ITKA2004 Tietokannat ja tiedonhallinta
// Toni Taipalus (päivitetty 8.1.2021)
1. Johdanto
Tässä luvussa esitellään materiaalissa käytettyjä peruskäsitteitä ja määritelmiä sekä tietokantojen historiaa.
1.1 Peruskäsitteitä ja määritelmiä
Tähän alalukuun on kerätty yleisiä tietokantoihin ja tiedonhallintaan liittyviä käsitteitä. Aihealuekeskeisemmät käsitteet on määritelty niitä koskevissa luvuissa. Määritelmät perustuvat Elmasrin & Navathen (2007) esitykseen.
1.1.1 Tietomalli
Tietomalli (data model) on abstrakti määritelmä tietorakenteista (kuten relaatio), operaatioista (kuten liitos) ja niihin liittyvistä, mallin kannalta tärkeistä käsitteistä. Esimerkiksi relaatio- tai verkkomalli ovat tietomalleja. Tietomallista, jota käytetään tietokannassa, käytetään myös nimitystä tietokantaparadigma.
Tietomallit voidaan edelleen jakaa kolmeen ryhmään:
- käsitteellisiin, joiden avulla datan koostavat osat esitetään ylimmällä tasollaan,
- loogisiin, joiden avulla data kuvataan ilman yhteyttä fyysiseen toteutukseen ja
- fyysisiin, joiden avulla data koostetaan esim. levylohkoista ja muistisivuista.
Alaluvussa 2.2 esitellään ER-malli, joka on käsitteellisen tason tietomalli, ja luvussa 3 relaatiomalli, joka on loogisen tason tietomalli. Fyysisiä tietomalleja tässä materiaalissa ei juuri käsitellä.
1.1.2 Tietue
Tietue (mm. record) on rakeisuudeltaan määrittelemätön kokonaisuus dataa ja mahdollisesti myös datan rakennetta. Tietue voi olla esimerkiksi relaatiotietokannassa tietokanta, relaatio, relaation attribuutti tai relaation attribuutin ja monikon leikkauskohta.
1.1.3 Tietokanta
Tietokanta (database) on yleisellä tasolla kokoelma toisiinsa liittyvää dataa. Tavallisesti kuitenkin tietokannasta puhuttaessa tarkoitetaan tietokantaa, jolla seuraavat ominaisuudet:
- Tietokanta kuvastaa jotakin osaa reaalimaailmasta. Jos reaalimaailman siinä osassa, jota tietokanta kuvaa tapahtuu muutoksia, muutokset heijastuvat myös tietokantaan.
- Tietokanta on loogisesti yhtenäinen kokoelma dataa, ja tällä datalla on luontainen merkitys. Satunnainen osajoukko tietokannan datasta ei ole tietokanta.
- Tietokannan rakenne ja data on suunniteltu ja toteutettu tiettyä tarkoitusta varten, ja tietokannalla on harkittu käyttäjäryhmä ja sovellusohjelma.
1.1.4 Tietokannanhallintajärjestelmä
Tietokannanhallintajärjestelmä (Database Management System, DBMS) on ohjelmisto, joka mahdollistaa tietokannan rakenteen määrittämisen, datan etsimisen, lisäämisen, poistamisen ja muokkaamisen sekä tietokannan suojaamisen, ylläpidon ja jakamisen eri sovellusohjelmille ja käyttäjille. Tietokannanhallintajärjestelmän datan etsimiseen liittyviä komponentteja tarkastellaan tarkemmin alaluvussa 2.1.
Tietokannanhallintajärjestelmä noudattaa jotakin tietomallia. Joskus tietokannanhallintajärjestelmää kutsutaan tarkemmin esim. relaatiotietokannanhallintajärjestelmäksi, oliotietokannanhallintajärjestelmäksi tai dokumenttitietokannanhallintajärjestelmäksi sen noudattaman tietomallin mukaan.
1.1.5 Tietokantajärjestelmä
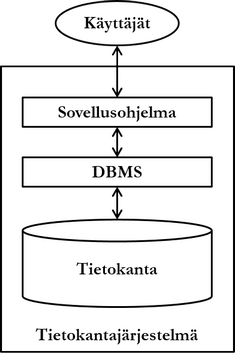
Tietokantajärjestelmä (database system) on tietokannan, tietokannanhallintajärjestelmän ja niitä käyttävän sovellusohjelman yhteisnimitys. Tietokantajärjestelmä sisältää kaikkia mainittuja osiaan yhden tai useampia.
1.1.6 Tiedonhallinta
Tiedonhallinta (data management) on sitä kehitystyötä, käyttöä ja valvontaa, joka pyrkii datan ja informaation hallintaan, suojaamiseen, jakamiseen ja arvon nostamiseen (Mosley et al. 2010).
- Data on merkityksetöntä raakatietoa kuten numeroita, tekstiä, symboleita, kuvia, ääntä tai videota.
- Informaatio on dataa jossakin kontekstissa. Ilman kontekstia ja sen tulkintaa data on merkityksetöntä (meaningless).
- Tietämys (knowledge) on informaatiota tietystä perspektiivistä. Perspektiivi tuo informaatiolle merkityksellisyyden (significance).
- Dataa, informaatiota ja tietämystä kutsutaan yleisesti tiedoksi silloin, kun ei ole tarpeen tehdä eroa niiden erityispiirteiden välillä.
1.2 Tietokantojen historia
Tässä alaluvussa käsitellään lyhyesti tietokantojen ja niihin liittyvien tuotteiden, tapahtumien ja tutkimusten historiaa 1960-luvulta nykypäivään.
1.2.1 1960- ja 1970-luku
Ennen 1960-lukua dataa hallitaan tiedostojärjestelmän avulla. Data on tallennettuna tiedostoihin (flat file), joilla on hyvin yksinkertainen rakenne, mikä saa aikaan huomattavasti datan toistoa. Kehitystä ajavat erityisesti seuraavat nousevat tarpeet:
- Halutaan erottaa sovellusohjelmat datasta.
- Halutaan mallintaa monimutkaisempia tietotyyppejä ja tietorakenteita.
- Halutaan helpottaa ja nopeuttaa datan saantia.
1960-luvulla esitellään ensimmäiset tietokannanhallintajärjestelmät kuten General Electronicsin Integraded Data Store. Ne ovat suunniteltuja suurten datamäärien käsittelyyn monimutkaisissa ympäristöissä. 1960-luvun lopulla perustetaan Data Base Task Group, jonka ensisijaisena tehtävänä on standardisoida tietokanta.
1970-luvulla tietokannanhallintajärjestelmät saavuttavat kaupallista menestystä. Uusia ja suosiota saavuttavia tietokantaparadigmoja ovat 1970-luvulla erityisesti hierarkkiset, kuten IBM:n Information Management System ja verkkotietokannat (network database). Hierarkkisia ja verkkotietokantoja kritisoidaan erityisesti seuraavista puutteista:
- Yksinkertaisenkin datan saantiin vaaditaan monimutkainen sovellusohjelma.
- Sovellusohjelmat eivät ole tarpeeksi erotettuja datasta.
- Sovellusohjelma on ainoa tapa päästä tarkastelemaan dataa.
- Datan käsitteellinen, looginen ja fyysinen rakenne on vahvasti yhteen liitetty.
Vuonna 1970 IBM:llä työskentelevä Edgar F. Codd esittelee relaatiomallin, joka on loogisen tason tietomalli. Vuonna 1976 Peter Chen esittelee formalisoimansa ER-mallin (Entity-Relationship model), joka on käsitteellisen tason tietomalli. IBM:llä kehitetään myös yrityksen omassa käytössä olevaan tietokannanhallintajärjestelmään, System R:ään yhteensopiva kyselykieli SEQUEL (Structured English Query Language) datan etsimiseen ja käsittelyyn.
IBM:n lisäksi ICT-alan yritys nimeltä Relational Software, Inc. (RSI) havaitsee relaatiomallin potentiaalin ja kehittää kyselykieli SEQUEL:iin perustuvan relaatiotietokannanhallintajärjestelmän. RSI:n kyselykielen nimeksi tulee SQL (Structured Query Language) ja tietokannanhallintajärjestelmän nimeksi Oracle. Toisin kuin System R, Oracle on kaupallinen tuote.
1.2.2 1980- ja 1990-luku
1980-luvulla relaatiotietokannanhallintajärjestelmät, erityisesti Berkeleyn yliopiston Ingres, RSI:n Oracle, IBM:n DB/2 ja Sybasen SQL Server saavuttavat suosiota tarjotessaan ratkaisuja hierarkkisten ja verkostotietokantojen puutteisiin. Vuonna 1983 RSI muuttaa nimensä Oracle Corporationiksi. Ingresin kyselykieli on muista tuotteista poiketen QUEL, mutta SQL:n saavuttaessa yhä suurempaa suosiota Ingres joutuu vaihtamaan kyselykieltään. Vaihto ja Oraclen markkinointi pudottavat Ingresin markkinoiden kärkisijoilta.
Vuonna 1984 yhdysvaltalainen Teradata julkaisee saman nimisen tietokannanhallintajärjestelmän, jota yleisesti pidetään ensimmäisenä modernina tietovarastointia tukevana järjestelmänä. Ralph Kimball perustaa Red Brick Systemsin vuonna 1986.
Vuonna 1986 julkaistaan SQL1-standardi ja vuonna 1989 täydennetty SQL-standardi. Vuonna 1989 Malcolm Atkinson et al. julkaisevat oliotietokantojen manifestin.
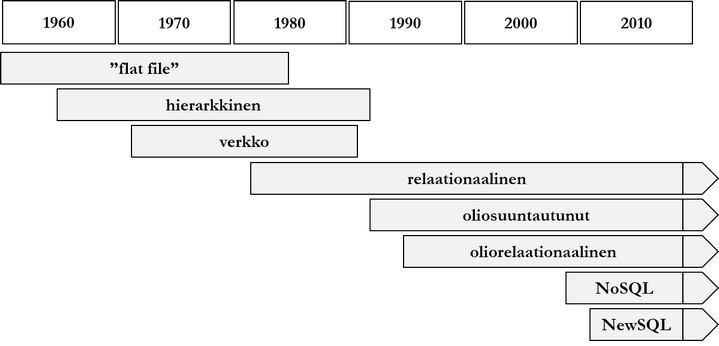
1990-luvulla ohjelmistot kokevat suuria muutoksia: asiakas-palvelin-arkkitehtuuri ja internet-pohjaiset sovellukset tulevat yhä suositummaksi. Tietovarastointi saavuttaa organisaatioissa nopeasti kasvavaa suosiota Bill Inmonin kirjan (1992) myötä. Vapaan lähdekoodin MySQL- ja PostgreSQL-relaatiotietokannanhallintajärjestelmät saavuttavat yhä suurempaa suosiota.
Vuonna 1992 julkaistaan SQL2-standardi ja vuonna 1999 SQL3-standardi (SQL:1999), joka lisää erityisesti ohjelmointia helpottavia ominaisuuksia kuten triggerit, proseduurit, funktiot ja SQL:n upottamisen isäntäkieleen. Standardin uusi versio määrittelee myös oliokeskeisten sovellusohjelmien ja relaatiotietokantojen välisen rajapinnan. Nousevaa hybridiparadigmaa kutsutaan oliorelaationaaliseksi.
Oliosuuntautunut tietokantaparadigma ja tietokannanhallintajärjestelmät kuten Gemstone saavuttavat suosiota, joka on kuitenkin relaatioparadigmaan verrattuna vähäistä. Suosittuihin kaupallisiin relaatiotietokannanhallintajärjestelmiin kuten Oracle lisätään oliorelaationaalisia ominaisuuksia. Oliorelaatiomalliin perustuvia tuotteita, kuten IBM:n Informix ilmestyy markkinoille.
1.2.3 2000- ja 2010-luku
2000-luvulla kasvava datan ja käyttäjien määrä vaatii tietokannoilta yhä voimakkaammin hajautusta: yhdessä laitteessa ei riitä joko suorituskyky tai tallennuskapasiteetti tai kumpikaan käyttäjien tietotarpeille. Pilvipalvelut yleistyvät ja tietokannanhallintajärjestelmiin lisätään hajautusta tukevia ominaisuuksia.
SQL-standardista julkaistaan uusia versioita 2003, 2006, 2008 ja 2011 jotka lisäävät erityisesti ominaisuuksia World Wide Web Corsortiumin (W3C) standardisoimien XML-dokumenttien (Extensible Markup Language) ja XQuery-kyselykielen integrointiin. Vuonna 2009 Oracle Corporation ostaa oikeudet vapaan lähdekoodin MySQL:ään. Yhteisön kehittämän, MySQL:stä haarautuneen tietokannanhallintajärjestelmän nimeksi tulee MariaDB.
Räjähdysmäistä suosiota saavuttavat, internet-yhteyttä käyttävät erilaiset mobiililaitteet esittelevät uusia haasteita myös tietokannoille. Erittäin suuret internetissä toimivat yritykset kuten Google, Facebook ja Amazon havaitsevat relaatiotietokannanhallintajärjestelmät tarpeisiinsa nähden tehottomiksi. Uusien tietokantaparadigmojen nousua ajavat eteenpäin erityisesti seuraavat relaatiotietokannanhallintajärjestelmissä havaitut ongelmat:
- Tietokannat eivät skaalaudu tehokkaasti suuriin määriin dataa.
- Tietokannat eivät skaalaudu tehokkaasti suuriin määriin käyttäjiä.
- Tietokantojen hajautus on työlästä.
2000-luvun lopussa ja 2010-luvun alussa verrattain uudet tietokantaparadigmat kuten dokumentti-, graafi-, sarakeperhe- ja avain-arvoparitietokannat saavuttavat suosiotaan. Uusista tietokantaparadigmoista käytetään yleisnimitystä NoSQL (Not only SQL). Tuotteita ovat mm. Googlen Bigtable, Facebookin Cassandra ja Amazonin Dynamo. Relaatiotietokannanhallintajärjestelmät ovat edelleen suosituimpia tietokantatuotteita, ja suosituimpia niistä ovat Oracle Database, SQL Server, PostgreSQL, DB/2, MySQL, MariaDB ja SAP Adaptive Server.
2010-luvun alussa Google havaitsee NoSQL-paradigmaperheen tuotteet sopimattomiksi tarpeisiinsa, ja alkaa kehittää jälleen uutta tietokannanhallintajärjestelmää nimeltä Spanner. Uutta paradigmaperhettä kutsutaan nimellä NewSQL. Paradigmaperheen tuotteille on yhteistä SQL-rajapinta sekä relaatioparadigman tukeminen.
2. Arkkitehtuuri ja analyysi
2.1 Sovellusarkkitehtuuri
Kuten luvussa 1 todettiin, tietokantajärjestelmä koostuu yleisellä tasolla kolmesta osasta: tietokannasta, tietokannanhallintajärjestelmästä ja sovellusohjelmasta. Sovellusohjelma tarjoaa loppukäyttäjille toimintalogiikan ja käyttöliittymän, jonka avulla järjestelmää käytetään. Sovellusohjelma voi olla miten monimutkainen kokonaisuus tahansa, ja sovellusohjelmia voi kuulua tietokantajärjestelmään useita. On myös tavallista, että tietokantajärjestelmä sisältää useita tietokantoja ja jopa tietokannanhallintajärjestelmiä.
2.1.1 Tietokannanhallintajärjestelmän rakenne
Tietokannanhallintajärjestelmä on tavallisesti monimutkainen ohjelmisto, ja eri tuotteissa on vaihteleva määrä toiminnallisuutta aina monimutkaisimmista tuotteista kuten Oracle, DB/2 ja SQL Server yksinkertaisiin ja ominaisuuksiltaan riisuttuihin tuotteisiin kuten SQLite. Tuotteista voidaan myös tarjota erilaisia versioita (kuten Oracle Express, Standard ja Enterprise), joiden hinta määräytyy version ominaisuuksien mukaan. Tietokannanhallintajärjestelmään kuuluu ainakin:
- Käskykomponentti, joka on vastuussa käskyjen eli tietokantaan kohdistuvien kyselyiden, lisäyksien, muokkauksien ja poisto-operaatioiden tarkastamisesta, optimoinnista ja ajosta.
- Varastointikomponentti, joka on vastuussa siitä, miten data noudetaan levyltä muistiin ja edelleen sitä tarvitsevalle sovellusohjelmalle tai käyttäjälle niin, että tietyt vaatimukset täytetään.
- Rajapinta, jonka avulla tietokantaa voidaan käyttää ilman sovellusohjelmaa.
Edelleen eri tuotteissa on lisäkomponentteja, tavallisesti esim.:
- Graafinen käyttöliittymä kyselyiden tekemiseen ja tietokannan rakenteen seuraamiseen.
- Monitorointityökalut, joiden avulla DBMS:n suorituskykyä ja kuormitusta voidaan seurata.
- Varmuuskopiointityökalut.
- Työkalut datan raportointiin, analysointiin ja louhintaan.
- Eräajotoiminto suurten datamäärien viemiseen tietokantaan ja tuomiseen tietokannasta.
- Erilaiset väliohjelmistot DBMS:n liittämiseksi muihin tietokantajärjestelmän sisäisiin tai sen ulkopuolisiin komponentteihin.
- Jaetut komponentit käyttöjärjestelmän tai käyttöjärjestelmäytimen kanssa, esimerkiksi tietokannan salaus tai pakkaaminen tai käyttäjätilien jakaminen.
2.1.2 Tietokantakäskyn kulku
Tarkastellaan seuraavaksi yleisellä tasolla, mitä tietokantakäskylle tapahtuu, kun sovellusohjelma tai käyttäjä lähettää sen DBMS:lle. Tietokantakäsky voi olla esimerkiksi "Hae kaikkien punaisten kenkien hinta ja alennusprosentti".
Sovellusohjelma lähettää pyynnön DBMS:lle yhteyden muodostamiseksi. DBMS voi evätä yhteyden esim. jos tietokantapalvelimen muisti on vähissä tai jos enimmäismäärä käyttäjiä on jo yhdistyneenä tietokantaan. Jos DBMS hyväksyy yhteyden muodostamisen, voi sovellusohjelma lähettää tietokantakäskyn.
2.1.2.1 Käskykomponentti
Tietokantakäsky päätyy seuraavaksi DBMS:n käskykomponentille. Käskykomponentti sisältää useita alikomponentteja, joista ensimmäinen, käskyparseri tarkastaa tietokantakäskyn oikeinkirjoituksen. Käskyparseri myös kirjoittaa tietokantakäskyn auki, jos siinä on aukikirjoittamista vaativia viitteitä tai lyhennelmiä. Jos käskyssä on syntaksivirheitä, DBMS voi sietokykynsä mukaan korjata niitä. Jos virheitä ei pystytä korjaamaan, sovellusohjelmalle palautetaan virheilmoitus. Muussa tapauksessa parseri luo kyselystä ns. jäsennyspuun (parse tree), ja lähettää sen uudelleenkirjoituskomponentille.
Uudelleenkirjoituskomponentti huolehtii mm. tietokantakäskyn mahdollisten laskutoimitusten, loogisten lausekkeiden ja päättelysääntöjen sievennyksestä ja keinotekoisten tietorakenteiden avaamisesta. Jos tietokannan rakenteeseen on tehty näkymiä tai sääntöjä, uudelleenkirjoittaja avaa ne. Uudelleenkirjoittaja tarkastaa tietokannan metadasta, onko käskyn sisältämiä tietokantarakenteita (ts. tietokantaobjekteja) olemassa, ja onko käskyn suorittavalla käyttäjällä tarvittavat oikeudet nähdä tai muokata niitä.
