) or deleted from the relation (if the referenced value was deleted).
We will go into ensuring referential integrity in more detail in Part 4. Let it be mentioned, however, that the DBMS ensures that foreign key values always refer to some existing row somewhere in the database.
Other Integrity Constraints
In addition to primary and foreign keys, more precise and complex constraints can be defined in a relational database, for example:
- An employee's salary must not exceed their supervisor's salary.
- Only a person who is also employed by the department can be a department manager.
- A phone number must start with characters +358.
- An attribute value cannot be a null value.
We will return to defining integrity constraints somewhat in Part 4 when examining defining databases with SQL.
Allowed Data Types
Finally, let it be mentioned that the relational model sets a couple of additional requirements for attribute values. First, only data types that are not multivalued (e.g., lists, arrays, hierarchies) are allowed as attribute values. In other words, the value set of attributes is atomic. Second, an attribute cannot be a reference to another relation (note: can be a reference to an attribute of another relation, as a foreign key is).
A relation that does not meet these requirements is unnormalized. It is possible to fix unnormalized relations by normalizing them. We will return to normalization in more detail in Part 5.
Otherwise, the relational model widely allows different data types. Generally, attributes can be numerical values, strings, time information, boolean values, or raw binary data. In Part 4, we will get to know different allowed data types more closely with the help of SQL.
Relaatiomallien teoreettinen perusta
Relaatiomalli on Edgar F. Coddin kirjoittama, vuonna 1970 julkaistu teoria [6], joka muodostaa relaatiotietokantojen teoreettisen perustan. Mallin taustalla oleva teoria perustuu joukko-oppiin ja on vahva verrattuna muihin tietokantaparadigmoihin. Tässä materiaalissa relaatiotietokannan perusteoriaa lähestytään esimerkein ja vertaamalla sitä tuttuihin käsitteisiin. Materiaalissa ei syvennytä teorian yksityiskohtiin, kuten relaatioalgebraan – tästä kiinnostuneet voivat tutustua Coddin [6] alkuperäiseen kirjoitukseen.
Relaatiomalli on loogisen tason tietomalli: se kuvaa millaisiin tietorakenteisiin tietoa tallennetaan.
Relaatiomallin perusrakenne
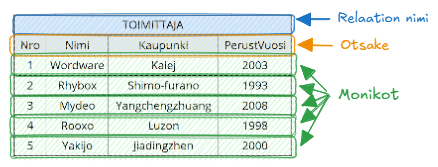
Arkimaailmassa relaatiot voi verrata Excel-taulukoihin. Relaatiomallin käsitteet ja niiden vertautuminen taulukkoihin on esitetty alla olevassa kuvassa.
Esimerkki
Alla oleva relaatio TOIMITTAJA kuvastaa tuotteiden toimittajia. Relaatio on kuvattu taulukon muodossa, ja viereen on merkitty relaatioiden käsitteitä.
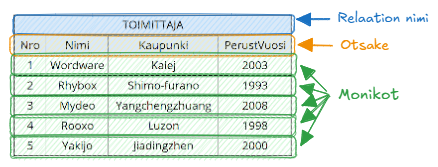
Relaatiot voi siis useimmiten ajatella käytännössä Excel-taulukoina.
Käydään vielä kaikki käsitteet läpi niin sanotuin "virallisin" määritelmin:
Relaatio (relation, vrt. "taulukko")
on pari , joka koostuu sisällöstä (body) , joka on joukko monikoita (vrt. "rivejä") sekä otsakkeesta (vrt. "otsikkorivistä") . Sanotaan, että " on :n otsake" ja ":n attribuutit ovat :n attribuutteja". Relaation, jonka otsake koostuu kappaleesta attribuutteja (vrt. " kappaleesta sarakkeita"), sanotaan olevan asteluvultaan (degree) .Attribuutti (attribute, vrt. "sarake") on pari
, joka koostuu attribuutin nimestä ja arvosta .Attribuutti on yksittäisen kohteen ominaisuus, esimerkiksi yksittäisellä toimittajalla on attribuutti
Kaupunki(attribuutin nimi) ja sen arvo on "Kalej" (attribuutin arvo).Jos kohteen ominaisuuden sisältöä ei tunneta tai se ei ole merkityksellinen, arvoa
kutsutaan tyhjäarvoksi (merkitään usein NULL). Tyhjäarvon huomioiminen esim. tietojen tallentamisessa ja kyselyissä käsitellään tarkemmin materiaalin osassa 4.Otsake (header, vrt. "taulukon otsikkorivi") on yhteen relaatioon liittyvä joukko attribuuttien nimiä. Relaation otsake on relaation kaikkien attribuuttien nimet.