Monimutkaisin käskykomponentin alikomponentti on käskyn optimoija. Koska SQL on deklaratiivinen kieli, voidaan haluttu tulos saavuttaa useilla eri tavoilla. Optimointikomponentti luo uudelleenkirjoittajalta saamansa kyselypuun (query tree) perusteella useita suoritussuunnitelmia (execution plan). Tietokannan metadataa tarkastelemalla optimointikomponentti päättää, mikä luoduista suoritussuunnitelmista on ajallisesti nopein toteuttaa, ts. esim. miten haluttu data voidaan palauttaa nopeimmin sovellusohjelmalle. Tällaista optimointia kutsutaan kustannusperustaiseksi optimoinniksi, ja optimointitapoja on muitakin. Optimoija lähettää parhaaksi katsomansa suoritussuunnitelman eteenpäin käskyn ajajalle. Käskyn ajoalikomponentti suorittaa suoritussuunnitelman käyttäen apuna varastointikomponenttia.
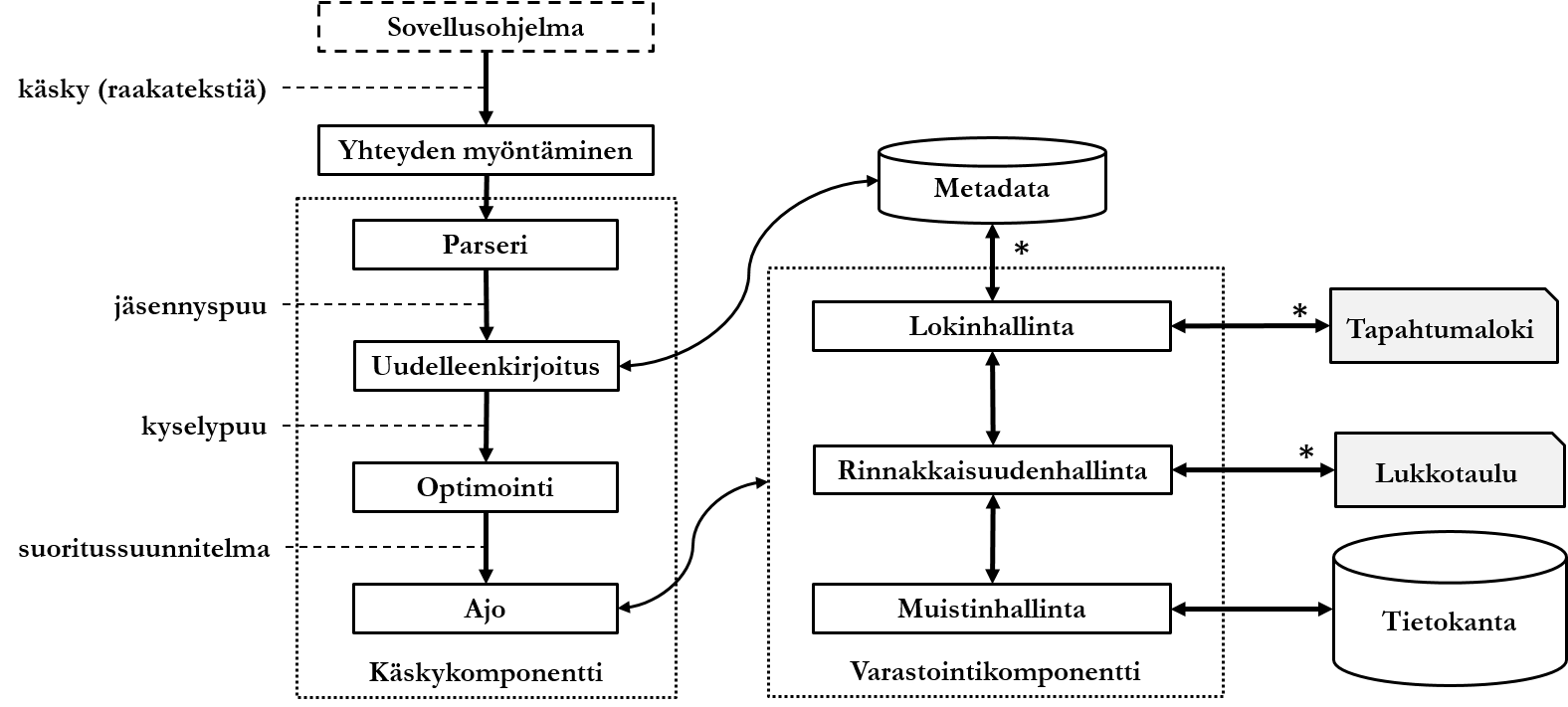
2.1.2.2 Varastointikomponentti
Varastointikomponentti on eräänlainen varmistin sille, että dataa käsitellään oikein. Kun ajokomponentti aloittaa suoritussuunnitelman suorittamisen, varastointikomponentti tarkastaa mm. käskyn kannalta tärkeiden, avustavien fyysisten tietorakenteiden toiminnallisuuden. Käsky myös kirjoitetaan DBMS:n lokiin, ja jos käsky tekee muutoksia tietokannan rakenteeseen, nämä muutokset kirjoitetaan DBMS:n metadataan.
Seuraavaksi DBMS:n rinnakkaisuudenhallinnasta vastaava komponentti tarkastaa, onko samanaikaisesti käynnissä muita tapahtumia, jotka voivat haitata käsiteltävää tietokantakäskyä. Jos kaikki on kunnossa, DBMS:n lukkohallinnasta vastaava komponentti kirjoittaa ns. lukkotauluun tietokantakäskyn käyttävien tietuiden olevan muiden samanaikaisten tapahtumien käyttämättömissä (ts. lukittuna).
DBMS:llä on tavallisesti omat puskurialueensa, eikä se käytä esimerkiksi käyttöjärjestelmän tiedostovälimuistia. Tietokanta on jaettu yhtä suuriin osiin eli sivuihin DBMS:n puskurin kanssa. Puskurinhallinnan vastuulla on noutaa haluttu sivu muistin puskurialueelle käyttämällä apuna muistinhallintakomponenttia, joka huolehtii DBMS:n tarvitseman muistin jakamisesta erilaisiin muistialueisiin. Lopuksi halutut sivut kootaan palautettavaan muotoon ja palautetaan sovellusohjelmalle tai käyttäjälle.
2.2 Käsitteellinen mallintaminen
Tässä alaluvussa tarkastellaan käsitteellistä mallintamista käyttäen ER-mallia (Entity-Relationship model). ER-notaatio on suosittu tietokantojen alustavan suunnittelun työkalu. Käsitteellistä mallintaminen voidaan mieltää kuuluvaksi tietojärjestelmän elinkaaren analyysi- ja suunnitteluvaiheisiin. Luvussa oletetaan, että lukija tuntee analyysivaiheen UML-luokkakaavion (Unified Modeling Language) perusperiaatteet ja osaa luoda sellaisen. Tämä alaluku perustuu lähteisiin Chen (1976) ja Elmasri & Navathe (2007, s. 61-81 ja 101-111).
2.2.1 Kohdetyypit ja attribuutit
ER-malli koostuu kohdetyypeistä (entity set), suhdetyypeistä (relationship) ja attribuuteista. Kohdetyypit muistuttavat luokkakaavion luokkia: ne kuvaavat jotakin itsenäistä, reaalimaailman konkreettista tai käsitteellistä asiaa eli kohdetta, esimerkiksi opiskelijaa, kurssia tai opintosuoritusta. Kohdetyyppi ei kuitenkaan ole yksi reaalimaailman asia, vaan kuvaa abstrahoidun asioiden joukon ominaisuuksineen kuten luokkakaavion luokka.
Kohde- ja suhdetyypeillä on attribuutteja, jotka ovat kohteiden tai suhteiden kohdealueen kannalta mielenkiintoisia ominaisuuksia, esimerkiksi opiskelijalla voi olla opiskelijatunnus, nimi ja syntymäaika. Attribuutin arvo on yksittäisen kohteen tai suhteen ominaispiirre. Kohdetyyppien attribuuteista ja niiden arvoista muodostetaan lopulta tietokannan data.
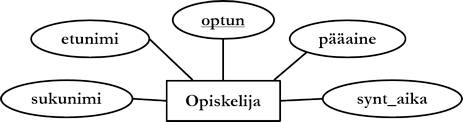
Kohdetyyppiä merkitään suorakulmiolla, jonka sisällä on kohdetyypin nimi. Kohdetyypin attribuutteja merkitään soikiolla, jonka sisällä on attribuutin nimi.
Yllä olevassa kuviossa kohdetyyppi opiskelija kuvaa opiskelijoiden joukon ominaisuuksineen.
2.2.1.1 Avainattribuutti
Jokaisen kohdetyypin kuvaaman kohteen on oltava yksiselitteisesti tunnistettavissa toisistaan. Tunnistaminen tehdään tavallisesti jonkin sellaisen attribuutin perusteella, jonka arvo on jokaisella kohteella uniikki. Tällaista attribuuttia kutsutaan avainattribuutiksi (key attribute). Jos yhden attribuutin arvo ei riitä tunnistamaan kohteita toisistaan, voidaan käyttää useampaa kuin yhtä attribuuttia kuitenkin niin, että avainattribuuttien aito osajoukko ei riitä tunnistamaan kohteita toisistaan.
Avainattribuutin arvo ei voi olla tyhjäarvo. Kohdetyypin avainattribuutit tunnistetaan niiden nimien alleviivauksesta.
2.2.1.2 Koottu attribuutti
Kootulla (composite) attribuutilla tarkoitetaan attribuuttia, jonka arvo voidaan jakaa tunnistettaviin osiin, esimerkiksi attribuutti osoite voidaan alla olevan kuvion mukaan jakaa osiin katu, postinro ja kaup. Osiin jakaminen on erityisen perusteltua silloin, kun attribuuttiin viitataan sekä kokonaisuutena että osina. Jos esimerkiksi osoitteeseen viitattaisiin aina kokonaisuutena, ei osiin jakaminen olisi perusteltua.
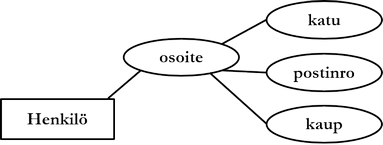
Jos attribuutti ei ole koottu, se on yksinkertainen (simple). Kootut attribuutit voivat muodostaa syvempiäkin hierarkioita.
2.2.1.3 Johdettu attribuutti
Johdetulla (derived) attribuutilla tarkoitetaan attribuuttia, jonka arvo on johdettu joko
- toisen attribuutin tai attribuuttien arvoista tai
- siihen liittyvän kohdetyypin kohteiden lukumäärästä.

Johdettua attribuuttia merkitään katkoviivaisella soikiolla yllä olevan kuvion mukaisesti. Attribuutti ikä on johdettu attribuutista synt_aika ja attribuutti opisk_lkm kohteiden lukumäärästä. Jos attribuutti ei ole johdettu, se on tallennettu (stored).
2.2.1.4 Moniarvoinen attribuutti
Tavallisesti attribuuteilla on yksi arvo, ja tällaisia attribuutteja kutsutaan atomisiksi (atomic). On kuitenkin mahdollista, että kohdetyypin kohteiden attribuuteilla voi olla useampia arvoja, esimerkiksi opiskelijalla voi olla useita puhelinnumeroita tai sähköpostiosoitteita. Jos attribuutilla voi olla useampia arvoja, sitä kutsutaan moniarvoiseksi (multivalued).

Moniarvoista attribuuttia merkitään yllä olevan kuvion mukaisesti kaksinkertaisella soikiolla. Opiskelija-kohdetyypillä on kaksi moniarvoista attribuuttia.
2.2.2 Suhdetyypit
Kohteilla kuten reaalimaailman asioillakin on tyypillisesti jonkinlaisia suhteita keskenään. Suhde (relationship) on mikä tahansa 1..n kohteen välillä vallitseva riippuvuus tai muu kiinnostava asiayhteys. Suhteiden joukot muodostavat suhdetyyppejä. Tietokantaa suunnitellessa relevantit suhteet kohdetyyppien välillä on tunnistettava ja kuvattava ne ER-kaavioon. Suhdetyyppejä kuvataan ER-notaatiossa kulmallaan seisovalla neliöllä, joka on liitetty suhteeseen osallistuviin kohdetyyppeihin. Suhdetta kuvataan tavallisesti jollakin yksikön 3. persoonan verbillä.
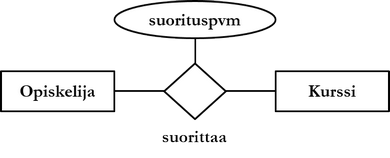
Myös suhdetyypeillä voi olla attribuutteja. Suhdetyypin attribuutit kuvaavat jotakin suhteen ominaisuutta, esimerkiksi yllä olevan esimerkin suorituspvm. Suorituspäivämäärä ei liity kohdetyyppiin kurssi, eikä kohdetyyppiin opiskelija, vaan kohdetyyppien väliseen suhteeseen. Suhdetyypin, johon osallistuu n kohdetyyppiä, sanotaan olevan asteluvultaan (degree) n. Yllä kuvatun suhdetyypin asteluku on 2, ts. suhdetyyppi on binäärinen. Kahdella kohdetyypillä voi olla keskenään useampi kuin yksi binäärinen suhdetyyppi.
2.2.2.1 Muut kuin binääriset suhteet
Suhdetyypin asteluku voi olla 1..n. Alla on kuvattu unaarinen (asteluku 1) ja tertiäärinen (asteluku 3) suhdetyyppi.
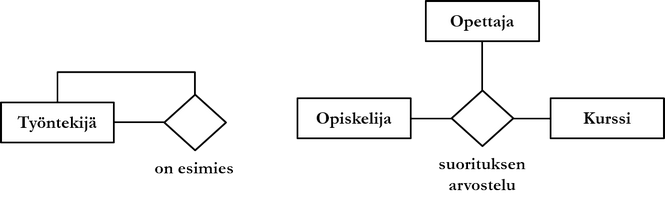
Yllä olevan kuvion mukaan työntekijä voi olla esimies muille työntekijöille. Toisessa esimerkissä kohdealueen kannalta on tärkeää, että tiedetään kuka opettaja opiskelijan kurssisuorituksen on arvostellut.
Asteluvultaan kahta korkeammilla suhdetyypeillä on omat ongelmansa, mutta aina niitä ei voida välttää. Yllä olevan esimerkin voisi toteuttaa myös heikolla kohdetyypillä arvostelu. Heikkoa kohdetyyppiä käsitellään hieman myöhemmin.
2.2.2.2 Kardinaliteetti
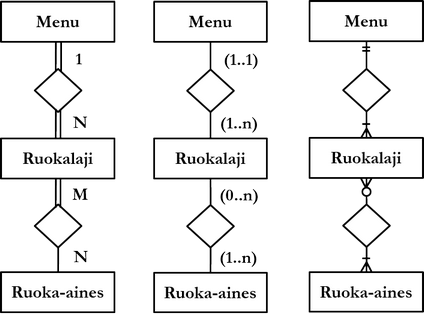
Suhdetyyppeihin merkitään lisäksi suhteeseen osallistuvien kohteiden minimi- ja maksimimäärät, joista käytetään yhteisnimitystä kardinaliteetti. Joskus minimikardinaalisuudesta käytetään nimitystä suhteen pakollisuus. Tällä kurssilla käsitellään Chenin notaatio, jossa minimikardinaalisuus on joko 0 tai 1 ja maksimikardinaalisuus joko 1 tai N. Binääriseen suhteeseen liittyy siis aina yhteensä neljä kardinaalisuusmerkintää: kaksi minimiä ja kaksi maksimia. Jos yhteen suhdetyyppiin liittyy useampi kuin yksi maksimikardinaalisuus N, yleinen käytäntö on käyttää muita kirjaimia kuvaamaan muita maksimikardinaalisuuksia N, esim. kirjaimia M, P, Q jne.

Minimikardinaalisuus merkitään suhteeseen liittyvillä viivoilla: yhdellä viivalla tarkoitetaan minimikardinaalisuutta 0 (ts. suhteeseen osallistuminen ei ole pakollista) ja kaksoisviivalla minimikardinaalisuutta 1 (ts. suhteeseen osallistuminen on pakollista). Maksimikardinaalisuus merkitään merkillä sille puolelle suhdetta, johon päin luetaan (ks. esimerkki alla).
Yllä olevassa kuviossa on kuvattu kuvitteellinen kohdealue, jossa kuvatut liiketoimintasäännöt pätevät. Kuvion voisi lukea auki kahdella tavalla:
- Vasemmalta oikealle: henkilö ei välttämättä omista autoa, mutta voi omistaa useita (0..n).
- Oikealta vasemmalle: auton omistaa yksi ja vain yksi henkilö (1..1).
Muita yleisesti käytettyjä kardinaalisuusnotaatiota on kuvattu alla: vasemmalla tällä kurssilla käsiteltävä Chenin notaatio, keskellä Martinin UML:ää muistuttava notaatio ja oikealla notaatio Hoffer, Prescott & McFaddenin mukaan, joka on suosittu monissa tietokannanhallintajärjestelmien rinnalla käytetyissä 3. osapuolen suunnittelutyökaluissa.
2.2.2.3 Tunnistava suhdetyyppi
Jos kohdetyypin mukaisia kohteita ei voida tunnistaa sen omien attribuuttien avulla, sitä sanotaan heikoksi kohdetyypiksi. Heikkoa kohdetyyppiä merkitään kaksoissuorakulmiolla. Heikon kohdetyypin mukaiset kohteet tunnistetaan toisen kohdetyypin avainattribuutteja hyväksi käyttäen, ja tällaista kohdetyyppiä kutsutaan tunnistavaksi kohdetyypiksi. Tunnistava kohdetyyppi kuvataan tunnistavan suhdetyypin avulla. Tunnistava suhdetyyppi kuvataan kaksoistimantilla.
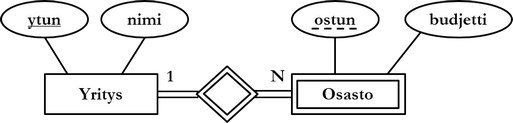
Yllä olevassa kuviossa heikko kohdetyyppi osasto tunnistetaan vahvan kohdetyypin yritys avulla. Heikon kohdetyypin avainattribuutin nimi alleviivataan katkoviivalla. Yllä kuvatun kohdealueen osastot tunnistetaan siis osaston tunnuksen ja yritystunnuksen yhdistelmällä.
2.2.3 Abstraktiorakenteet
ER-notaatiota on myöhemmin täydennetty. Yksi tällaisista täydennyksistä on nk. EER-notaatio (extended tai enhanced ER), joka lisää notaatioon mm. abstraktiorakenteet. Abstraktiorakenteiden avulla voidaan mallintaa hierarkioita ja oliosuuntautuneisuuden mukaista perintää: alikohdetyypit perivät ylikohdetyyppinsä attribuutit. Kohdetyyppien välistä perintää merkitään seuraavan kuvion mukaisesti.