Monikko (tuple, vrt. "taulukon tietorivi") on otsakkeen
mukainen joukko järjestettyjä pareja . Yksittäinen pari koostuu attribuutin nimestä ja sitä vastaavasta arvosta .Relaatiotietokanta
koostuu relaatioista sekä niihin liittyvistä eheysrajoitteista. Eheysrajoitteet käsitellään omassa alaluvussa.
Materiaalissa ja eri yhteyksissä käytetään myös seuraavia apukäsitteitä:
- Relaatiokaava tai relaation rakenne on yhteisnimitys relaation nimelle ja otsakkeelle.
- Relaation sisältö on relaatiossa olevien monikkojen joukko. Toisin sanoin, relaation sisältö on sama kuin taulukossa olevat rivit.
- Relaation kardinaalisuus tarkoittaa siihen tallennettujen monikoiden lukumäärää. Toisin sanoin, kuinka monta riviä taulukossa on.
- Attribuutin kardinaalisuus tarkoittaa sen erilaisten tallennettujen arvojen lukumäärää. Toisin sanoin, kuinka monta eri arvoa sarakkeessa on.
- Attribuutin arvojoukko on joukko, attribuutin kaikista mahdollisista arvoista. Esimerkiksi
määrä-attribuutin arvojoukko voisi olla positiiviset kokonaisluvut.
Esimerkki
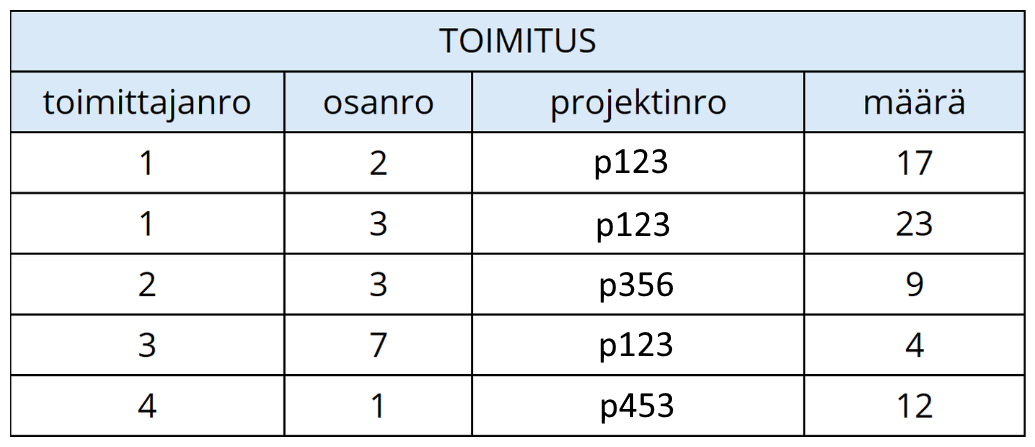
Tarkastellaan relaatiota TOIMITUS, joka kuvastaa toimittajien tekemiä toimituksia.