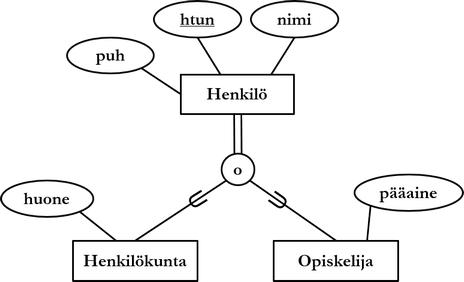
Ylikohdetyyppinä on kuviossa henkilö, alikohdetyyppeinä opiskelija ja henkilökunta. U-kirjaimen muotoiset merkinnät osoittavat alikohdetyyppeihin. Ympyrän yhdistää ylikohdetyyppiin joko yksi tai kaksi viivaa. Ympyrän sisälle on merkitty joko kirjain d tai o. Abstraktiorakenteet voivat muodostaa monimutkaisempiakin hierarkioita. Tarkastellaan seuraavaksi kahta erilaista EER-notaation mukaista yleistysrakennetta.
2.2.3.1 Erillinen
Erillisellä (disjoint) abstraktiorakenteella tarkoitetaan, että kohteet ovat korkeintaan yhden alikohtetyypin mukaisia kohteita, esimerkiksi puu on lehti- tai havupuu. Erillistä abstrahointia merkitään ympyrän sisälle sijoitetulla kirjaimella d.
Alikohdetyyppijoukon kattavuutta kuvataan yhdellä tai kahdella viivalla ympyrän ja ylikohdetyypin välillä. Kahdella viivalla kuvataan alityyppijoukon olevan kattava. Kattavuudella tarkoitetaan, että kaikki reaalimaailman kohdetyypit on kuvattu abstraktiorakenteessa. Esim. alla olevan vasemman puoleisen kuvion mukaisesti, jos kohdealueen kannalta mielenkiintoisia ajoneuvoja (kuviossa vastaava kohdetyyppi A) ovat vain henkilöautot ja moottoripyörät (kuviossa vastaavat kohdetyypit B ja C), kattava abstraktiorakenne kertoo, että ajoneuvo on joko henkilöauto tai moottoripyörä.
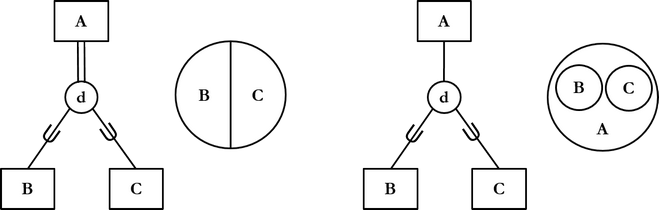
Yhdellä viivalla kuvataan alityyppijoukon olevan osittainen: kohteen ei tarvitse olla yhdenkään alikohdetyypin mukainen kohde. Esim. yllä olevan oikean puoleisen kuvion mukaisesti kohdealueen kannalta on tarpeen eriyttää ajoneuvot (A) henkilöautoihin (B) ja moottoripyöriin (C). Osittainen yleistysrakenne kuitenkin kertoo, että kohdealue tunnustaa myös muiden, geneeristen ajoneuvojen olemassaolon ja on valmis tallentamaan tietoa myös niistä.
2.2.3.2 Leikkaava
Leikkaavalla (overlapping) abstraktiorakenteella tarkoitetaan, että kohteet voivat olla useamman kuin yhden alikohdetyypin mukaisia kohteita, esimerkiksi huone on keittiö ja ruokasali. Leikkaavaa abstraktiorakennetta kuvataan ympyrän sisään sijoitetulla kirjaimella o. Kuten erillinen, myös leikkaava abstraktiorakenne on joko kattava tai osittainen.
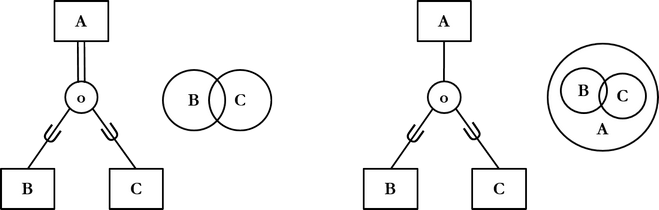
Monivalintatehtävät liittyvät seuraavaan ER-kaavioon:
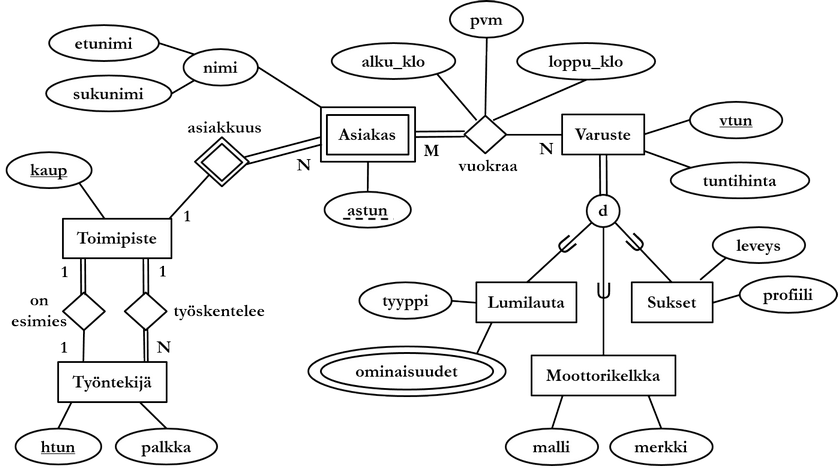
3. Relaatiomalli
Relaatiomalli on Edgar F. Coddin kirjoittama, vuonna 1970 julkaistu teoria, joka muodostaa relaatiotietokantojen teoreettiset perusteet. Teoria mallin takana on joukko-oppiin perustuva, ja muihin tietokantaparadigmoihin nähden vahva. Relaatiomalli on loogisen tason tietomalli: se ei määritä miten dataa tulisi tallentaa tai käsitellä fyysisesti.
Tämä luku koostuu kolmesta alaluvusta. Ensimmäisessä esitellään Coddin relaatiomallin teoreettiset perusteet. Toisessa luvussa tarkastellaan, kuinka edellisessä luvussa muodostetut ER-kaaviot voidaan muuntaa relaatiomallin mukaisiksi tietorakenteiksi. Lopuksi tarkastellaan Coddin relaatioalgebraa, joka on relaatiotietokantoihin kohdistuvan kyselykielen perusta.
3.1 Teoreettinen perusta
Tämä alaluku perustuu Coddin (1970) julkaisuun. Relaatioparadigman teoreettisena perustana on ns. relaatiomalli. Tarkastellaan seuraavaksi miten relaatiomalli määrittää relaatiotietokannan osat.
3.1.1 Rakenne ja sisältö
Attribuutti (attribute) on pari <A,a>, joka koostuu attribuutin nimestä A ja arvosta a. Attribuutti on kohteen ominaisuus, esimerkiksi henkilöllä on etunimi (attribuutin nimi) ja etunimi on Matti (attribuutin arvo). Jos a on ns. tyhjäarvo, kohteen ominaisuuden sisältöä ei tunneta tai se ei ole merkityksellinen. Tyhjäarvon huomioiminen tuo mukanaan kolmiarvoisen logiikan: tosi, epätosi ja tuntematon.
Otsake (header) on yhteen relaatioon liittyvä joukko attribuuttien nimiä. Relaation otsake on relaation kaikkien attribuuttien nimet.
Monikko (tuple) on otsakkeen H mukainen joukko järjestettyjä pareja <A,m>. Pari koostuu attribuutin nimestä A ja arvosta m. Monikon asteluku on relaation asteluku.
Relaatio (relation) r on pari <H,h>, joka koostuu sisällöstä (body) h, joka on joukko monikoita sekä otsakkeesta H. H on r:n otsake ja H:n attribuutit ovat r:n attribuutteja. Relaation, jonka otsake koostuu n attribuutista, sanotaan olevan asteluvultaan (degree) n.
Relaatiomallin mukaan taulukkona kuvatulla, asteluvultaan n relaatiolla R on seuraavat ominaisuudet:
- Jokainen rivi edustaa R:n n-monikkoa.
- Rivien järjestyksellä ei ole merkitystä.
- Jokainen rivi on erotettavissa toisistaan.
- Sarakkeiden järjestyksellä ei ole merkitystä, kunhan tietyn attribuutin nimen ja sen arvon yhteys voidaan yksiselitteisesti ymmärtää.
- Sarakkeen merkitys käy ainakin osittain ilmi sen nimestä.
Relaation kardinaalisuudella tarkoitetaan sen monikoiden lukumäärää. Attribuutin kardinaalisuudella tarkoitetaan sen erilaisten tallennettujen arvojen lukumäärää. Relaatiosta käytetään tarvittaessa tarkempia määrityksiä: rakenteesta (ts. nimestä ja otsakkeesta) käytetään nimitystä relaatiokaava (relational variable tai intention) ja sisällöstä nimitystä monikkojen joukko (relational value tai extension).
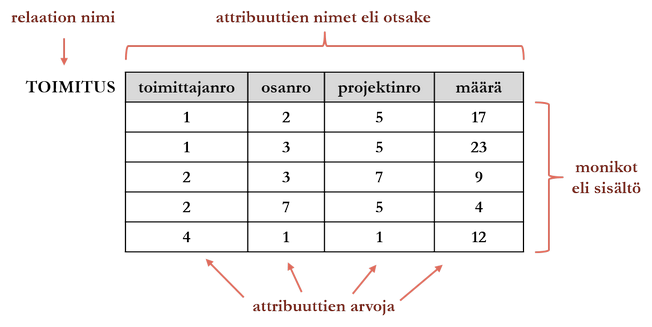
Yllä taulukkona kuvatun relaation relaatiokaava on siis TOIMITUS(toimittajanro, osanro, projektinro, määrä) ja sisältö sen kaikki monikot.
Relaatiotietokanta koostuu relaatiokaavojen sekä eheysrajoitteiden joukosta. Tarkastellaan seuraavaksi eheysrajoitteita.
3.1.2 Eheysrajoitteet
Eheysrajoitteet (integrity constraint) ovat erilaisia tekniikoita viite-eheyden varmistamiseksi relaatiotietokannassa. Tärkeimmät eheysrajoitteet ovat perusavain ja viiteavain. Käytännön toteutuksessa on olemassa myös muita eheysrajoitteita, joita tarkastellaan tarkemmin luvussa 4.
Jotta relaation monikkoihin voitaisiin yksiselitteisesti viitata, mitkään kaksi relaation monikkoa eivät saa olla samat. Relaation attribuuttijoukon (joukossa on tästä edes 1..n attribuuttia ellei toisin mainita) arvon tulee yksiselitteisesti yksilöidä jokainen monikko kyseisessä relaatiossa. Attribuuttijoukkoa, joka yksilöi relaation monikot kutsutaan avainehdokkaaksi (candidate key, CK).
Avainehdokkaiden joukosta valitaan yksi relaation perusavaimeksi (primary key, PK). Perusavain on niin ikään attribuuttijoukko, joka yksiselitteisesti yksilöi relaation monikot. Kuten avainehdokkaan, perusavaimen tulee täyttää kaksi vaatimusta:
- Perusavain on yksilöivä, jolloin jokainen perusavaimen arvo on yksilöllinen, ts. uniikki. Perusavain ei voi saada edes osittain tyhjäarvoa.
- Perusavaimen tulee olla jakamaton, jolloin mikään perusavaimen aito osajoukko ei ole yksilöivä, ts. perusavaimen tulee olla asteluvultaan niin pieni yksilöivä attribuuttijoukko kuin mahdollista, jotta 1. vaatimus täyttyy.
Lisäksi perusavaimen arvon tulisi olla muuttumaton. Aina tämä ei kuitenkaan ole mahdollista, ja perusavaimeksi voidaan joutua valitsemaan sellainen attribuuttijoukko, jonka arvo saattaa muuttua.
Avainattribuutilla (key attribute) tarkoitetaan attribuuttia, joka on relaation perusavaimen atominen (ts. jakamaton) osajoukko. Jos perusavainta ei ole valittu, avainattribuutilla tarkoitetaan avainehdokkaan atomista osajoukkoa.
Superavaimella (superkey) tarkoitetaan attribuuttijoukkoa, jonka arvojen perusteella relaation monikot voidaan yksilöidä. Superavaimen tulee olla yksilöivä, joilloin jokainen arvo on yksilöllinen, mutta sen ei tarvitse olla jakamaton. Toisin sanoin superavaimesta voi olla mahdollista poistaa attribuutteja niin, että attribuuttijouku silti yksilöi relaation monikot. Kaikki avainehdokkaat ovat siis superavaimia, mutta ei päinvastoin. Avainehdokkaista ei siis voi poistaa attribuutteja niin, että joukko olisi edelleen avainehdokas. Superavainta, joka ei ole avainehdokas, kutsutaan todelliseksi superavaimeksi. Koska relaation jokaisen rivin tulee olla erotettavissa toisistaan, on relaation kaikkien attribuuttien joukko automaattisesti relaation superavain. Edelleen tästä johtuen jokaisella relaatiolla on ainakin yksi avainehdokas. Superavaimeen palataan luvussa 5.
Relaatioiden kuvaamissa kohdealueissa on tavallista, että yhden kohteen (esim. työntekijä) on pystyttävä viittaamaan toisiin kohteisiin (esim. projekti). Tämä viittaus tehdään tavallisesti avainten avulla. Viiteavaimeksi (foreign key, FK) kutsutaan relaation R attribuuttijoukkoa, jonka arvot ovat jonkin toisen relaation S attribuutin tai attribuuttijoukon arvojoukosta. Toisin sanoen relaation R viiteavaimen arvojoukko on relaation S attribuuttijoukon arvojoukon osajoukko.
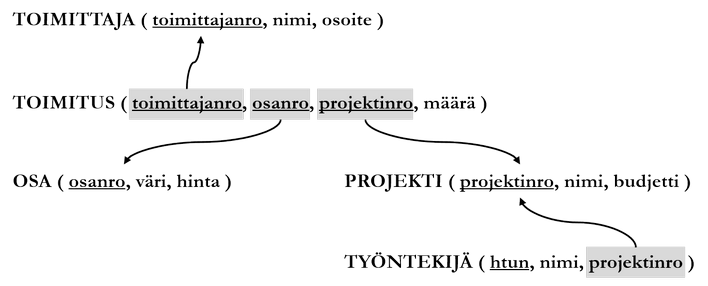
Yllä kuvatussa relaatiotietokannan kaavassa on viisi relaatiokaavaa. Perusavainten merkitsemiseen käytetään attribuuttien nimien alleviivausta. Toimitus-relaatiossa on kolme viiteavainta, ja työntekijä-relaatiossa yksi. Viiteavaimet viittaavat toisten relaatioiden avainattribuutteihin.
3.1.3 Sallitut tietotyypit
Relaatiomalli tunnistaa, että attribuutin arvojoukko voi olla atominen tai moniarvoinen. Atomisella arvojoukolla tarkoitetaan, että attribuutin arvo kaikilla relaation monikoilla on jakamaton (esim. henkilötunnus tai sukunimi). Moniarvoisella arvojoukolla tarkoitetaan, että attribuutin arvo voi olla relaation jollakin monikolla joukko tai lista tai taulukko jne. (esim. tilatut_tuotteet tai henkilön_lapset).
Relaatiomalli kutsuu relaatioita, joilla on ainakin yksi moniarvoinen attribuutti normalisoimattomiksi (unnormalized). Jos relaation kaikki attribuutit ovat atomisia, relaatio on normalisoitu (normalized). Myöhemmin on esitetty, että normalisoimaton relaatio ei ole relaatiomallin mukainen. Normalisointia käsitellään tarkemmin luvussa 5.
3.2 Transformointi
Käsitekaavan transformoinnilla tarkoitetaan luvussa 2 esitellyn ER-kaavion muuntamista relaatiotietokannan kaavaksi. Transformoinnin lähtökohtana on joukko yksinkertaisia sääntöjä, joita noudattamalla voidaan muodostaa alustava relaatiotietokannan kaava. Tietokannan loogisen rakenteen tarkempaa suunnittelua tarkastellaan luvussa 5. Transformointisäännöt on mukailtu Elmasri & Navathen (2007, s. 219-226) esityksestä.
3.2.1 Kohdetyyppien transformointi
Sääntö 1.: jokaisesta vahvasta kohdetyypistä tehdään oma, ns. kohderelaatio. Kohdetyypin tavallisista attribuuteista (eli attribuuteista, jotka ovat atomisia, yksinkertaisia ja tallennettuja) tehdään relaation attribuutteja. Kohdetyypin avainattribuuteista muodostetaan relaation perusavain.
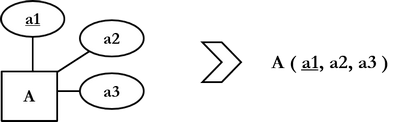
Sääntö 2.: jokaisesta heikosta kohdetyypistä tehdään oma relaatio säännön 1. mukaisesti. Relaation perusavain muodostetaan kohdetyypin avainattribuuttien lisäksi tunnistavan kohdetyypin avainattribuuteista.

3.2.2 Attribuuttien transformointi
Sääntö 3.: jokainen johdettu attribuutti hylätään.
Sääntö 4.: jokaisesta kootusta attribuutista valitaan kohderelaatioon kokoavat (yksinkertaiset) attribuutit. Koottava attribuutti hylätään.
Sääntö 5.: jokaisesta moniarvoisesta attribuutista tehdään oma, ns. attribuuttirelaatio. Relaation perusavaimeksi valitaan moniarvoisen attribuutin lisäksi sen kohdetyypin avainattribuutit, johon transformoitava moniarvoinen attribuutti kuuluu.
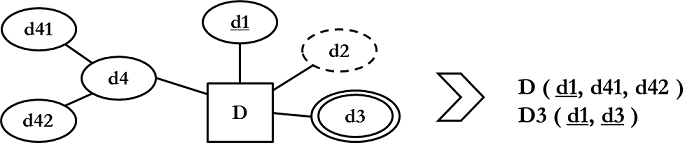
3.2.3 Suhdetyyppien transformointi
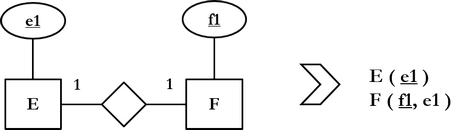
Sääntö 6.: jokaisesta binäärisestä 1:1-suhdetyypistä sijoitetaan toisen kohdetyypin K1 avainattribuutit viiteavaimeksi toisesta kohdetyypistä K2 muodostettuun relaatioon.
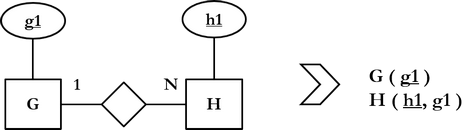
Sääntö 7.: jokaisesta binäärisestä 1:N-suhdetyypistä sijoitetaan 1:n puoleisen kohdetyypin avainattribuutit viiteavaimeksi N:n puoleisesta kohdetyypistä muodostettuun relaatioon.
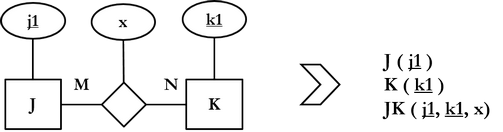
Sääntö 8.: jokaisesta binäärisestä N:M-suhdetyypistä muodostetaan oma, ns. suhderelaatio. Relaation attribuuteiksi valitaan suhdetyypin mahdolliset attribuutit ja perusavaimeksi N:M-suhteeseen liittyvien kohdetyyppien avainattribuutit.
Sääntö 9.: jokainen n-äärinen (n > 2) suhdetyyppi transformoidaan säännön 8. mukaisesti.
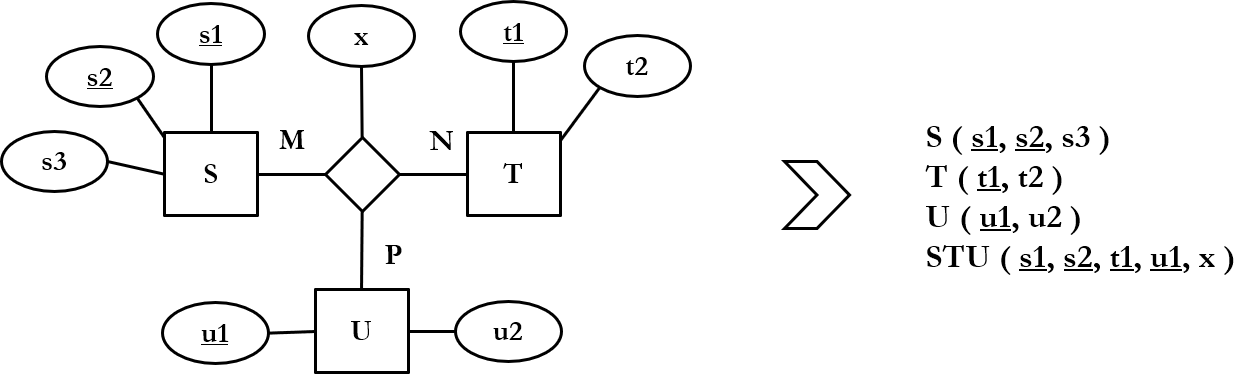
3.2.4 Abstraktiorakenteiden transformointi
Erilaisten abstraktiorakenteiden (osittainen tai kattava sekä leikkaava tai erillinen) transformoinnille on yleisellä tasolla neljä tapaa. Eri tavat sopivat erilaisiin rakenteisiin.
Tapa 1.: jokaisesta ali- ja ylikohdetyypistä muodostetaan oma relaatio.
Tapa 2.: jokaisesta alikohdetyypistä muodostetaan oma relaatio. Relaatioiden attribuuteiksi valitaan sekä kohdetyyppien omat attribuutit että ylikohdetyypin attribuutit.
Tapa 3.: muodostetaan yksi relaatio, jonka attribuuteiksi valitaan kaikkien ali- ja ylikohdetyyppien kaikki attribuutit sekä lisäattribuutti ilmaisemaan monikon roolia relaatiossa.
Tapa 4.: muodostetaan yksi relaatio tavan 3. mukaan, mutta lisäattribuutin sijaan käytetään totuusarvoisia lisäattribuutteja (flageja) ilmaisemaan monikon rooleja relaatiossa.
Lopuksi on syytä mainita, että esitettyihin sääntöihin on olemassa lukuisia poikkeuksia. Lisäksi monimutkaisemmissa kohdealueissa sääntöjä täytyy soveltaa.
3.3 Relaatioalgebra
Tämä alaluku perustuu Coddin (1970) lisäksi Daten (2009, s. 114-120) ja Darwenin (2010, s. 85-112) materiaaleihin.
Varsinaisen relaatiomallin lisäksi Codd esitteli relaatioalgebran, joka on matematiikkaan perustuva, sekä logiikka että semantiikka korkeatasoiselle relaatiotietokannoille tarkoitetulle kyselykielelle. Kyselykieltä kutsutaankin relaationaalisesti täydelliseksi, jos sen avulla voidaan suorittaa relaatioalgebran mukaiset operaatiot. Monet relaatioalgebran operaatiot kuten yhdiste, leikkaus ja erotus ovat tuttuja joukko-opista.
Operaatioilla kuvataan tulosrelaatio. Tulosrelaatio on relaatiotietokannan relaatioista johdettu relaatio, joka sisältää halutun datan (esimerkiksi kaikkien jyväskyläläisten työntekijöiden lasten nimet). Operaatiot ottavat ainakin yhden relaation syötteekseen ja antavat tulosteena tulosrelaation. Mikään operaatio ei tee muutoksia tietokannan relaatioiden rakenteeseen tai sisältöön. Alla on kuvattu relaatioalgebran kahdeksan perusoperaatiota.
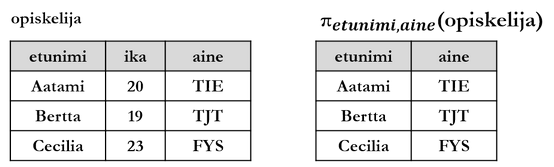
3.3.1 Projektio
Projektiolla (projection) valitaan relaation R otsakkeesta halutut attribuutit tulosrelaatioon. Tulosrelaation monikkoihin hyväksytään relaation R monikkojen attribuuttien arvoista vain sellaiset, joiden nimi on projektiossa lueteltu. Tulosrelaatiosta poistetaan samanlaiset monikot.
")
Jossa a1...an on pilkkulista haluttujen attribuuttien nimistä.
3.3.2 Valinta
Valinnassa (restriction tai selection) tulosrelaatio muodostetaan valitsemalla relaatiosta R ehtolausekkeen tai ehtolausekkeet tyydyttävät monikot.
")
Jossa:
- a on attribuutin nimi,
- θ on vertailuoperaattori kuten
>,<tai=ja - v on vakio tai attribuutin nimi.
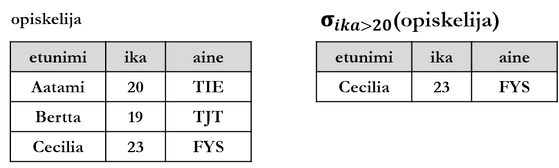
ika > 20.3.3.3 Yhdiste
Yhdisteellä (union) muodostetaan kahden relaation R ja S kaikki monikot sisältävä tulosrelaatio. Tulosrelaatiosta poistetaan samanlaiset monikot.

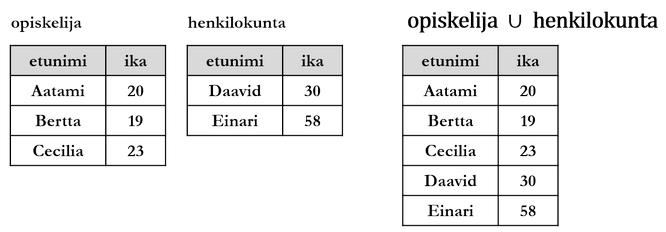
3.3.4 Leikkaus
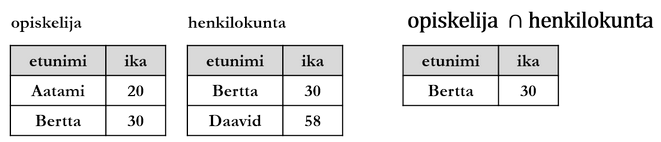
Leikkauksella (intersection) muodostetaan tulosrelaatio, joka sisältää relaatioiden R ja S sellaiset monikot, jotka esiintyvät sekä R:ssä että S:ssä.

3.3.5 Erotus
Erotuksella (difference) muodostetaan tulosrelaatio, joka sisältää ne relaation R monikot, joita ei ole relaatiossa S.


3.3.6 Liitos
Liitoksessa (join) tulosrelaatio on kahden relaation R ja S yhdiste kuitenkin niin, että tulosrelaatioon valitaan vain ehtolausekkeen tai ehtolausekkeet tyydyttävät monikot.

Jossa
- a on relaation R attribuutin nimi,
- b on relaation S attribuutin nimi ja
- θ on vertailuoperaattori.

Kuviossa esitetyn esimerkin mukaista liitosta (=-operaattorilla tehtyä liitosta) kutsutaan yhtäläisyysliitokseksi (equijoin). Relaatioiden väliset liitokset muodostetaan tavallisesti viiteavainten avulla.
3.3.7 Jako
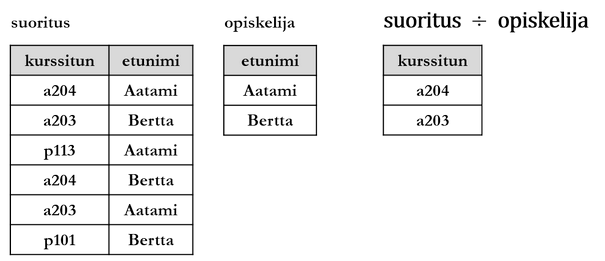
Jako-operaatiolla (division) muodostetaan tulosrelaatio, jonka otsakkeena ovat sellaisten attribuuttien nimet, jotka sisältyvät relaation R otsakkeeseen mutta eivät relaation S. Tulosrelaation osamonikkoina ovat sellaiset R:n monikot, jotka ovat jokaisen S:n monikon parina relaatiossa R.

3.3.8 Ristitulo
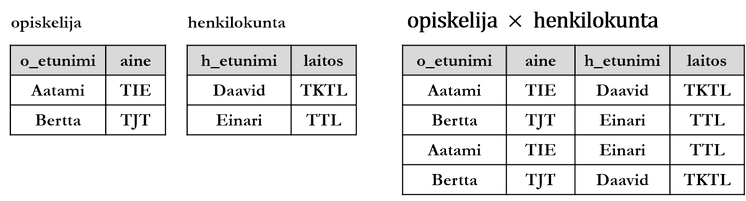
Ristitulo (cross join, cross product tai Cartesian product) on kahden relaation R ja S karteesinen tulo. Tulosrelaation monikoiden lukumäärä on R:n ja S:n monikoiden lukumäärän tulo ja tulosrelaation asteluku R:n ja S:n astelukujen summa.

)")
Relaatioalgebran lisäksi relaatiomalli esittelee toisen kyselykielen: relaatiokalkyylin (relational calculus). Relaatiokalkyyli on rakenteeltaan relaatioalgebraa deklaratiivisempi ja lähempänä käytännön sovellutuksia kuten SQL:ää.
4. SQL
SQL (Structured Query Language tai SQL Query Language) on ANSI/ISO-standardiin perustuva rakenteinen kyselykieli datan etsimiseen ja noutamiseen tietokannasta. Standardin laajentuessa SQL on laajentunut datan etsimisestä mm. datan lisäämiseen, poistamiseen ja muokkaamiseen, tietokannan rakenteen määrittelyyn, käyttöoikeuksien määrittämiseen ja tapahtumankäsittelyn hallintaan.
SQL-kieli on deklaratiivinen: hakulauseella kuvataan sitä, mitä tietoa tietokannasta halutaan noutaa, ja tietokannanhallintajärjestelmän optimoijakomponentti päättää, miten tieto haetaan. Kieli suunniteltiin alunperin siten, että yksinkertaisten operaatioiden suorittaminen olisi vaivatonta ohjelmointikieliin nähden. Alla on esimerkki tietorakenteen sisällön noutamisesta deklaratiivisella (SQL) ja imperatiivisella (Java) kielellä.
4.1 Yleistä SQL-kielestä
Relaatiomalli on SQL-standardin teoreettinen perusta, mutta standardi eroaa relaatiomallista joiltakin osin. Esimerkiksi relaatiomalli vaatii, että relaation jokainen rivi on erilainen. SQL:ssä puolestaan taulun rivien ei tarvitse olla erilaisia, jos perusavainta ei määritetä. SQL:n sanotaan olevan relaationaalisesti täydellinen, ts. se on ilmaisuvoimaltaan niin vahva, että kielen avulla voidaan toteuttaa relaatioalgebran mukaiset operaatiot. Alla olevassa taulukossa on kuvattu relaatiomallissa käytetyt termit ja niiden suurpiirteinen vastaavuus SQL:ään.
| Relaatiomalli | SQL |
|---|---|
| Relaatio (relation) | Taulu (table) |
| Attribuutti (attribute) | Sarake (column) |
| Monikko (tuple) | Rivi (row) |
Eri tietokannanhallintajärjestelmät (ts. tuotteet) toteuttavat SQL-standardia omilla tavoillaan tuoden omia toiminnallisia ja syntaktisia lisämausteitaan. Jotkin tuotteet puolestaan jättävät SQL-standardin osia toteuttamatta. Voidaankin sanoa, että jonkin tuotteet SQL-rajapinta on relaatiomallin sovelluksen sovellus. Eri tietokannanhallintajärjestelmien SQL-toteutuksia sanotaan SQL-murteiksi.
SQL-standardin mukaan SQL koostuu neljästä eri kielestä:
- Datan hallinta (Data Management Language, DML)
- Rakenteen määrittäminen (Data Definition Language, DDL)
- Valtuuttaminen (Data Control Language, DCL)
- Tapahtumanhallinta (Transaction Control Language, TxCL)
Tavallisesti relaatiotietokannanhallintajärjestelmissä (relational database management system, RDBMS) kaikkia neljää kieltä käytetään saman rajapinnan kautta, mutta esimerkiksi käyttöoikeuksien määrittäminen ja tapahtumanhallinta perustuvat vahvasti esitettyyn nelijakoon. Näitä osa-alueita käsitellään myöhemmin.
4.2 SQL-lauseet
SQL-lauseeksi kutsutaan SQL-avainsanoista, tietokantaobjektien nimistä ja muuttujien arvoista koostuvaa kokonaisuutta. Rivityksellä ei ole merkitystä, vaan SQL-lauseen päättää puolipiste ;. Kirjainkoolla ei ole merkitystä: SQL-avainsanat ja tietokantaobjektien nimet voidaan kirjoittaa suuraakkosilla tai pienillä kirjaimilla. Tässä materiaalissa SQL-avainsanat on kirjoitettu suuraakkosilla hyvän käytänteen ja selkeyden vuoksi.
Taulujen, sarakkeiden, esiteltyjen muuttujien ja tarkentimien sekä muiden tietokantaobjektien nimissä voidaan käyttää kirjaimia, numeroita ja alaviivaa. Välilyöntiä ei sallita, eikä nimi voi alkaa numerolla. Myös varattuja SQL-avainsanoja ei sallita nimissä. Yleisiä SQL-avainsanoja ovat mm.
| ¨ | ||||
|---|---|---|---|---|
| AS | COPY | FROM | IN | ON |
| LIKE | NOT | MIN | MAX | NULL |
| DROP | INTO | SELECT | SUM | LOCK |
| MOVE | BEGIN | AND | OR | SET |
| WHERE | TRUE | WITH | FALSE | GRANT |
| REVOKE | DELETE | TO | OUT | USER |
4.3 DML
Datan hallintakieli (Data Management Language, DML) muodostaa suuren osan SQL-kielestä. Sen avulla tietokannasta voidaan mm. etsiä SELECT, lisätä INSERT, muokata UPDATE ja poistaa DELETE dataa. Seuraavaksi tarkastellaan näitä neljää komentoa.
4.3.1 Luentoesimerkkien tietokanta
Seuraavat osiot sisältävät interaktiivisia tehtäviä. Voit kokeilla ajaa valmiiksi kirjoitettuja SQL-lauseita ja voit myös muokata niitä. Hakulauseiden luentoesimerkkien tietokannanhallintajärjestelmä on SQLite.
Kokeile alkuun tietokannan toimivuutta alla olevalla interaktiivisella tehtävällä. Painamalla alla olevan esimerkin Aja-painiketta luentoesimerkkien tietokanta ladataan ja tulosteena näytetään kaikki tietokannassa olevien taulujen nimet.
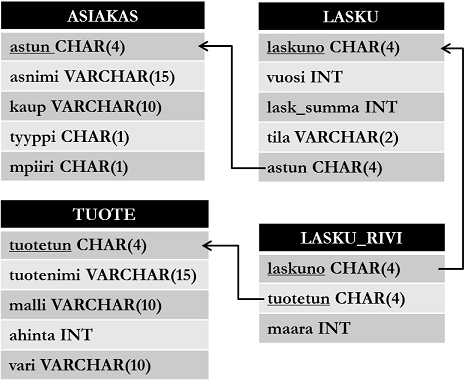
Alla on esitetty interaktiivisissa esimerkeissä käytetyn tietokantasi kaava eli skeema.
Voit tarkastella tietokannan luomiseksi käytettyä koodia osoitteesta
https://tim.jyu.fi/files/kurssit/tie/itka2004/kurssimoniste/sqlite_luentoesim.sql
Tietokannassa on neljä taulua: asiakas, tuote, lasku ja lasku_rivi. Taulujen nimi on esitetty suorakulmion ensimmäisellä rivillä ja taulun sarakkeiden nimet tietotyyppeineen seuraavilla. Viiteavaimet on esitetty viivoilla. Kunkin taulun rivi kuvastaa seuraavaa tietoa:
- Asiakkaalla (
astun) on nimi (asnimi), asuinkaupunki (kaup), asiakkuuden tyyppi (tyyppi) joukosta {'y' = yritysasiakas, 'h' = henkilöasiakas} ja myyntipiiri (mpiiri) joukosta {'i' = itä, 'l' = länsi, 'e' = etelä, 'p' = pohjoinen, 'k' = keski}. - Tuotteella (
tuotetun) on nimi (tuotenimi), malli (malli), yksikköhinta (ahinta) ja väri (vari). - Laskulla on laskunumero (
laskuno), laskutusvuosi (vuosi), laskun yhteissumma (lask_summa), tila (tila) joukosta {'m' = maksettu, 'l' = laskutettu, 'k' = karhuttu} sekä asiakas, jota on laskutettu (astun). - Lasku_rivi kuvaa mitä tuotetta (
tuotetun) on laskutettu milläkin laskulla (laskuno) ja kuinka monta kappaletta (maara).
4.3.2 Yhteen tauluun kohdistuvat hakulauseet
Tarkastellaan ensin yhteen tauluun kohdistuvia hakulauseita, hakulauseen yleistä muotoja ja erilaisia ehtolausekkeita.
4.3.2.1 Hakulauseen yleinen muoto
SQL-hakulause eli SELECT-lause koostuu yksinkertaisimmillaan kahdesta osasta. SELECT-osassa luetellaan pilkkulistalla ne sarakkeet, joiden arvoja tulostauluun halutaan. Tulostaulun otsake (header) muodostuu tämän listan perusteella. Ensimmäiseksi luetellusta sarakkeesta tulee tulostaulun vasemmanpuoleinen sarake jne. FROM-osassa luetellaan pilkkulistalla ne taulut, joista tietoa etsitään. FROM-osan sisältöä kutsutaan myös taulujen esittelyksi.
Kyselyn voisi lukea auki myös näin: "Hae asiakas-taulun astun-, asnimi-, kaup-, tyyppi- ja mpiiri-sarakkeiden arvot".
4.3.2.2 Ehtolausekkeet ja tulosten rajaus
Hakulauseen yleinen muoto SELECT...FROM...; noutaa taulusta kaikki rivit. Kun tuloksia halutaan rajata, käytetään ehtolausekkeita, jotka sijoitetaan lauseen WHERE-osaan. WHERE-osa sijoittuu FROM-osan jälkeen:
4.3.2.2.1 Vertailuoperaattorit
Vertailuoperaattoreita ovat =, <, >, >=, <=, <>, !=, joista kaksi viimeistä tarkastavat erisuuruutta. Tähteä * voidaan käyttää kuvaamaan taulun kaikkia sarakkeita alla olevan esimerkin mukaisesti.
Mitäpäs olen jättänyt tekemättä, saan Error - viestiä “Error: near line 1: no such table: tuote”
—T: tuolta n. sivun verran ylempää pitäisi ajaa kolme laatikkoa, joilla luodaan harjoitustietokanta. Valitettavasti kanta joskus jostain syystä häviää.
—Jees, homma pelittää. Kiitoksia!
—Ehtolausekkeita voidaan yhdistää toisiinsa loogisilla operaattoreilla AND (ja) ja OR (tai) sekä edelleen sulkeilla. Jos lauseen WHERE-osassa käytetään vain AND-operaattoreita, ehtolausekkeiden järjestyksellä ei ole tulosten kannalta merkitystä.