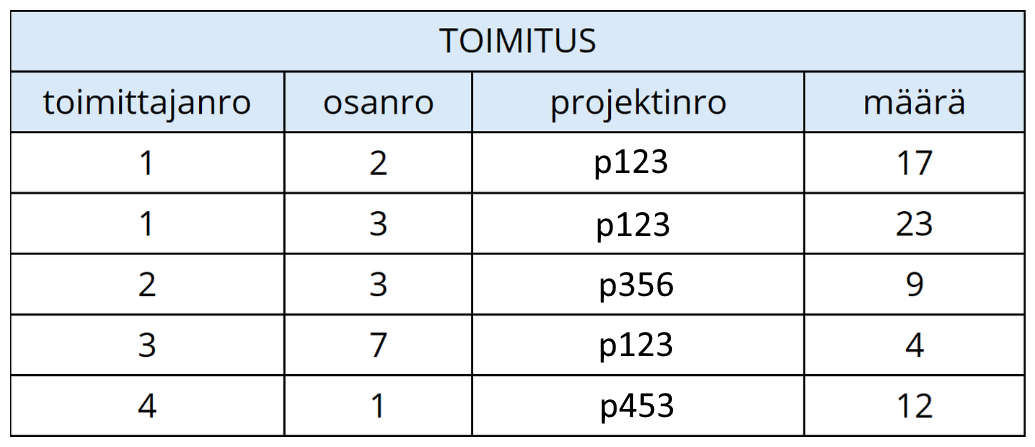
Tarkastellaan yllä olevia käsitteitä esimerkkien kautta:
Relaation relaatiokaava on:
TOIMITUS(toimittajanro, osanro, projektinro, määrä)Tässä materiaalissa relaatiot kuvataan jatkossa pääosin vain relaatiokaavoilla.
Relaation otsake on taulukon otsikkorivillä olevat otsikot, eli
toimittajanro,osanro,projektinrosekämääräovat yhdessä otsake.Relaatiossa on viisi monikkoa eli tietoriviä.
Esimerkiksi:
(<toimittajanro, 1>; <osanro, 2>; <projektinro, 'p123'>; <määrä, 17>)on ensimmäistä tietoriviä vastaava monikko. Monikon voisi kirjoittaa lyhyemmin jättämällä pois attribuuttien nimet:
(1, 2, 'p123', 17)Jokaisella monikolla on aina neljä attribuuttia. Yllä olevassa esimerkissä
<toimittajanro, 1>on ensimmäisen rivin monikon attribuutti, jonka nimi on
toimittajanroja arvo1.Attribuutin
määräkardinaalisuus on 5, sillä relaatiossa sarakkeessamääräon viisi erillistä arvoa:17,23,9,4,12.
Relaatiomallin ydinominaisuudet
Käsitteiden kannalta relaatiot ja taulukot ovat siis jotenkin verrattavissa toisiinsa. Relaatiot poikkeavat kuitenkin taulukoista alla olevilla tärkeillä rajoituksilla.
Relaatiomallin mukaan taulukkona kuvatulle, asteluvultaan olevalle relaatiolle pätevät aina seuraavat ydinominaisuudet.
- Jokainen monikko edustaa :n ns. "-monikkoa". Toisin sanoin, jokaisella rivillä on tasan sarakkeiden määrän () verran arvoja (tai tyhjäarvoja
NULL). - Monikoiden järjestyksellä ei ole merkitystä. Toisin sanoin, relaatiossa olevan tiedon merkitys ei muutu vaikka rivit sekoitettaisiin eri järjestyksiin.
- Jokainen monikko on erotettavissa toisistaan. Toisin sanoin, relaatiossa ei ole kahta samanlaista riviä. Sen sijaan on olemassa yksi tai joukko useampia sarakkeita, joiden arvoilla rivit voidaan erotella toisistaan.
- Otsakkeen järjestyksellä ei ole merkitystä, kunhan tietyn attribuutin nimen ja sen arvon yhteys voidaan yksiselitteisesti ymmärtää. Toisin sanoin, sarakkeiden järjestyksellä ei ole merkitystä, kunhan sarakkeiden nimet vastaavat arvoja.
- Attribuutin merkitys käy ainakin osittain ilmi sen nimestä. Sarakkeen nimi siis kertoo sen merkityksen.
Esimerkki
Palataan hetkeksi vielä tauluun TOIMITUS:
Nähdään, että tämä on järkevä relaatio:
- Jokaisella rivillä on saman verran arvoja kuin on sarakkeita. Jokaiselle sarakkeelle löytyy rivillä jokin arvo.
- Toimitustietojen tulkinta ei muutu, vaikka rivit olisivat eri järjestyksessä.
- Mikään rivi ei ole täysin samanlainen. Esimerkiksi vaikka kahdella ensimmäisellä rivillä on sama
toimittajanro, niillä on eriosanro. - Toimitustietojen tulkinta ei muutu, vaikka sarakkeet olisivat eri järjestyksessä.
- Rivillä olevat arvot ovat hyvin ymmärrettävissä sarakkeiden nimien perusteella.
Millainen taulu ei olisi siis hyvä relaatio? Tässä esimerkki, jossa kaikki säännöt on rikottu:
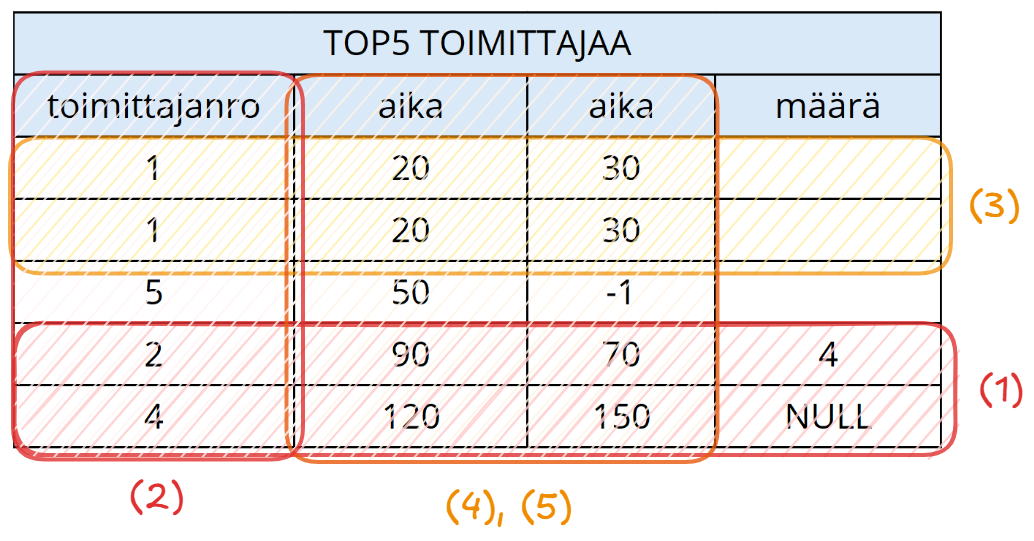
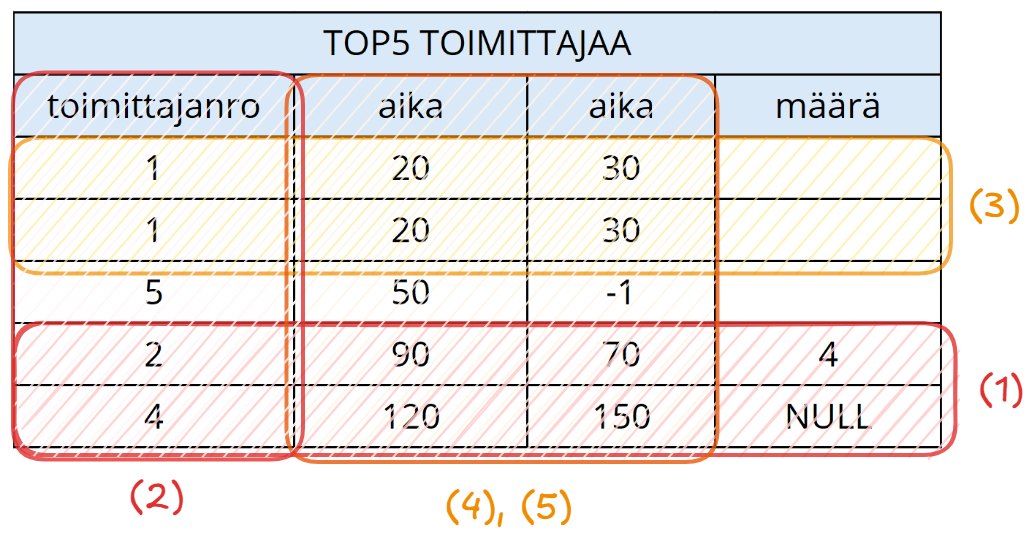
Yllä oleva TOP5_TOIMITTAJAA-relaatio ei kuitenkaan edusta sopivaa relaatiota. Mikään ominaisuus ei siis päde seuraavista syistä:
- Kaikilla riveillä ei ole kaikissa sarakkeissa arvoja. Kahdella viimeisellä rivillä on sarakkeessa
määräarvo, mutta muilla ei ole. Jos arvo puuttuu tai se ei ole merkityksellinen, relaatiossa arvon tulee olla tyhjäarvoNULL. - Taulussa on varmaan ajateltu, että toimittajan sija top 5 -listassa on toimittajan monikon sijainti taulussa. Tämä ei relaatioissa kelpaa, sillä rivien sijainnilla taulussa ei pitäisi olla merkitystä tiedon merkityksen kannalta. Pitäisi siis olla jokin sarake
sija, joka kertoisi toimittajan sijainnin top 5 -taulussa. - Taulussa on kaksi täysin samaa riviä, joita ei voi erottaa toisistaan.