Olis tosi kova juttu, jos tässä kohtaa olisi joku esimerkki (koodinpätkä) että miten nuo sulkeet toimii käytännössä. :)
—T: lisäsin hieman alemmaksi, heti LIKE:n esittelyn jälkeen!
—4.3.2.2.2 Merkkijonojen vertailu
Merkkijonojen vertailuun voidaan käyttää vertailuoperaattoreita tai [NOT] LIKE -predikaattia. Vertailtava merkkijono kirjoitetaan heittomerkkien ' sisään. Kirjainkoolla heittomerkkien sisällä on tavallisesti merkitystä, kuitenkin tuotteesta ja sen asetuksista riippuen. SQLitessä oletusarvoisesti kirjainkoolla ei ole merkitystä.
LIKE-predikaattia käytettäessä voidaan käyttää lisäksi seuraavia jokerimerkkejä:
- Alaviiva
_vastaa yhtä mitä tahansa merkkiä. - Prosenttimerkki
%vastaa 0..n kappaletta mitä tahansa merkkiä. Ts. prosenttimerkki vastaa mitä tahansa merkkijonoa (myös tyhjää).
Tehtävä: Muuta yllä olevaa SQL-hakulausetta siten, että se hakee kaikkien K:lla ja L:llä alkavien asiakkaiden nimet, joiden nimi ei kuitenkaan lopu merkkijonoon Oy.
Kuten aritmeettiset operaatiot, jotkin operaattorit ovat SQL:ssä etuoikeutetumpia kuin toiset. Esimerkiksi siinä missä tulo lasketaan ennen summaa, SQL:ssä AND tarkastetaan ennen OR-operaattoria. Jos halutaan tarkastaa OR ennen AND-operaattoria, lauseen suoritusjärjestystä voidaan ohjata sulkeilla kuten matematiikassa, eli sulkeiden sisällä olevat asiat suoritetaan ensin. Oletetaan seuraava tietotarve:
Yllä olevassa lauseessa suoritusjärjestys on ohjattu sulkeilla: ensin tarkastetaan, että tuotenimi on kumpi kumpi halutuista (OR), ja sitten onko hinta jompi kumpi halutuista (OR), ja lopuksi, että sekä nimen että hinnan ehdot pätevät (AND).
Jos sulkeita ei käytettäisi, muuttuisi lauseen logiikka seuraavilla tavoilla:
- Jos jätetään pois kaikki sulkeet, hyväksytään sellaiset tuotteet, joiden nimi alkaa t-kirjaimella. Hyväksytään myös sellaiset tuotteet, joiden nimi alkaa s-kirjaimella ja joiden hinta on yli 200. Hyväksytään myös sellaiset tuotteet, joiden hinta on alle 20.
- Jos jätetään pois ainoastaan alemmat sulkeet eli hinnan tarkastukset ympäröivät sulkeet, hyväksytään sellaiset tuotteet, joiden nimi alkaa t- tai s-kirjaimella, ja joiden hinta on yli 200. Hyväksytään myös sellaiset tuotteet, joiden hinta on alle 20.
- Jos jätetään pois ainoastaan ylemmät sulkeet eli tuotenimen tarkastukset ympäröivät sulkeet, hyväksytään sellaiset tuotteet, joiden nimi alkaa t-kirjaimella. Hyväksytään myös sellaiset tuotteet, joiden nimi alkaa s-kirjaimella ja joiden hinta on yli 200 tai alle 20.
4.3.2.2.3 Tyhjäarvon vertailu
Tyhjäarvo ei ole varsinaisesti arvo, vaan merkintätapa tuntemattomalle arvolle. Jos tyhjäarvoa yritetään vertailla vertailuoperaattoreilla, palautetaan aina tyhjäarvo. Tähän asti ehtolausekkeita on tarkasteltu kaksiarvoisen logiikan mukaisesti, esim. ehtolauseke ahinta > 100 palauttaa joko arvon TRUE (tosi) tai FALSE (epätosi) riippuen siitä, mikä arvo rivin ja sarakkeen leikkauskohdassa on. Tyhjäarvon johdosta SQL toimii kolmiarvoisella logiikalla seuraavan totuustaulun mukaisesti.
| p | q | p AND q | p OR q |
|---|---|---|---|
| TRUE | TRUE | TRUE | TRUE |
| TRUE | FALSE | FALSE | TRUE |
| FALSE | FALSE | FALSE | FALSE |
| TRUE | UNKNOWN | UNKNOWN | TRUE |
| FALSE | UNKNOWN | FALSE | UNKNOWN |
SQL:ssä tyhjäarvoa kuvataan avainsanalla NULL. Tyhjäarvon esiintymistä tarkastetaan predikaatilla IS [NOT] NULL, ei koskaan vertailuoperaattorilla.
4.3.2.2.4 Muita tapoja vertailuun
Vertailuoperaattoreiden ja LIKE-predikaatin lisäksi SQL-standardissa on muita, tilanteesta riippuen vaivattomampia tapoja vertailuun. [NOT] IN -predikaatilla voidaan tarkastaa, kuuluuko arvo johonkin joukkoon. Sitä käyttäen voidaan esim. kiertää tilanteita, joissa muuten jouduttaisiin kirjoittamaan lukuisia, samaa saraketta koskevia vertailuja OR-operaattoria käyttäen. [NOT] IN -predikaatille annetaan hyväksyttävä arvojoukko sulkeiden sisään pilkkulistalla. Huomaa, että jokerimerkkien käyttö ei ole sallittua.
Tehtävä: muuta yllä olevaa esimerkkilausetta muotoon: "hae kouvolalaisten ja mikkeliläisten asiakkaiden kaikki tiedot". Käytä IN-predikaattia.
[NOT] BETWEEN -predikaatti tarkastaa, onko sarakkeen arvo halutulla välillä. Syntaksi on sarake BETWEEN arvo1 AND arvo2, jossa arvo1 on pienempi ja arvo2 suurempi. Predikaatilla voidaan vertailla myös merkkijonoja ja päivämääriä. Huomaa, että myös raja-arvot hyväksytään tuloksiin.
4.3.2.3 Tulosten järjestäminen
Tähän asti käsitellyissä esimerkeissä tulostaulun rivien järjestys on ollut tietokannanhallintajärjestelmän päättämä. Tulostaulun voi järjestää mieleisekseen ORDER BY -määreellä. Se sijoittuu tähän mennessä käsiteltyjen lauseenosien jälkeen:
Tulostaulu voidaan järjestää sen kaikkien sarakkeiden mukaan, tai vain osan. Jos ORDER BY -määrettä käytetään, sarakkeen arvot järjestetään oletusarvoisesti nousevaan järjestykseen (ASC eli ascending). Järjestys voidaan kääntää laskevaan järjestykseen lisämääreellä DESC (descending).
4.3.3 Useaan tauluun kohdistuvat hakulauseet
Tähän mennessä käsitellyt hakulauseet ovat kohdistuneet yhteen tauluun kerrallaan. On kuitenkin tavallista, että tuloksia halutaan rajata edelleen, jolloin ehtolausekkeita täytyy kohdistaa useampaan kuin yhteen tauluun.
Tärkein useamman kuin yhden taulun käsittelyyn liittyvä käsite on liitosehto. Liitosehdon avulla tarkastetaan, löytyykö kahdesta eri taulusta sama sarakkeen arvo. Liitos taulujen välillä sijoitetaan lauseen WHERE-osaan, ja se voidaan toteuttaa eri tavoin. Seuraavaksi tarkastellaan erilaisia tapoja toteuttaa liitosehto.
4.3.3.1 Liitos IN-predikaattia käyttäen
Yksi tapa toteuttaa liitos on ns. alikyselyllä, jolloin lauseen WHERE-osassa aloitetaan uusi, SELECT-käskyllä alkava hakulause. Liitosehto voidaan toteuttaa IN-predikaattia käyttäen. Kiinnitä huomiota siihen, mikä taulu esitellään missäkin FROM-osassa:
Tarkastellaan tarkemmin, mitä yllä olevassa lauseessa tapahtuu. Tietokannan tuote-taulussa on listattuna kaikkien tietokannassa olevien tuotteiden tiedot. Tietokannan lasku_rivi-taulussa on puolestaan listattuna sellaisten tuotteiden tuotetunnukset, joita koskee jokin lasku, ts. joista on joskus laskutettu jotakuta asiakasta. Toisin sanoen, tuote-taulussa on tallennettuna kaikki tuotteet, mutta lasku_rivi-taulussa vain tuotteiden tuotetunnuksien osajoukko.
IN-predikaatista muistamme, että sillä tarkastetaan, kuuluuko vertailtavan sarakkeen arvo johonkin joukkoon. Tässä IN-predikaatin oikealle puolelle ei olekaan asetettu pilkkulistaa hyväksyttävistä arvoista, vaan alikysely. IN-predikaatin vasemmalla puolella on tuote-taulun tuotetun-sarakkeen arvo, oikealla puolella puolestaan lasku_rivi-taulun tuotetun-sarakkeen arvo. Kyselyn voisi lukea auki myös näin: "Hae sellaisten tuotteiden tuotenimet, joiden tuotetunnus on tallennettu myös lasku_rivi tauluun" tai "Hae sellaisten tuotteiden tuotenimet, joiden tuotetunnus esiintyy ainakin kerran lasku_rivi-taulussa" tai "Hae sellaisten tuotteiden tuotenimet, joista on laskutettu ainakin kerran".
Miten lause sitten suoritetaan? Alikyselyä voisi ajatella kahtena sisäkkäisenä silmukkana:
- Valitaan tuote-taulun ensimmäiseltä riviltä tuotetun-sarakkeen arvo x.
- Verrataan x:ää lasku_rivi-taulun ensimmäisen rivin tuotetun-sarakkeen arvoon y.
- Jos ehtolauseke x = y saa arvokseen
TRUE(ts. arvot ovat samat), sijoitetaan tuote-taulun x:ää vastaavan rivin tuotenimi-sarakkeen arvo tulostauluun. Siirrytään kohtaan 3. - Jos ehtolauseke x = y saa arvokseen jotakin muuta (
FALSEtaiUNKNOWN), tarkastetaan lasku_rivi-taulun seuraavan rivin sarakkeen tuotetun-arvo, ja verrataan sitä x:ään. Jos lasku_rivi-taulun miltään riviltä ei löydy x:ää vastaavaa arvoa, siirrytään kohtaan 3.
- Jos ehtolauseke x = y saa arvokseen
- Valitaan tuote-taulun seuraavalta riviltä tuotetun-sarakkeen arvo x ja siirrytään kohtaan 2., kunnes tuote-taulun viimeinenkin rivi on tarkastettu.
- Materialisoidaan tulostaulu.
Liitosehdoilla voidaan saman periaatteen mukaan toteuttaa monimutkaisempiakin kyselyitä. Esimerkiksi alla oleva, luonnollisella kielellä esitetty hakulause voi tietokannan rakenteesta riippuen näyttää SQL:llä esitettynä monimutkaiselta:
Yllä olevan lauseen voisi lukea auki myös näin: "Hae sellaisten asiakkaiden nimet ja tyypit, joiden asiakastunnus on tallennettu myös lasku-tauluun, ja vastaavan lasku-taulun rivin laskuno-sarakkeen arvo on tallennettu myös lasku_rivi-tauluun, ja vastaavan lasku_rivi-taulun rivin tuotetun-sarakkeen arvo on tallennettu myös tuote-tauluun, ja tuotetaulussa vastaavan rivin tuotteen väri on musta".
"Hae sellaisten asiakkaiden nimet ja tyypit,":
"…joiden asiakastunnus on tallennettu myös lasku-tauluun,":
"…ja vastaavan lasku-taulun rivin laskuno-sarakkeen arvo on tallennettu myös lasku_rivi-tauluun,":
"…ja vastaavan lasku_rivi-taulun rivin tuotetun-sarakkeen arvo on tallennettu myös tuote-tauluun,":
"…ja tuotetaulussa vastaavan rivin tuotteen väri on musta":
Miten useaa taulua käsittävää hakulausetta voisi lähteä suunnittelemaan?
- Ensin on syytä tarkastella tietokannan kaavaa ja tunnistaa ne taulut, joista tietoa halutaan tulostauluun (yllä olevassa esimerkissä asiakas-taulu).
- Seuraavaksi etsitään ne taulut, joiden sarakkeisiin täytyy kohdistaa ehtolausekkeita (tässä tapauksessa tuote-taulu), tällaisia ehtolausekkeita kutsutaan myös sisällöllisiksi ehdoiksi.
- Seuraavaksi tarkastellaan, mitä muita tauluja mahdollisesti tarvitaan, jotta jo kyselyn kannalta relevanteiksi luokitellut taulut voidaan liittää liitosehdoilla.
- Lopuksi ennen varsinaisen lauseen kirjoittamista täytyy tunnistaa, millä sarakkeilla liitosehdot voidaan tehdä. Esimerkiksi tässä tapauksessa asiakas- ja tuote-taulua ei voida edes teoriassa liittää suoraan toisiinsa, sillä niissä ei ole yhtäkään yhteistä saraketta.
4.3.3.2 Liitos EXISTS-predikaattia käyttäen
Alikyselyyn perustuva liitos voidaan tehdä myös käyttämällä EXISTS-predikaattia. Syntaksi eroaa hieman IN-predikaatista, sillä varsinainen liitosehto tehdään vasta alikyselyn WHERE-osassa. EXISTS-predikaatilla tarkastetaan, onko ehdot täyttäviä rivejä olemassa. Jos alikysely tuottaa totuusarvon TRUE edes yhdelle riville, valitaan pääkyselyssä esitellystä taulusta vastaavan rivin halutun sarakkeen arvo tulostauluun.
Alikyselyt tuovat mukanaan uuden käsitteen: näkyvyysalueen. Näkyvyysalueella tarkoitetaan SQL-lauseessa sitä, missä kohdassa lausetta jonkin sarakkeen tai taulun nimeä voidaan käyttää. Alikyselyssä esiteltyihin tauluihin tai niiden sarakkeisiin ei voi viitata ylemmän tason kyselyssä, mutta ylemmän tason kyselyssä esiteltyihin tauluihin ja niiden sarakkeisiin voidaan viitata alikyselyssä. Toisin sanoen, pääkysely ei ole tietoinen lasku_rivi-taulusta, mutta alikysely on tietoinen lasku_rivi-taulun lisäksi pääkyselyssä esitellystä tuote-taulusta.
Näkyvyysalueet ja useamman kuin yhden taulun esittely tuovat mukanaan ongelman: viitattaessa tuotetun-sarakkeeseen tietokannanhallintajärjestelmä ei tiedä, tarkoitetaanko lauseessa tuote- vai lasku_rivi-taulun tuotetun-saraketta. Tästä syystä on käytettävä tarkentimia (correlation name). Tarkentimena voi käyttää taulun nimeä, kuten yllä, tai sen voi esitellä itse lauseen FROM-osassa syntaksilla:
Itse määritelty tarkennin voi olla mikä tahansa nimeämissääntöjä noudattava merkkijono. Itse määritelty tarkennin voi vähentää kirjoitustyötä huomattavasti. Esimerkiksi yllä esitetty esimerkki voitaisiin kirjoittaa myös omia tarkentimia käyttäen:
Yllä olevan esimerkin pääkyselyn SELECT-osassa tarkentimen t käyttö ei ole välttämätöntä, koska tuotenimi-niminen sarake on vain tuote-taulussa. Koska liitosehto tehdään alikyselyn WHERE-osassa, EXISTS-predikaatilla toteutetun alikyselyn SELECT-osan sisällöllä ei ole merkitystä. Tavallisesti käytetään tähtimerkkiä tai yhtä numeroa.
4.3.3.3 Liitos vertailuoperaattoria käyttäen
Kahden tai useamman taulun liitos voidaan tehdä myös ilman alikyselyä. Yksi tapa liitoksen tekemiseen ilman alikyselyä on vertailuoperaattorin käyttäminen. Tällaista liitosta kutsutaan yksitasoiseksi tai implisiittiseksi liitokseksi.
Kuten aikaisemmin esitellyissä liitoksissa IN- ja EXISTS-predikaatteja käyttäen, yllä olevassa lauseessa tarkastetaan, vastaako tuote-taulun tuotetun-sarakkeen arvo jotakin lasku_rivi-taulun tuotetun-sarakkeen arvoa. Koska lasku_rivi-taulussa sama tuotetun-sarakkeen arvo voi kertautua ja tässä tapauksessa kertautuu, tulostauluun valitaan toisteisia rivejä. Toisteiset rivit on poistettu tulostaulusta DISTINCT-lisämääreellä. DISTINCT-lisämääre sijoitetaan lauseen SELECT-osaan heti SELECT-avainsanan jälkeen kuten yllä.
4.3.3.4 Sisäliitos
Sisäliitos on SQL-standardin kolmannessa versiossa (SQL-92) lisätty tapa toteuttaa liitoksia. Sisäliitosta kutsutaan myös eksplisiittiseksi liitokseksi, ja se toteutetaan JOIN -predikaatilla seuraavan syntaksin mukaisesti:
Aikaisemmissa esimerkeissä IN- ja EXISTS-predikaateilla sekä vertailuoperaattoria käyttämällä toteutettu kysely näyttäisi eksplisiittisellä liitoksella toteutettuna seuraavalta:
4.3.3.5 Yhdiste
Yhdisteen UNION avulla voidaan liittää kahden tai useamman hakulauseen tulostaulut toisiinsa. Hakulauseiden tulostauluissa tulee olla yhtä monta saraketta.
Edellisessä esimerkissä on myös esitelty uusi SQL-avainsana AS. Sen avulla voidaan mm. nimetä uudelleen tulostaulun sarakkeita. Yllä olevassa esimerkissä tulostaulun ainoalle sarakkeelle on annettu nimi mallit_ja_tuotenimet. AS-predikaatti on käyttökelpoinen erityisesti, kun tulostaulussa on koostefunktioiden tuottamia sarakkeita. Koostefunktioita käsitellään myöhemmin.
4.3.4 Koostefunktiot
Koostefunktioita (set tai aggregate function) käytetään laskutoimitusten suorittamiseen, niille annetaan tavallisesti yksi parametri ja ne palauttavat yhden arvon. Koostefunktiot sijoitetaan hakulauseessa SELECT- tai HAVING-osaan. HAVING esitellään myöhemmin. Seuraavaksi esitellään tavallisimmat koostefunktiot summa, lukumäärä, minimi, maksimi ja keskiarvo.
4.3.4.1 Summa ja lukumäärä
Koostefunktio summa SUM laskee ja palauttaa sarakkeessa esiintyvien arvojen summan. SUM käsittelee tyhjäarvoa NULL kuten nollaa, ts. 1 + 0 + 3 = 4 ja 1 + NULL + 3 = 4. Seuraavassa esimerkissä koostefunktiolle on annettu parametriksi tuote-taulun ahinta-sarake, ja tulostaulun ainoa sarake on nimetty AS-predikaatilla. Jos saraketta ei nimetä AS-predikaatilla, tietokannanhallintajärjestelmä nimeää sarakkeen.
Koostefunktio lukumäärä COUNT laskee ja palauttaa arvojen lukumäärän. COUNT ei laske tyhjäarvoja. Seuraavassa esimerkissä on laskettu asiakas-taulun rivien lukumäärä käyttämällä koostefunktion parametrina tähteä.
Silloin tällöin pelkkä arvojen esiintymien lukumäärän laskeminen ei tuota haluttua tulosta, sillä oletusarvoisesti COUNT-koostefunktio laskee arvot riippumatta siitä, mikä arvo on. Jos halutaan laskea erilaisten arvojen määrä, voidaan käyttää DISTINCT-lisämäärettä.
Yllä oleva esimerkki laskee toisin sanoen asiakas-taulun kaup-sarakkeessa esiintyvien erilaisten arvojen lukumäärän.
Tehtävä: kokeile ajaa yllä oleva lause ilman DISTINCT-lisämäärettä. Miksi tulos muuttuu? Mihin tulos perustuu?
4.3.4.2 Minimi, maksimi ja keskiarvo
Koostefunktio minimi MIN palauttaa sarakkeessa esiintyvän pienimmän arvon, koostefunktio maksimi MAX puolestaan suurimman. Seuraavassa esimerkissä on laskettu koostefunktioiden palauttamien arvojen erotus.
Koostefunktio keskiarvo AVG laskee sarakkeen arvojen keskiarvon. Koostefunktio AVG laskee summan kuten SUM-koostefunktio, lukumäärän kuten COUNTkoostefunktio ja palauttaa näiden osamäärän.
4.3.4.3 Ryhmittely
Edellisen esimerkin SQL-kysely siis palauttaa kaikkien tuotteiden hintojen keskiarvon. Usein koostefunktioita halutaan kuitenkin käyttää monimutkaisempiin laskutoimituksiin, esimerkiksi tuotteiden hintakeskiarvojen laskemiseen tuoteväreittäin, ts. jokaista väriä kohden. Tällöin tarvitaan ryhmittelyä, joka tapahtuu GROUP BY -määreellä:
Ryhmittely vaaditaan, jos yksikin tulostaulun sarake on muodostettu koostefunktion avulla, ja tulostaulussa on lisäksi ainakin yksi projektiolla muodostettu sarake x (yllä olevassa esimerkissä sarake vari). Tällaista saraketta x kutsutaan ryhmitteleväksi sarakkeeksi. Jokainen ryhmittelyllä saavutettu tulostaulun ryhmä koostuu riveistä, jotka ovat ryhmittelevän sarakkeensa arvon suhteen samanlaisia. Yllä olevan esimerkin mukaisesti DBMS jakaa ensin tuote-taulun rivit ryhmiksi. Kukin ryhmä koostuu riveistä, joiden vari-attribuutin arvo on sama: esim. ensimmäiseen ryhmään kuuluvat rivit, jotka kuvaavat sinisiä tuotteita, toiseen ryhmään rivit, jotka kuvaavat punaisia tuotteita jne. Lopuksi lasketaan hintakeskiarvo erikseen jokaiselle ryhmälle ja materialisoidaan tulostaulu.
Ryhmitteleviä sarakkeita voi olla useampikin kuin yksi. GROUP BY -määreen käyttö vaaditaan, jos ainakin yksi tulostaulun sarake muodostetaan koostefunktiolla, ja ainakin yksi sarake ilman koostefunktiota (ts. ainakin yksi sarake on ryhmittelevä sarake). Tässä tapauksessa ryhmittely pitäisi tehdä jokaisen ryhmittelevän sarakkeen mukaisesti. GROUP BY -määre sijoittuu SQL-hakulauseessa heti lauseen WHERE-osan jälkeen. SQL-hakulauseen yleinen syntaksi näyttää siis tähän mennessä seuraavalta:
Tehtävä: Muuta yllä olevaa SQL-hakulausetta siten, että se hakeekin tuotteiden yksikköhintojen summan väreittäin ja malleittain. Rajaa pois tuotteista sellaiset, joiden hintaa ei ole määritetty. Tulokset järjestetään ensin värin ja sitten mallin mukaiseen, laskevaan aakkosjärjestykseen.
Silloin tällöin ryhmiteltyjä tuloksia täytyy rajata. Koostefunktion ja ryhmittelyn yhdistelmällä tuotettujen tulostaulun rivien määrää voidaan rajoittaa HAVING-predikaatilla. HAVING-osa sijoittuu lauseessa GROUP BY -osan jälkeen, mutta kuitenkin ennen mahdollista ORDER BY -osaa:
HAVING-osa toimii näennäisesti hieman samalla tavalla kuin aikaisemmin käsitelty WHERE-osa: siihen sijoitettujen ehtolausekkeiden avulla voidaan rajata kyselyn tuloksia. HAVING-osa eroaa kuitenkin WHERE-osasta seuraavilta osin:
HAVING-osaan voidaan sijoittaa koostefunktioita, toisin kuinWHERE-osaan.HAVING-osa suoritetaan vasta ryhmittelyn jälkeen, kun taasWHERE-osa suoritetaan ennen ryhmittelyä.- Edelliseen liittyen,
HAVING-osa vaatii ainaGROUP BY-osan.
4.3.5 Tyypillisiä ongelmia
Tarkastellaan ennen lisäämistä, poistamista ja muokkaamista käsittelevään osioon siirtymistä SQL-hakulauseiden tyypillisiä ongelmia, jotka vaikuttavat luonnollisella kielellä yksinkertaisilta.
4.3.5.1 Ei ole olemassa -tapaus
Silloin tällöin tuloksiin halutaan taulun sellaiset rivit, joihin viittaavia arvoja ei löydy jostakin muusta taulusta. Vertailuun voidaan käyttää NOT IN- tai NOT EXISTS -predikaattia:
NOT IN-predikaatti tarkastaa, onko yhtään vastaavaa riviä olemassa. Jos yksikin rivi täyttää alikyselyn ehdot (yllä olevassa esimerkissä siis sekä liitosehto että sisällöllinen ehto vuosi = 2011), ei pääkyselyn vastaavaa riviä hyväksytä tulostauluun. Yllä oleva lause voitaisiin lukea myös näin: "Hae sellaisten asiakkaiden asiakastunnukset ja nimet, joiden asiakastunnus ei ole lasku-taulussa yhdelläkään sellaisella rivillä, jossa laskun vuosi on 2011".
Sama kysely voidaan toteuttaa myös NOT EXISTS-predikaatilla. NOT EXISTS-predikaatin toiminta noudattaa kaksiarvoista (TRUE, FALSE) logiikkaa, ja tyhjäarvon vertailu tuottaa aina totuusarvon epätosi. Lauseiden syntaksi eroaa samoin kuin IN- ja EXISTS-predikaattien:
On syytä huomata, että ei ole olemassa -tapausta ei voida esittää ilman alikyselyä, ns. yksitasoisesti.
Alla on esitetty yleinen virhe ei ole olemassa -tapauksen käsittelystä.
Yllä oleva lause ei siis vastaa vaatimukseen "Hae sellaisten asiakkaiden asiakastunnukset ja nimet, joita ei ole koskaan laskutettu vuonna 2011." vaan vaatimukseen "Hae sellaisten asiakkaiden asiakastunnukset ja nimet, joita on laskutettu ainakin kerran jonakin muuna vuonna kuin 2011".
4.3.5.2 Alikyselyn tulosten vertailu vakioon
Alikyselyn tuloksia voidaan vertailla vakioon vertailuoperaattoria käyttämällä.
Yllä olevan esimerkin voisi lukea näin: "Hae niiden lasku_rivi-taulun laskujen numerot, joita koskevan tuotteen tuotetunnus löytyy myös tuote-taulusta ja tämän tuotteen yksikköhinta on alle 10 euroa."
Tehtävä: Pohdi, voisiko edellisen kyselyn kirjoittaa ilman alikyselyn tuloksiin perustuvaa vertailua.
Seuraavassa esimerkissä vakiota 2 verrataan alikyselyn tuloksiin. Alikyselyn tulos on koostefunktion palauttama luku.
Tietokannanhallintajärjestelmä voisi suorittaa yllä olevan esimerkkilauseen seuraavalla tavalla.
- Valitaan asiakas-taulun ensimmäinen rivi asiakas1.
- Valitaan lasku-taulun ensimmäinen rivi lasku1.
- Verrataan lasku1:n ja asiakas1:n astun-sarakkeen arvoja toisiinsa.
- Jos ehtolauseke a.astun = l.astun saa arvokseen tosi, lisätään koostefunktion palauttamaa arvoa yhdellä ja siirrytään vertailemaan asiakas1:n astun-sarakkeen arvoa lasku1:n seuraavan rivin astun-sarakkeen arvoon.
- Jos ehtolauseke saa arvokseen epätosi tai tuntematon, siirrytään vertailemaan asiakas1:n astun-sarakkeen arvoa lasku1:n seuraavan rivin astun-sarakkeen arvoon.
- Kun kaikki asiakas1-rivin astun-sarakkeen arvoa on verrattu kaikkiin lasku-taulun astun-sarakkeen arvoihin, siirrytään kohtaan 4.
- Tarkastetaan ehtolauseke, jonka vasemmalla puolella on vakio 2 ja oikealla puolella koostefunktion
COUNTpalauttama kokonaisluku.- Jos ehtolauseke on tosi, hyväksytään asiakas1-rivin halutut sarakkeet (eli asnimi, kaup) tulostauluun.
- Jos ehtolauseke on epätosi, hylätään asiakas1-rivi.
- Valitaan asiakas-taulun seuraava rivi tarkasteltavaksi.
- Jos asiakas-taulussa on rivejä tarkastelematta, siirrytään kohtaan 2.
- Jos asiakas-taulussa ei ole rivejä tarkastelematta, siirrytään kohtaan 6.
- Materialisoidaan tulostaulu.
Alikyselyn tuloksia voidaan verrata myös sarakkeeseen. Seuraavassa esimerkissä alikyselyn tuloksia verrataan sarakkeeseen ahinta.
4.3.5.3 Saman taulun usea läpikäynti
Läpikäynnillä tarkoitetaan tässä yhteydessä taulun esittelyä hakulauseen FROM-osassa. Jos taulu halutaan tarkastaa useammin kuin kerran, on käytettävä apuna joko alikyselyiden mahdollistamia näkyvyysalueita tai useita tarkentimia.
Tietokannanhallintajärjestelmä voisi suorittaa yllä olevan hakulauseen esim. seuravaalla tavalla:
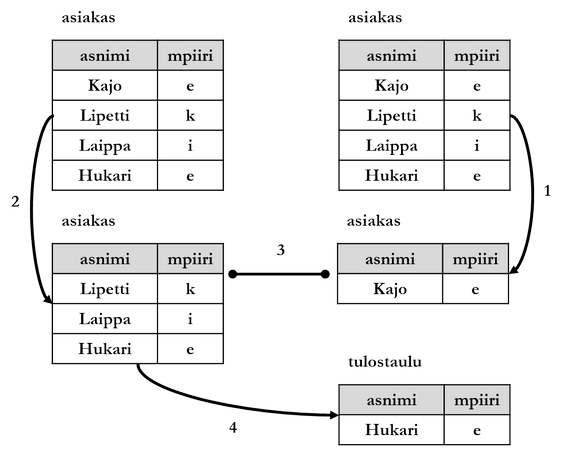
- Hylätään kaikki asiakas-taulun rivit, joilla asnimi-sarakkeen arvo ei ole Kajo (alikyselyn asiakas-taulun läpikäynti).
- Hylätään kaikki asiakas-taulun rivit, joilla asnimi-sarakkeen arvo on Kajo (pääkyselyn asiakas-taulun läpikäynti).
- Verrataan kahden läpikäynnin tuloksia (ts. niitä rivejä, joita ei ole hylätty) käyttäen liitosehtona mpiiri-sarakkeen arvoja. Ne rivit, joilla mpiiri on sama molempien läpikäyntien tuloksissa, valitaan pääkyselyn asiakas-taulusta asnimi- ja mpiiri-sarakkeiden arvot tulostauluun.
- Materialisoidaan tulostaulu.
Sama voidaan saavuttaa myös yksitasoisella ratkaisulla käyttämällä eri läpikäynneille eri tarkentimia. Alla olevassa esimerkissä tarkennin a1 vastaa yllä olevan esimerkin pääkyselyä ja tarkennin a2 alikyselyä:
4.3.5.4 Jako-operaatio
Jako-operaatiolle tyypillistä on tunnistaa, löytyykö liitosehdon muodostavan sarakkeen arvo liitoksen toisen puolen taulun jokaiselta riviltä. Relaatioalgebran operaatioilla jako-operaation voi toteuttaa joko NOT EXISTS-predikaatilla tai koostefunktioiden avulla. Alla esitellään tutkitusti (Matos & Grasser 2002) selkeämpi, koostefunktioilla toteutettu jako-operaatio.
Yllä oleva kysely vertaa laskunumeroittain lasku_rivi-taulun rivien määrää (ts. laskua koskevien erilaisten tuotetunnusten määrää) kaikkien tuotteiden lukumäärään.
4.3.6 Taulurivien lisääminen
Taulurivi lisätään komennolla INSERT. Komento lisää rivin tai rivejä yhteen tauluun. Komennon syntaksi on:
Alla olevassa esimerkissä lisätään tauluun asiakas uusi rivi. Rivin sarakkeiden nimet luetellaan INTO-osassa, ja VALUES-osassa määritetään uudelle riville sen sarakkeiden arvot. Sarakkeiden nimet voidaan luetella missä järjestyksessä tahansa, mutta VALUES-osan listan arvot asetetaan siinä järjestyksessä, kuin sarakkeiden nimet on INTO-osassa lueteltu. Jos lisäys (tai muokkaus tai poisto) onnistuu, SQLite ei anna mitään tulostaulua.
Sarakkeiden nimien listauksesta voidaan jättää sarakkeita pois. Tällöin tietokannanhallintajärjestelmä asettaa luettelemattomien sarakkeiden arvoksi tyhjäarvon, oletusarvon tai jonkin triggerin ennalta määräämän arvon. Sarakkeiden nimiä täytyy olla INTO-osassa lueteltuna yhtä monta kuin VALUES-listassa on sarakkeita. Poikkeuksena tähän sääntöön sarakkeiden nimien listaus voidaan jättää kokonaan pois, jolloin VALUES-osan listassa täytyy olla yhtä monta arvoa kuin taulussa on sarakkeita. Arvot listataan tässä tapauksessa siinä järjestyksessä kuin sarakkeet ovat taulussa.
Sarakkeelle voidaan antaa arvo myös alikyselyn tuloksiin perustuen. Alikyselyn täytyy tällöin palauttaa ainoastaan yksi arvo, joka voi olla myös tyhjäarvo. Lisäyslauseen syntaksi muuttuu tässä tapauksessa niin, että vakion sijaan pilkkulistalla esitetään hakulause:
Nämä antaa kaikki No resulta, vaikka ylempänä olevat “tehtävät” toimii normaalisti??
T: tämä on hyvä huomio. Jos lisäys (tai muokkaus tai poisto) onnistuu, SQLite ei anna mitään tulostaulua. Lisäsin huomion myös ylemmäs tässä dokumentissa.
—Joissakin tietokannanhallintajärjestelmissä (esim. PostgreSQL) voidaan yhdellä INSERT-lauseella lisätä useita rivejä seuraavan syntaksin mukaisesti:
Taulurivejä voidaan myös lisätä toisesta taulusta, ts. uudet rivit voivat perustua aiemmin tietokantaan tallennettuun dataan. Tällöin komennon syntaksi on seuraava:
Myös tässä tapauksessa on syytä huomata, että INTO-osassa täytyy olla lueteltuna yhtä monta saraketta kuin lähdetaulusta valitaan SELECT-osassa. Hakulauseeseen voidaan asettaa miten monimutkaisia ehtoja vain: sarakkeiden arvojen tarkistuksia, alikyselyitä, koostefunktioita jne.
Se, miten tietokannanhallintajärjestelmä suoriutuu tilanteesta, jossa tietotyypit kohde- ja lähdetaulun välillä eroavat, riippuu tuotteesta. Joissakin tuotteissa lisäystä ei sallita, jos tietotyyppi, merkistökoodaus tai sarakkeen koko eroavat kun taas jotkin tuotteet yrittävät lisäystä esim. katkaisemalla merkkijonoja tai tekemällä tyyppimuunnoksia.
4.3.7 Taulurivien muokkaaminen
Yhden taulun sarakkeiden arvoja voidaan muuttaa komennolla UPDATE. Komennon syntaksi on:
Jossa SET-osassa määrätään, minkä sarakkeiden arvoja muokataan ja miten, ja WHERE-osassa määrätään, minkä rivien osalta sarakkeiden arvoja muokataan.
Jotkin tietokannanhallintajärjestelmät eivät salli itse määriteltyjen tarkentimien käyttöä UPDATE- ja DELETE-lauseissa.
Myös lausekkeeseen voidaan asettaa alikysely. Seuraavassa asetetaan sellaisten tuotteiden, joiden väriä ei ole määritelty, hinta samaksi kuin halvimman tuotteen hinta. SET-osan alikyselyssä tai WHERE-osassa voidaan asettaa miten monimutkaisia ehtoja vain.
4.3.8 Taulurivien poistaminen
Taulusta voidaan poistaa rivejä komennolla DELETE. Kuten INSERT- ja UPDATE-komennot, DELETE vaikuttaa vain yhden taulun riveihin. Komennon syntaksi on:
Esimerkiksi:
Lauseen WHERE-osassa voidaan asettaa miten monimutkaisia ehtoja vain. Jos WHERE-osa jätetään pois, poistetaan kaikki rivit. DELETE-lause ei varsinaisesti poista rivejä, vaan asettaa ne ylikirjoitettaviksi. Hakulause tauluun ei näytä DELETE-käskyllä poistettuja rivejä, mutta joutuu kuitenkin lukemaan ne.
4.4 DDL
Tietokannan rakenteen määrittäminen (Data Definition Language, DDL; kutsutaan joskus myös nimellä Schema Manipulation Language, SML) tapahtuu SQL:ssä mm. komennoilla CREATE, ALTER ja DROP. Tarkastellaan ennen rakenteen määrittämistä tietokantaympäristön yleistä rakennetta.
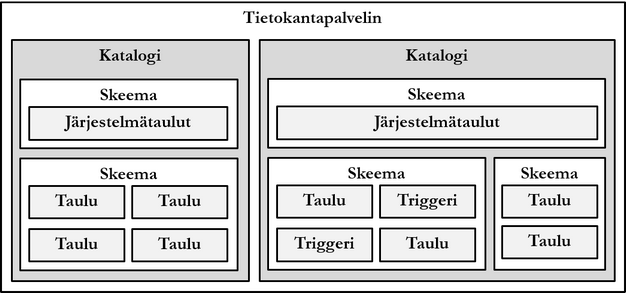
Kuviossa esiintyvissä käsitteissä on suuriakin tuotekohtaisia eroja. Tietokannanhallintajärjestelmän palvelinprosessiperhe (jotkin tuotteet käyttävät tästä nimeä tietokantainstanssi) on käynnissä laitteella. Tuotteesta riippuen palvelinprosesseja voi olla käynnissä useita.
Palvelinprosessi pitää yllä katalogeja, jotka ovat laitteen massamuistissa. Palvelinprosessi puolestaan sijaitsee keskusmuistissa. Palvelinprosessin lopettaminen ei poista massamuistissa sijaitsevaa dataa.
Katalogit sisältävät ns. skeemoja, jotka ovat kokoelmia erilaisia tietokantaobjekteja kuten tauluja, näkymiä, triggereitä ja proseduureja. Skeeman voi käsittää nimiavaruudeksi. Jokaisessa katalogissa on erityinen, automaattisesti luotu skeema, jonka avulla tietokannanhallintajärjestelmä pitää yllä metadataa katalogin kaikkien skeemojen kaikkien tietokantaobjektien rakenteesta. SQL-standardin mukaan metadatan sisältävät järjestelmätaulut ovat skeemassa INFORMATION_SCHEMA.