- Taulussa on kaksi
aika-nimistä saraketta. Ehkä on ajateltu, että ne tarkoittaisivat aikaväliä (minimiaika, maksimiaika), mutta nyt sarakkeiden nimen perusteella niitä ei voi erotella toisistaan. Tämä korjaantuisi nimeämällä sarakkeet selkeämmin. - Samaan liittyen ei ole täysin selvää, mitä
aikatarkoittaa: toimitusaikaa minuutteina, käsittelyaikaa tunteina vai jotain muuta. Tosin tämä selviäisi vaatimusmäärittelystä tai nimeämällä sarakkeet kuvaavammin.
Eheysrajoitteet
Eheysrajoitteet ovat olennainen osa relaatiotietokantaa: niillä kuvataan eri relaatioissa olevan datan välisiä yhteyksiä sekä yleisesti määritellään, millaista dataa monikoissa voidaan säilyttää. Tarkemmin sanottuna, eheysrajoitteet (integrity constraint) ovat erilaisia tekniikoita viite-eheyden varmistamiseksi relaatiotietokannassa. Relaatiomallin tärkeimmät eheysrajoitteet esitellään alla. Jotkin eheysrajoitteet ovat tietokantahallintajärjestelmäkohtaisia; niitä esitellään tarkemmin osassa 4.
Perusavain
Yllä olevien ydinominaisuuksien mukaan relaation jokaisen monikon tulee olla yksilöitävissä (eli jokaisen rivin pitäisi olla taulussa jollain tapaa erilainen). Toisin sanoin, relaatiolla on yhden tai usean attribuutin joukko, jonka arvon suhteen kaikki monikot eroavat toisistaan.
Attribuuttijoukko (jossa yksi tai useampi attribuutti), joka yksilöi relaation monikot, on nimeltään avainehdokas (candidate key, CK). Avainehdokkaalla tulee olla seuraavat ominaisuudet:
- Avainehdokas on yksilöivä, eli kahdella monikolla ei ole samaa arvoa. Avainehdokas ei voi saada edes osittain tyhjäarvoa, eli mikään avainehdokkaassa olevan attribuutin arvo voi olla
NULL. - Avainehdokas on jakamaton. Toisin sanoin, avainehdokkaaseen kuuluvista attribuuteista yhtäkään ei voi poistaa ilman, että yksilöitävyys säilyy. Eli jos avainehdokkaasta ottaisi pois jonkin attribuutin, ominaisuus 1. ei enää voisi pitää paikkaansa.
Avainehdokkaiden joukosta valitaan yksi relaation perusavaimeksi (primary key, PK). Perusavain on niin ikään jakamaton attribuuttijoukko, joka yksiselitteisesti yksilöi relaation monikot. Perusavaimen tarkoitus on varmistaa kohde-eheys, eli että relaation jokainen monikko on yksilöitävissä epätyhjien arvojen avulla.
Perusavaimeen usein liitetään lisävaatimus, että sen arvon tulisi olla jokaisella monikolla muuttumaton. Aina tämä ei kuitenkaan ole mahdollista, ja perusavaimeksi voidaan joutua valitsemaan sellainen attribuuttijoukko, jonka arvo saattaa muuttua.
Relaatiokaavassa perusavain yleensä merkitään alleviivaamalla perusavaimeen kuuluvat attribuutit, esimerkiksi
RELAATIO(attribuutti_1, attribuutti_2, attribuutti_3)
Esimerkki
Tarkastellaan relaatiota OPISKELIJA, joka kuvastaa Jyväskylän yliopiston opiskelijan tietoja opiskelijarekisterissä (vrt. Sisu). Relaation kaava voisi yksinkertaisuudessaan olla seuraava:
OPISKELIJA(opnro, hetu, etunimi, sukunimi, postinumero, paikkakunta)
missä opnro on yliopiston sisäinen opiskelijanumero, hetu opiskelijan henkilötunnus, etunimi ja sukunimi opiskelijan etu- ja sukunimi, postinumero opiskelijan osoitteen postinumero ja paikkakunta opiskelijan osoitteen paikkakunta.
Kohdealueen perusteella löydetään seuraavat avainehdokkaat:
{opnro}, sillä jokaisella opiskelijalla on oma opiskelijanumero;{hetu}, sillä jokaisella henkilöllä on oma henkilötunnus eikä kahdella eri ihmisellä ole samaa henkilötunnusta.
Seuraavat attribuuttijoukot eivät ole avainehdokkaita:
{opnro, hetu}: vaikka sekäopnrosekähetuyksilöivät opiskelijat, jommankumman voidaan poistaa ja silti säilyttää yksilöitävyys (eli siis ominaisuus 2 ei päde);{etunimi},{sukunimi},{postinumero},{paikkakunta}tai{etunimi, sukunimi}tai vastaava näiden yhdistelmä: mikään näistä ei ole yksilöivä, eli kahdella eri opiskelijalla voi olla sama etunimi, sukunimi, postinumero, paikkakunta sekä näiden yhdistelmä (eli ominaisuus 1 ei päde);{opnro, etunimi},{hetu, sukunimi}ja muut vastaavat: taas, joukosta voidaan poistaa attribuutteja ja silti säilyttää yksilöitävyys.
Näistä kahdesta järkevin valinta perusavaimeksi lienee {opnro}. Vaikka {hetu} on yksilöllinen, se voi opiskelijalla muuttua.
Yleisesti perusavaimeksi on yleensä parempi valita sellainen avainehdokas, joka ei vaihdu. Aina tätä ei voida täysin taata; siinä tapauksessa voi olla perusteltua keksiä jokin id-attribuutti, joka voi olla esimerkiksi juokseva numero tai jokin satunnaisesti muodostettu tunniste (ks. UUID, Snowflake ID, NanoID).
Viiteavain
Relaatioiden kuvaamissa kohdealueissa on tavallista, että yhden kohteen (esim. työntekijä) on pystyttävä viittaamaan toisiin kohteisiin (esim. projekti, johon työntekijä kuuluu). Tämä viittaus tehdään tavallisesti lisäämällä relaatioon toisen relaation attribuutteja.
Viiteavain (foreign key, FK) on relaation R attribuuttijoukko, jonka arvot ovat peräisin jonkin toisen relaation S attribuutin tai attribuuttijoukon arvojoukosta. Toisin sanoen relaation R viiteavaimen arvojoukko on relaation S attribuuttijoukon arvojoukon osajoukko. Viiteavaimen tarkoitus on mahdollistaa eri relaatioiden datan välisten suhteiden kuvaamista, mutta samalla varmistaa, ettei tietokantaan voi syntyä järjettömiä suhteita (esim. tilataan tuotetta, jota ei ole olemassa).
Viiteavain on yleensä toisen relaation perusavain, mutta se käytännössä voi olla mikä vaan toisen relaation attribuutti(joukko). Viiteavain voi siis koostua yhdestä tai useasta attribuutista. Viiteavain voi viitata mihin tahansa toiseen relaatioon, myös saman relaation toiseen attribuuttiin.