Olet kokeillut SQLite-tietokannanhallintajärjestelmän hallintakomentoa .tables alaluvun 4.3 alussa. Hallintakomento on itse asiassa alias järjestelmätaulua koskevalle SELECT-lauseelle:
4.4.1 Tietotyypit
SQL-standardi määrittää sarakkeille erilaisia tietotyyppivaihtoehtoja. SQL-kieli on vahvasti tyypittävä, mikä tarkoittaa, että jokaiselle taulun sarakkeelle on määritettävä tietotyyppi kun taulu luodaan. Yleiset, standardin mukaisia tietotyyppejä on lueteltu alla olevassa taulukossa.
| Tietotyyppi | Selite | Käyttöesimerkki | Esimerkkisarake |
|---|---|---|---|
| CHAR, CHARACTER | Määrätyn mittainen merkkijono | CHAR(10) | henkilötunnus |
| VARCHAR, CHARACTER VARYING | Vaihtelevan mittainen merkkijono | VARCHAR(20) | etunimi |
| INTEGER, INT | kokonaisluku | INT | syntymävuosi |
| NUMERIC | (desimaali)luku | NUMERIC(7,2) | kuukausipalkka |
| BOOLEAN | totuusarvo | BOOLEAN | tilaus_vahvistettu |
| DATE | päivämäärä | DATE | tilauspvm |
| TIMESTAMP | aikaleima | TIMESTAMP | maksuaika |
| ARRAY | lista | INTEGER[7] | lottonumerot |
| TEXT | tekstimuotoinen sarake | TEXT | arvostelu |
Mainittujen tietotyyppien lisäksi eri tuotteissa on lisäksi muita tietotyyppejä, kuten tietotyypit suuren binääridatan kuten teksti, kuvat, audio ja video tallentamiseen sekä tietotyypit paikkatiedolle.
4.4.2 Taulujen hallinta
Tauluja hallitaan komennoilla CREATE, ALTER ja DROP. Ennen komentojen syntaksiin tutustumista muistellaan luvussa 2 käsiteltyjä, relaatioihin liittyviä termejä, mutta tällä kertaa SQL:n näkökulmasta:
- Taululla on otsake (header). Otsake sisältää sarakkeiden nimet niiden luontijärjestyksessä.
- Taululla on asteluku (degree). Asteluku kertoo sarakkeiden määrän.
- Taululla on kardinaalisuus. Taulun kardinaalisuus on taulun rivien lukumäärä.
- Sarakkeella on kardinaalisuus. Sarakkeen kardinaalisuus on sen sisältämien erilaisten arvojen lukumäärä.
| astun | asnimi | kaup | tyyppi | mpiiri |
|---|---|---|---|---|
| a123 | Virtanen | Mikkeli | y | i |
| a125 | Kojo & Lipas | Kouvola | y | i |
| a134 | Liekki | Tampere | y | l |
4.4.2.1 Taulujen luominen
Taulu luodaan komennolla CREATE TABLE, ja sen yleinen syntaksi on seuraava.
Esimerkiksi harjoitustietokannan tuote-taulu voitaisiin luoda seuraavalla SQL-lauseella.
Tehtävä: muokkaa yllä olevaa SQL-lausetta niin, että se luo taulun nimeltä osasto. Taulussa on sarakkeet osastotunnus, osoite, pinta-ala (kahden desimaalin tarkkuudella) ja onko_toiminnassa, joka on BOOLEAN-tietotyyppiä. Lisää tauluun rivejä.
4.4.2.1.1 Perusavain
Perusavain (primary key, PK) on sarake tai sarakejoukko joka yksilöi taulun rivit, toisin sanoen perusavaimen ansiosta jokainen taulun rivi on erilainen. Taululle voidaan määrittää perusavain joko taulun luontikomennolla tai myöhemmin muokkaamalla taulua. Taulun luontikomennolla perusavaimen lisääminen muuttaa syntaksia seuraavalla tavalla:
Esimerkiksi
Kuten relaatiolla, myös taululla voi olla vain yksi perusavain. Jos perusavain koostuu useammasta kuin yhdestä sarakkeesta, se täytyy luoda sarakkeiden määrityksen jälkeen:
Esimerkiksi
Perusavaimen valintaa käsitellään tarkemmin luvussa 5.
4.4.2.1.2 Viiteavain
Viiteavain (foreign key, FK) on perusavaimen ohella tärkein relaatiotietokannan eheyspiirre. Viiteavain on sarake tai sarakejoukko, joka yksilöi rivin toisessa taulussa. Tavallisesti viiteavain viittaa toisen taulun perusavaimeen tai sen osaan. Sitä taulua, jonka perusavaimeen viiteavain viittaa, sanotaan taulujen välisen suhteen isäntätauluksi ja viittaavaa taulua renkitauluksi. Viiteavain rajoittaa viittaavan taulun sarakkeen arvojoukon isäntätaulun viitatun sarakkeen arvoihin. Viiteavainmääritys ei ole pakollinen, jotta taulujen välille voidaan muodostaa liitos SQL-lauseella.
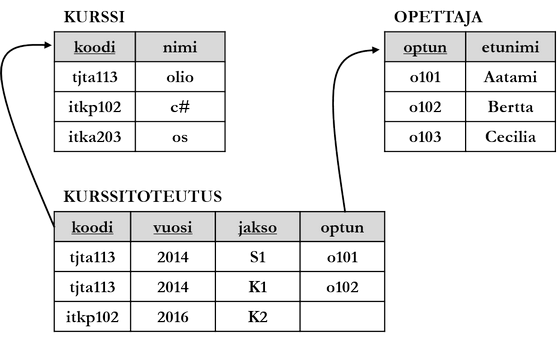
Viitatun ja viittaavan sarakkeen tulee olla samaa tietotyyppiä. SQL-kielessä viiteavaimet määritetään joko taulun luonnin yhteydessä CREATE TABLE-käskyllä tai muokkaamalla jo olemassa olevaa taulua. Yleinen syntaksi on seuraava.
Jossa siis CREATE TABLE-käskyllä luotava taulu tulee olemaan suhteen renkitaulu. FOREIGN KEY-lisämäärettä seuraa sulkujen sisällä pilkkulista, jossa luetellaan renkitaulun viittaavat sarakkeet, esimerkiksi:
CREATE TABLE tilausrivi (
asiakastunnus CHAR(10),
tuotetunnus CHAR(10),
maara INT,
PRIMARY KEY (asiakastunnus, tuotetunnus),
FOREIGN KEY (asiakastunnus) REFERENCES asiakas (asiakastunnus)
ON UPDATE RESTRICT
ON DELETE SET NULL,
FOREIGN KEY (tuotetunnus) REFERENCES tuote (tuotetunnus)
ON UPDATE RESTRICT
ON DELETE SET DEFAULT
);Yllä olevat lisämääreet kertovat tietokannanhallintajärjestelmälle, miten toimitaan kun isäntätaulun viitatun sarakkeen arvoissa tapahtuu muutoksia tai rivejä poistetaan:
RESTRICTestää sarakkeen muutokset tai rivin poiston isäntätaulussa.SET NULLasettaa sarakkeen arvon tyhjäarvoksi renkitaulussa.CASCADEvyöryttää isäntätaulussa tapahtuneet muutokset renkitaulun sarakkeeseen.SET DEFAULTasettaa renkitaulun sarakkeen arvoksi oletusarvon.
Tehtävä: Luo yllä olevan kuvion mukaiset taulut (kurssi, opettaja, kurssitoteutus) viite-eheyksineen. Alustava pohja SQL-lauseille on annettu alla. Lisää tauluihin rivejä.
4.4.2.1.2 Muut eheysrajoitteet
Sarakkeille voidaan asettaa eheysrajoitteita perus- ja viiteavaimen lisäksi. Yleisimmät, SQL-standardin määrittämät eheysrajoitteet ovat seuraavat:
DEFAULTmääritetään sarakkeen oletusarvo.NOT NULLkielletään tyhjäarvot sarakkeessa.UNIQUEsarakkeen arvojen täytyy olla yksilöiviä.CHECKvoidaan määrittää hyväksyttävät arvot ehtolausekkeella.
Esimerkiksi:
4.4.2.2 Taulujen muokkaaminen
Taulujen rakennetta muokataan DDL-komennolla ALTER TABLE. Komennolla voidaan esimerkiksi:
- Muuttaa sarakkeen tietotyyppiä.
- Muuttaa sarakkeen nimeä.
- Poistaa tai luoda uusi sarake.
- Poistaa tai luoda eheyspiirteitä.
Luodaan alla esimerkiksi (PostgreSQL) ensin osa taulun sarakkeista tietotyyppeineen ja lisätään vasta sen jälkeen eheyspiirteet ja kolmas sarake:
ALTER-käskyn toteutuksissa on suuriakin tuotekohtaisia eroja. Yleisenä piirteenä voidaan pitää ADD,DROP ja SET -avainsanoja.
4.4.2.3 Taulujen poistaminen
Taulu ja kaikki sen sisältämä data poistetaan komennolla DROP jota seuraa taulun nimi. Jos tauluun viitataan viiteavaimilla, ne voivat estää poisto-operaation.
4.4.3 Muiden tietokantaobjektien hallinta
Muita tietokantaobjekteja kuten näkymiä, triggereitä ja proseduureja voidaan myös hallita komennoilla CREATE, ALTER ja DROP. Tarkastellaan seuraavaksi yksinkertaisia esimerkkejä eri tietokantaobjektien luomisesta.
Näkymät (view) ovat SELECT-lauseen tuloksista luotuja aputauluja. Ne eivät kuitenkaan sisällä dataa, vaan ovat nimensä mukaisesti reaaliaikainen näkymä datasta. Näkymän voi käsittää tallennetuksi SELECT-lauseeksi, jolla saavutetaan mm. yksinkertaisemmat kyselyt sovellusohjelmassa (ts. tehdään hakulause näkymään, ei tauluihin), yleisimpien ad hoc -kyselyiden tallentaminen ja hienojakoisempi oikeuksienhallinta.
Yllä olevan lauseen avulla luodaan näkymä, joka sisältää SELECT-lauseensa mukaisen näkymän dataan. Näkymän sisältöä voidaan tarkastella edelleen SELECT-lauseella, esim. SELECT * FROM itäiset_asiakkaat;. SELECT-lause, jolla näkymä luodaan voi olla miten monimutkainen tahansa.
Triggerit (trigger) ovat ohjelmakoodia tai SQL:ää, joka suoritetaan automaattisesti jonkin ehdon täyttyessä. SQL-standardi määrittää, että triggerin käynnistymisen saa aikaan joko tauluun tai näkymään kohdistuva SELECT-, INSERT-, UPDATE- tai DELETE-käsky. Alla on esimerkki triggeristä (Oracle), joka sallii tyontekija-tauluun kohdistuvat poisto-operaatiot, mutta tallentaa lokiin vanhat arvot sekä poisto-operaation suoritusajan ja suorittajan.
Proseduurit ja funktiot ovat tietokantaan tallennettua ohjelmakoodia, joka suoritetaan kutsuttaessa. Niiden käyttökohteet voivat olla melkein mitä tahansa, kohdealueesta ja sen tarpeista riippuen. SQL-standardi määrittää funktion rutiiniksi, joka voi palauttaa yhden arvon. Proseduuri puolestaan on rutiini, joka voi tuottaa useita tulosteparametreja. Proseduureilla ja funktioilla saadaan tavallisesti luotua monimutkaisempaa toiminnallisuutta kuin triggereillä, sillä niiden toiminnallisuus ei rajoitu SQL:ään. Eri tuotteilla on erilaisia tapoja ja kieliä hallita proseduureja ja funktioita, esimerkiksi:
- Oracle Database: PL/SQL tai Java.
- SQL Server: T/SQL tai .NET-kielet.
- PostgreSQL: PL/pgSQL, pl/python, pl/perl jne.
Triggereitä, proseduureja tai funktioita ei käsitellä kurssilla tämän tarkemmin.
4.4.4 Indeksit
Indeksit eli hakemistot ovat tietorakenteita, jotka voivat tehdä hakuoperaatioista nopeampia. SQL-standardi ei määritä viitekehystä indekseille, joten eri tuotteissa on hyvinkin erilaisia indeksointitoteutuksia. Tarkastellaan seuraavaksi yleisellä tasolla relaatiotietokannanhallintajärjestelmiin vakiintuneita indeksointitapoja.
4.4.4.1 Rakenne
Vakiintunut indeksityyppi relaatiotietokannoissa on ns. B+-puu (B+-tree). Sen mukaisesti indeksin rakenne on puuta muistuttava ja jokaiseen ei-lehtisolmuun sijoitetaan n puuosoitinta (pointer) ja n-1 avainarvoa. Avainarvo kertoo, mistä hakulauseen ehdoissa määritettyä tauluriviä etsitään: jos etsittävä arvo on avainarvoa pienempi, seurataan avainarvon vasemmalta puolelta löytyvää puuosoitinta. Jos taas etsittävä arvo on yhtä suuri tai suurempi kuin avainarvo, seurataan avainarvon oikealta puolelta löytyvää puuosoitinta päätyen lopulta puun lehtisolmuun, jossa on viittaus levylle.
Indeksipuun lehtisolmuissa on avainarvoja, levyosoitteita sekä lohko-osoittimia. Levyosoitteet viittaavat siihen fyysiseen kohtaan levyllä, johon indeksoidun taulun rivi on tallennettu. Lohko-osoitin viittaa indeksin seuraavaan lehtisolmuun. Avainarvot ovat sarakkeiden arvoja indeksoidusta sarakkeesta.
Oletetaan hakulause SELECT * FROM henkilö WHERE ikä = 38; ja oletetaan indeksin olevan yllä olevan kuvion mukainen. Tietokannanhallintajärjestelmä seuraa indeksiä aloittaen juurisolmusta. Juurisolmusta seurataan avainarvon 23 oikealta puolelta löytyvää puuosoitinta, koska 38 > 23. Seuraavan tason solmusta seurataan avainarvon 34 oikealta puolelta löytyvää puuosoitinta, koska 38 > 34. Lehtisolmusta seurataan levyosoitinta levyosoitteeseen, jonne kyseinen rivi on tallennettu ja luetaan rivi muistiin.
4.4.4.2 Toiminta
B+-puu pyritään tavallisesti pitämään muistissa lehtisolmuja lukuun ottamatta. Kuvitellaan taulu tuote, jossa on sarakkeet tuotetunnus, tuotenimi, ja hinta. Taulun perusavain on tuotetunnus-sarake ja taulussa on 10 000 riviä. Oletetaan yksinkertainen SQL-hakulause:
Ilman indeksiä tietokannanhallintajärjestelmä joutuu lukemaan läpi pahimmassa tapauksessa taulun kaikki 10 000 riviä ja vertaamaan tuotetunnus-sarakkeen arvoa haluttuun arvoon 5200. Jos oletetaan yksinkertaistettuna, että yhden lohkon lukeminen levyltä kestää 10 ms, ja yksi rivi mahtuu yhteen lohkoon, koko taulun lukeva operaatio kestää 10 000 riviä * 10 ms = 100 sekuntia.
Jos taas tuotetunnus-sarake on indeksoitu, mutta indeksi ei ole muistissa, joutuu tietokannanhallintajärjestelmä tekemään n+1 levylukua: rivin luvun levyltä sekä n lukua indeksiin, missä n on indeksipuun korkeus.
Indeksit määritetään SQL-rajapinnan kautta DDL-lauseilla. Alla on esitetty yksinkertaisia esimerkkejä indeksien määrittämisestä.
4.5 DCL
Valtuuttaminen (Data Control Language, DCL) perustuu SQL-kielessä käyttäjien ja käyttäjäryhmien oikeuksiin. Oikeuksia voidaan myöntää erilaisiin tietokantaobjekteihin, kuten tauluihin, sarakkeisiin, näkymiin tai triggereihin. Tässä alaluvussa käsitellään valtuuttamiseen liittyvää teoriaa ja SQL-komentoja. DCL-komentoja on SQL-kielessä kaksi: GRANT ja REVOKE. Lisäksi tässä alaluvussa käsitellään roolien luonti.
4.5.1 Käyttäjät ja käyttäjäryhmät
Relaatiotietokannan käyttäjät voidaan tunnistaa SQL-rajapinnan kautta. SQL-standardi ei määritä käskyjä käyttäjien tai käyttäjäryhmien luomiseksi, mutta yleistää nämä molemmat ns. rooleiksi. Roolit voidaan määrittää toimimaan sekä käyttäjinä että käyttäjäryhminä. Käyttäjäryhmänä toimivan roolin tunnistaa tavallisesti siitä, että sitä käyttäen ei voida kirjautua sisään tietokantaan.
Rooleja voidaan myöntää toisille rooleille. Tällöin rooli perii sille myönnetyn roolin oikeudet. Tällä tavalla voidaan muodostaa käyttäjien ja käyttäjäryhmien hierarkioita, ja suurten käyttäjämäärien hallinnoiminen on vaivattomampaa.
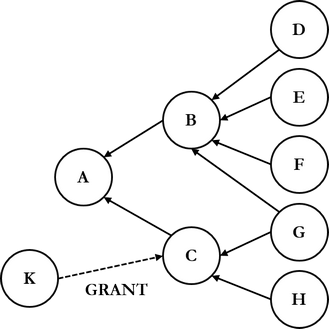
Yllä olevassa kuviossa roolit B ja C perivät kaikki roolin A oikeudet. Edelleen roolit G ja H perivät kaikki C:n oikeudet, ts. roolilla H on kaikki C:n ja A:n oikeudet. Kun roolit K myöntää uuden oikeuden roolille C, oikeus periytyy automaattisesti myös rooleille G ja H.
Rooli luodaan komennolla CREATE ROLE, jota seuraa roolin nimi. Tavallisesti rooleja voivat luoda vain järjestelmänvalvojat. Esimerkiksi PostgreSQL-tietokannanhallintajärjestelmällä roolin voi luoda seuraavalla tavalla:
Komento loisi uuden roolin salasanoineen, myöntäisi roolin varastotyontekijat oikeudet uudelle roolille, sallisi roolin kirjautua ja asettaisi salasanan vanhenemaan toukokuun 8. päivä.
Rooli poistetaan komennolla DROP ROLE, jota seuraa roolin nimi. Vain roolin omistaja tai järjestelmänvalvoja voi poistaa roolin.
4.5.2 Käyttöoikeudet
Jokaisella tietokantaobjektilla on omistaja, ja omistaja on oletusarvoisesti se rooli, joka on luonut tietokantaobjektin. Omistajalla on kaikki oikeudet tietokantaobjektiinsa, ja omistaja voi antaa ja poistaa muilta rooleilta oikeuksia tähän objektiin. Alla olevassa taulukossa on listattu yleisimmät standardin mukaiset oikeudet selitteineen.
| Oikeus | Oikeuttaa |
|---|---|
| CONNECT | Muodostamaan tietokantayhteyden. |
| SELECT | Näkemään dataa. |
| INSERT | Lisäämään dataa. |
| UPDATE | Päivittämään dataa. |
| DELETE | Poistamaan dataa. |
| EXECUTE | Käynnistämään rutiineja. |
| ALL PRIVILEGES | Kaikki yllä mainitut paitsi CONNECT. |
SQL-standardi ei määritä komentoja DDL-käskyjen kuten CREATE, ALTER ja DROP valtuuttamiseen, mutta useimmat tuotteet määrittävät. Oletuksena kuitenkin käyttäjä voi suorittaa DDL-käskyjä omistamassaan skeemassa. Jos halutaan oikeuttaa tai poistaa oikeuksia hienorakeisemmalla tasolla, voidaan luoda näkymä, ja myöntää tarvittavat oikeudet siihen.