Viiteavain voidaan merkitä relaatiokaavan yhteydessä nuolimerkinnöillä:
R(a, b, c)
S(d, e, a, b)S.a -> R.a
S.b -> R.b
Esimerkki
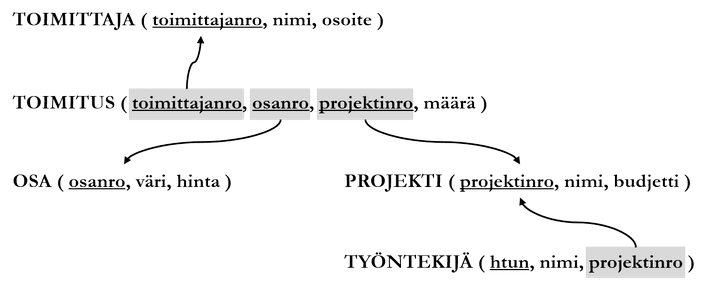
Tarkastellaan lopuksi tämän luvun relaatiokaavat yhdessä osana relaatiotietokantaa:
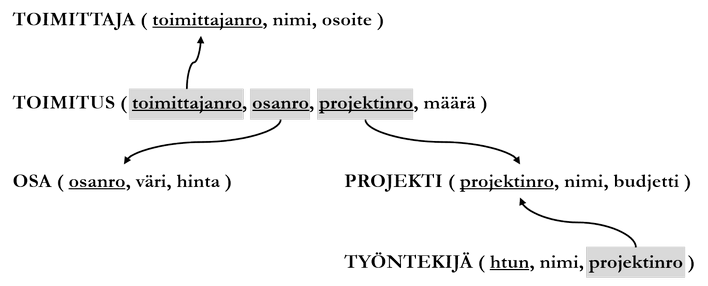
Yllä kuvatussa relaatiotietokannan kaavassa on viisi relaatiokaavaa. TOIMITUS-relaatiossa on kolme viiteavainta, ja TYÖNTEKIJÄ-relaatiossa yksi. Viiteavaimet viittaavat toisten relaatioiden avainattribuutteihin.
Katsotaan lopuksi vielä koko tietokanta tauluina:
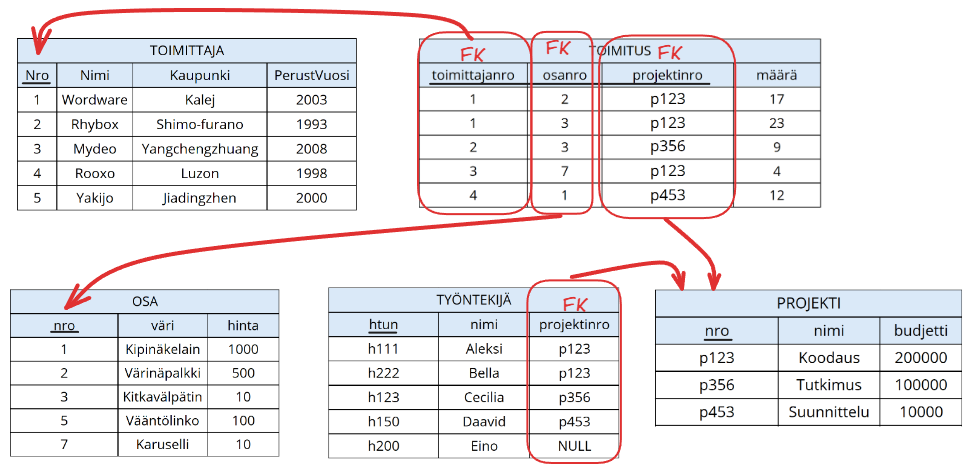
Kuvassa perusavaimeen kuuluvat attribuutit ovat alleviivattu, ja viiteavaimet sekä niiden suhde toisiin relaatioihin merkitty nuolella.
Huomaa erityisesti seuraavat asiat:
- Perusavaimen attribuutit voivat olla myös viiteavaimia. Esimerkiksi
TOIMITUS-attribuutin kaikki perusavaimeen kuuluvat attribuutit ovat samalla viiteavaimet toisiin relaatioihin. - Toisin kuin perusavaimella, viiteavaimeen kuuluvien attribuuttien arvot voivat olla tyhjäarvoja (eli
NULL). Esimerkiksi työntekijällä, jonkahtunonh200, onprojektinro:n arvonaNULL. - Viiteavaimeen kuuluvien attribuuttien ei tarvitse olla myöskään yksilöiviä. Esimerkiksi kahdella työntekijällä on sama projektinumero (voidaan tulkita, että työntekijät kuuluvat samaan projektiin).
- Viiteavaimen tarkoitus on varmistaa tietokannan viite-eheys. Esimerkiksi tietokanta estäisi asettamasta työntekijän projektinumeroksi
p400, sillä sellaista projektia ei ole tietokannassa olemassa.
Yleisesti DBMS hoitaa viiteavainten viite-eheyden tarkistamista. DBMS:t yleensä antavat myös määrittää, miten menetellään, jos viitatussa relaatiossa tapahtuu muutoksia (esim. projekti, jossa on työntekijöitä, poistetaan tietokannasta). Lähtökohtaisesti DBMS:llä on kolme tapaa käsitellä muutoksia monikkoihin, joihin on viittauksia toisista relaatioista:
- Muutos voidaan estää (restriction), jolloin monikon poistaminen tai viiteavaimen arvon poistaminen estetään viitatusta relaatiosta.
- Jos viitatun relaation monikko poistetaan, tyhjätään (nullification) viittaavassa relaatiossa vastaavat viiteavaimen arvot asettamalla ne
NULL:ksi. - Muutos voidaan vyöryttää (cascading), jolloin viitatussa relaatiossa olevia monikon arvoja muutetaan (jos viitattu arvo muuttui) tai poistetaan relaatiosta (jos viitattu arvo poistettiin).
Tarkemmin viite-eheyden varmistamiseen mennään osassa 4. Mainittakoon kuitenkin, että DBMS varmistaa, että viiteavaimen arvot viittaavat aina johonkin olemassa olevaan riviin jossain tietokannassa.
Muut eheysrajoitteet
Perus- ja viiteavainten lisäksi relaatiotietokantaan voidaan määritellä tarkempia ja monimutkaisempia rajoitteita, esimerkiksi:
- Työntekijän palkka ei saa ylittää esimiehensä palkkaa.
- Osaston johtajana voi olla vain sellainen henkilö, joka on samalla työsuhteessa osastoon.
- Puhelinnumeron tulee alkaa merkeillä +358.
- Attribuutin arvona ei saa olla tyhjäarvo.
Eheysrajoitteiden määrittelyyn palataan jonkin verran osassa 4, kun tarkastellaan tietokantojen määrittämistä SQL-kielellä.
Muut hyödylliset käsitteet
Avainten yhteydessä on lisäksi seuraavia käsitteitä, joita saattaa ilmaantua kirjallisuudessa tai arkikielessä:
- Superavain (superkey, SK): mikä tahansa attribuuttijoukko, joka sisältää ainakin yhden avainehdokkaan. Toisin sanoen, superavain yksilöi monikot, mutta ei ole välttämättä jakamaton. Avainehdokas on siten aina superavain, mutta superavain ei ole välttämättä avainehdokas.
- Yhdistelmäavain (composite key): avain(ehdokas), joka koostuu useammasta kuin yhdestä attribuutista.
- Sijaisavain (surrogate key): keinotekoisesti keksitty perusavain, joka ei varsinaisesti vastaa mitään relaation luonnollista ominaisuutta. Esimerkiksi juokseva
id-numero, UUID-numero tai vastaava. - Johdettu avain (derived key): avain, joka ei ole attribuutti relaatiossa.
Sallitut tietotyypit
Lopuksi mainittakoon, että relaatiomalli asettaa pari lisävaatimusta attribuuttien arvoihin. Ensinnäkin, attribuutin arvoiksi sallitaan vain sellaiset tietotyypit, jotka eivät ole moniarvoisia (esim. listat, taulukot, hierarkiat). Toisin sanoin, attribuuttien arvojoukko on atominen. Toiseksi, attribuutti ei voi olla viittaus toiseen relaatioon (huom: voi olla viittaus toisen relaation attribuuttiin, kuten viiteavain on).
Relaatio, joka ei täytä näitä vaatimuksia, on normalisoimaton. Normalisoimattomia relaatioita on mahdollista korjata normalisoimalla ne. Normalisointiin palataan tarkemmin osassa 5.
Muuten relaatiomalli sallii laajasti erilaisia tietotyyppejä. Yleisesti attribuutit voivat olla lukuarvoja, merkkijonoja, aikatietoja, totuusarvoja tai raakaa binääridataa. Osassa 4 tutustumme tarkemmin SQL:n avulla erilaisiin sallittuihin tietotyyppeihin.
These are the current permissions for this document; please modify if needed. You can always modify these permissions from the manage page.