4.5.2.1 Käyttöoikeuksien myöntäminen
Käyttöoikeudet myönnetään komennolla GRANT. Komennon yleinen syntaksi on seuraava:
GRANT-avainsanaa seuraa oikeus yllä olevan taulukon mukaisesti, ja oikeuksia voidaan myöntää yhdellä komennolla useita. Tietokantaobjekti voi olla esimerkiksi taulu, näkymä, proseduuri tai katalogi. Näkymien avulla oikeuksia voidaan myöntää hienojakoisemmin kuin taulujen avulla on mahdollista. WITH GRANT OPTION oikeuttaa myöntämään annettua roolia edelleen. Tarkastellaan optiota esimerkin avulla:
Nyt käyttäjät (roolit) matti ja maija voivat myöntää GRANT-komennolla sekä katselu- että päivitysoikeutta tyontekija-tauluun muille käyttäjille.
SQL-standardin mukaisesti lisäys- ja päivitysoikeutta voidaan myöntää myös sarakekohtaisesti, jos valtuutus kohdistuu tauluun tai näkymään. Tällöin oikeuden nimeä seuraa sulkeiden sisällä pilkkulista, joka sisältää sarakkeiden nimet, esimerkiksi:
Rooli voidaan myöntää toisille rooleille samalla komennolla seuraavan yleisen syntaksin mukaisesti:
4.5.2.2 Käyttöoikeuksien poistaminen
Käyttöoikeuksia poistetaan komennolla REVOKE. Komennon yleinen syntaksi on seuraava:
Valinnainen GRANT OPTION FOR -lisämääre poistaa ainoastaan edelleenvaltuutusoikeuden. Jos sitä ei käytetä, poistetaan varsinainen oikeus. Jos käyttäjältä poistetaan rooli, ja käyttäjä on valtuuttanut jotakin oikeuttaan edelleen, myös edelleen valtuutetuilta poistetaan kyseiset oikeudet:
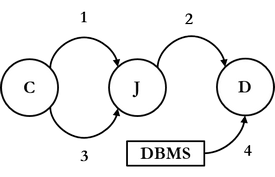
Yllä olevan kuvion mukaisesti
- Rooli C myöntää ensin oikeuden roolille J
WITH GRANT OPTION-lisämääreellä. - Rooli J myöntää saamansa oikeuden roolille D.
- Rooli C päättääkin poistaa myöntämänsä oikeuden roolilta J, jolloin
- tietokannanhallintajärjestelmä poistaa automaattisesti oikeuden myös roolilta D.
Rooli voidaan poistaa toiselta roolilta seuraavan syntaksin mukaisesti:
4.6 TxCL
SQL:n tapahtumanhallinta (Transaction Control Language, TxCL) sisältää muihin SQL:n osa-alueisiin verrattuna vähän komentoja, mutta teoria komentojen takana on runsasta jatkuvasti kehittyvää. Relaatiotietokantaa käyttävän sovellusohjelman tapahtumanhallinnan suunnittelu on erityisen tärkeää tietokantaohjelmoijalle. Toisaalta myös ns. NoSQL-tietokantaparadigmojen yleistyminen ja niihin liittyvä, relaatiotietokannoista poikkeava tapahtumanhallinta on erityisen hyödyllistä myös DBA:n (database administrator) ja konsultin tuntea.
Tietokantajärjestelmä on moniajoympäristö, jossa voidaan suorittaa jopa satoja tuhansia operaatioita sekunnissa. Jos kaikki operaatiot suoritettaisiin peräkkäin, DBMS toimisi liian hitaasti. Tästä syystä tietokantaan kohdistuvat käskyt on ryhmiteltävä tapahtumiksi (transaction) ja suoritettava samanaikaisesti eli rinnakkain. Tapahtumalla tarkoitetaan joukkoa (1..n) operaatioita. Operaatio on SQL-lause tai osa SQL-lauseesta, esim. SELECT- tai UPDATE-lause. Operaatiot jaetaan yleisellä tasolla luku- ja kirjoitusoperaatioihin. Lukuoperaatio lukee tietokannasta tietueen keskusmuistiin, ja kirjoitusoperaatio kirjoittaa muuttujan arvon tietokantaan.
4.6.1 Tapahtumanhallinta SQL:n näkökulmasta
Tapahtumia hallitaan SQL-standardin mukaisesti kolmella komennolla:
START [TRANSACTION]taiBEGIN [TRANSACTION]aloittaa tapahtuman.COMMIT [WORK]vahvistaa kirjoitusoperaatiot tietokantaan ja lopettaa tapahtuman.ROLLBACK [WORK]peruuttaa kaikki tapahtuman operaatioiden tekemät muutokset ja lopettaa tapahtuman.
Oletuksena vain vahvistetun (ts. COMMIT-käskyn saaneen) tapahtuman tekemät muutokset tietokantaan ovat muiden tapahtumien luettavissa.
SQL-standardi vaatii, että tapahtumanhallintaa voidaan käyttää kaikkiin DML-operaatioihin. Useat suositut relaatiotietokannanhallintajärjestelmät kuitenkin laajentavat tapahtumanhallintansa koskemaan myös DDL-operaatioita. Kokoava esimerkki tapahtumanhallinnan komennoista on esitetty alaluvussa 4.6.2.2.
4.6.2 ACID
Relaatiotietokannanhallintajärjestelmille on tyypillistä, että niiltä vaaditaan ja että ne täyttävät neljä perusvaatimusta:
- Atomicity (jakamattomuus): tapahtuma on atominen. Joko kaikki tapahtuman sisältämät operaatiot onnistuvat tai ne kaikki epäonnistuvat. Toisin sanoen tapahtuman kaikki operaatiot suoritetaan onnistuneesti tai toimitaan niin kuin tapahtumaa ei olisi koskaan aloitettukaan.
- Consistency (oikeellisuus): tapahtuma muuttaa tietokannan yhdestä oikeellisesta tilasta toiseen oikeelliseen tilaan. Tietokannan tilan sanotaan olevan oikeellinen, jos kaikki tietokannan sisältämä data noudattaa tietokannan sisäistä liiketoimintalogiikkaa.
- Isolation (eristyvyys): jos usea tapahtuma suoritetaan samanaikaisesti, yhden tapahtuman tulokset ovat eroteltavissa toisen tapahtuman tuloksista. Toisin sanoen tietokanta on lopulta samassa tilassa riippumatta siitä, suoritetaanko tapahtumat rinnakkain vai peräkkäin.
- Durability (pysyvyys): tapahtuman tulokset ovat pysyviä. Jos tapahtuma suoritetaan onnistuneesti, tulokset eivät katoa.
Näistä neljästä perusvaatimuksesta käytetään akronyymiä ACID. Seuraavassa on selitetty tarkemmin ACID-ominaisuuksia.
4.6.2.1 A: Jakamattomuus
Tietokantaan kohdistuvat operaatiot ryhmitellään tapahtumiksi. Yksi tapahtuma koostuu yhdestä tai useammasta operaatiosta. Operaatioiden onnistumista tai epäonnistumista mitataan tapahtumien näkökulmasta. Jos kaikki tapahtuman operaatiot onnistuvat, tapahtuma on suoritettu onnistuneesti eli vahvistettu (commit). Yhdenkin operaation epäonnistuessa tapahtuman sanotaan keskeytyneen (aborted) ja tällöin kaikki tapahtuman jo suoritetut operaatiot peruutetaan (rollback). Tapahtuman peruuttamisen mahdollistaa alaluvussa 2.1.2 esitelty tapahtumaloki. Operaation epäonnistumisen voi aiheuttaa esimerkiksi:
- Käyttäjältä saatu keskeytys.
- Tapahtuma havaitsee, että operaation suorittaminen rikkoisi tietokannan liiketoimintalogiikkaa.
- Jokin käyttöjärjestelmästä (esim. I/O-operaatio) johtuva virhe.
Jakamattomuudella tarkoitetaan nimensä mukaisesti sitä, että tapahtuma on jakamaton: sen sisältämistä operaatioista suoritetaan onnistuneesti kaikki tai ei yhtäkään. Sen, miten operaatiot ryhmitellään tapahtumiin päättää tavallisesti tietokantaohjelmoija tai muu sovelluskehittäjä.
4.6.2.2 C: Oikeellisuus
Alla on esimerkki tapahtumasta, joka muuttaa tietokannan yhdestä oikeellisesta tilasta toiseen. Voitaisiin tulkita, että alla olevassa tapahtumassa on neljä operaatiota: SELECT (luku), UPDATE (luku ja kirjoitus) ja SELECT (luku). SQL-avainsanat on esitetty suuraakkosilla. Tapahtuma noudattaa kuvitteellisen pankin liiketoimintasääntöä, jonka mukaan tilillä täytyy olla vähintään 0 euroa rahaa.
BEGIN TRANSACTION nosta_rahaa(tilinro, nostomaara);
SELECT saldo
FROM tili
WHERE tilinro = :tilinro;
if (!tilinro):
print("Tiliä ei löytynyt.");
ROLLBACK;
endif;
UPDATE tili
SET saldo = saldo - :nostomaara
WHERE tilinro = :tilinro;
SELECT saldo
FROM tili
WHERE tilinro = :tilinro;
if (saldo < 0):
print("Tilillä ei ole tarpeeksi rahaa.");
ROLLBACK;
endif;
print("Nosto onnistui.");
COMMIT;
END TRANSACTION nosta_rahaa;SQL-käsky BEGIN TRANSACTION aloittaa tapahtuman. Ensimmäinen operaatio noutaa annetun parametrin mukaisen tilin saldon muistiin. Jos tilinumeroa ei löydy, koko tapahtuma peruutetaan komennolla ROLLBACK.
Seuraava SQL-lause vähentää muistiin luetusta saldosta nostomaara-parametrin arvon. Jos saldo on kirjoitusoperaation jälkeen negatiivinen, koko tapahtuma peruutetaan komennolla ROLLBACK. Muussa tapauksessa suoritetaan COMMIT-käsky, joka vahvistaa tapahtuman tulokset. COMMIT-käskyn jälkeen tulokset ovat myös muiden tapahtumien luettavissa.
On syytä huomata, että yllä olevan esimerkin tarkoitus on demonstroida erityisesti tapahtumanhallinnan komentoja. Saldon tarkastaminen voitaisiin toteuttaa myös tietokannanhallintajärjestelmän tasolla (kuten alaluvussa 4.4.3) tai isäntäkielen ohjelmakoodissa tietokannasta luetun saldon ja nostomäärän vertailuna.
4.6.2.3 I: Eristyvyys
Tietokannoille on tyypillistä, että moni käyttäjä käyttää tietokantaa samanaikaisesti, jolloin tapahtumia suoritetaan samanaikaisesti eli rinnakkain. Tarkastellaan seuraavaa yksinkertaista esimerkkiä kahdesta tapahtumasta, jotka käsittelevät samaa pankkitiliä:
- Tapahtuma T1 lukee pankkitilin saldon (100 euroa) muistiin.
- Tapahtuma T2 lukee pankkitilin saldon (100 euroa) muistiin.
- Tapahtuma T1 kasvattaa saldoa muistissa 20 eurolla ja kirjoittaa uuden saldon (120) tietokantaan.
- Tapahtuma T2 kasvattaa saldoa muistissa 20 eurolla ja kirjoittaa uuden saldon (120) tietokantaan.
Kun rinnakkaiset tapahtumat T1 ja T2 on onnistuneesti suoritettu, pankkitilillä on 120 euroa. Jos tapahtumat olisi suoritettu peräkkäin, pankkitilillä olisi 140 euroa ja täten yllä kuvattu rinnakkainen tapaus ei täytä eristyvyyden vaatimusta. Yllä kuvattua ongelmaa kutsutaan menetetyksi päivitykseksi (lost update). Tietokannanhallintajärjestelmien ratkaisuja rinnakkaisuuden hallintaan tarkastellaan alaluvuissa 4.6.3 ja 4.6.4.
4.6.2.4 D: Pysyvyys
ACID:n pysyvyydellä tarkoitetaan datan pysyvyyttä: kun tapahtuma on suoritettu onnistuneesti loppuun, data on kirjoitettu tietokantaan. Pysyvyyttä rikkovaa toimintaa voisi olla esimerkiksi COMMIT-operaation onnistumisen ilmoittaminen, vaikka kirjoitettava data on todellisuudessa vasta kiintolevyn sisäisessä välimuistissa. Toisin sanoen tapahtuman tekemät muutokset säilyvät, vaikka järjestelmä kaatuisi välittömästi tapahtuman onnistumisen jälkeen. Vakavien, tallennuslaitteiden laitevirheiden sietokykyä ei vaadita.
4.6.3 Rinnakkaisuudenhallinta
Ajoituksella (schedule) tarkoitetaan sitä järjestystä, jossa useamman rinnakkaisen tapahtuman operaatiot suoritetaan ja on olemassa useita vaihtoehtoisia ajoituksia, joista toiset täyttävät ACID:n eristyvyyden vaatimuksen ja toiset eivät. Kuten aiemmin mainittiin, tapahtumien suorittaminen peräkkäin (ns. sarjallinen (serial) ajoitus) on liian hidasta, ja käytännössä kaikkien RDBMS:n ajoitus on rinnakkaista eli ei-sarjallista (non-serial). Sarjallistuvaksi (serializable) ajoitukseksi kutsutaan sellaista rinnakkaista ajoitusta, joka on ekvivalentti eli yhtäpitävä jonkin sarjallisen ajoituksen kanssa.
Tapahtumanhallinta, joka täyttää ACID:n eristyvyyden (isolation) vaatimuksen sanotaan noudattavan sarjallistuvaa ajoitusta. Rinnakkaisuudenhallinta (concurrency control) määrittää, millä menetelmillä sarjallistuva ajoitus saavutetaan. Vaihtoehtoja ovat esimerkiksi tapahtumille annettavat aikaleimat (timestamp ordering), erityisesti hajautetuissa tietokannoissa käytetyt vahvistusajan mukaiset aikaleimat (commitment ordering) ja tällä kurssilla käsiteltävä lukitus (locking). Korkeammalla tasolla puhutaan optimistisesta (pyritään ehkäisemään ongelmatilanteet) ja pessimistisestä (pyritään ratkaisemaan ongelmatilanteet) rinnakkaisuudenhallinnasta.
Rinnakkaisista tapahtumista aiheutuvat ongelmatilanteet ratkaistaan tietokannanhallintajärjestelmissä monesti lukituksella. Lukituksella tarkoitetaan tietokannan tietueille sallittujen operaatioiden rajoittamista. Tietokannanhallintajärjestelmä pitää kirjaa tietueiden lukoista ns. lukkotaulussa. Lukitus on matalan tason tekniikka, johon tietokantaohjelmoija tai muukaan käyttäjä ei tavallisesti pääse suoraan vaikuttamaan. Tarkastellaan seuraavaksi yleistä relaatiotietokannanhallintajärjestelmien toteutustapaa lukitukselle.
4.6.3.1 Lukitustavat
Lukituksen rakeisuudelle on erilaisia toteutustapoja:
Binäärilukituksessa tietue on joko lukittu (1) tai lukitsematon (0). Kun tietue on lukittu binäärilukituksella, toinen tapahtuma ei voi käyttää sitä millään tavalla. Tietue voi olla taulun sarakkeen ja rivin leikkauskohta, taulun rivi, taulu, taulualue tai koko tietokanta riippuen tietokannanhallintajärjestelmän toteutustavasta.
Luku/kirjoituslukituksessa käytössä on luku- (S eli shared lock) ja kirjoituslukkoja (X eli exclusive lock). Kun tietue on lukulukittu, kaikki tapahtumat voivat lukea sitä ja saada siihen lukulukon, mutta eivät kirjoittaa siihen eivätkä saada siihen kirjoituslukkoa. Kun tietue on kirjoituslukittu, vain yksi tapahtuma voi muuttaa sitä, eikä yksikään toinen tapahtuma voi lukea sitä. Joissakin tapauksissa tapahtumalle voidaan sallia ns. lukon korotus, jolloin lukulukko muutetaan kirjoituslukoksi.
Nykyään relaatiotietokannanhallintajärjestelmissä on käytössä hienorakenteisemmat lukkotyypit. Tuotteesta riippuen erilaisia lukkotyyppejä on tavallisesti luku- ja kirjoituslukot mukaan laskettuna viidestä seitsemään. Erilaiset lukkotyypit eivät kuitenkaan takaa ACID-ominaisuuksien eristyvyysvaatimusta, vaan niiden lisäksi tarvitaan lukitusprotokolla, joka on tavallisesti kaksivaiheinen lukitus.
4.6.3.2 Kaksivaiheinen lukitus
Tarkastellaan seuraavaksi kaksivaiheista lukitusprotokollaa (two-phase locking, 2PL) luku/kirjoituslukituksella. Kaksivaiheisen lukitusprotokollan mukaan tapahtuma jaetaan kahteen osaan:
- Ensimmäisessä eli laajentamisvaiheessa tapahtuma varaa käyttöönsä tarvitsemansa lukot. Sellaisiin tietueisiin, joista ainoastaan luetaan, varataan lukulukko. Sellaisiin tietueisiin, joihin kirjoitetaan, varataan kirjoituslukko. Lukot varataan juuri ennen tietueeseen kohdistuvan operaation suorittamista. Yhtään lukkoa ei vapauteta. Jos käytössä on lukkojen korotus, kaikki korotukset tehdään tässä vaiheessa.
- Jälkimmäisessä eli supistamisvaiheessa lukot vapautetaan. Lukko vapautetaan heti, kun tietueeseen ei tarvitse enää tarvita lukkoa. Yhtään uutta lukkoa ei varata, eikä lukkoja koroteta.
Kaksivaiheisen lukituksen toteutukselle on yleisellä tasolla neljä erilaista toteutustapaa:
- Yllä kuvattu protokolla (ns. perusprotokolla).
- Konservatiivinen protokolla eroaa yllä kuvatusta perusprotokollasta siten, että kaikki tapahtuman tarvitsemat lukot varataan laajentamisvaiheessa ennen yhdenkään operaation suorittamista.
- Tiukka (strict) protokolla (S2PL) eroaa yllä kuvatusta perusprotokollasta siten, että kaikki tapahtuman tarvitsemat kirjoituslukot vapautetaan supistamisvaiheessa vasta, kun tapahtuma on ohi.
- Vahva ja tiukka (strong strict) protokolla (SS2PL) eroaa yllä kuvatusta perusprotokollasta siten, että kaikki tapahtuman tarvitsemat lukot vapautetaan supistamisvaiheessa vasta, kun tapahtuma on ohi.
4.6.3.3 Deadlock-tilanteet
Kaksivaiheisen lukituksen potentiaalisina ongelmina voidaan pitää ns. deadlock-tilannetta, jossa tapahtumat odottavat toistensa vapauttavan lukkoja, mutta aika ei ratkaise tilannetta. Tarkastellaan esimerkkitilannetta, jossa tietokantaan kohdistuvat samanaikaiset, kaksivaiheista lukitusta noudattavat tapahtumat T1 ja T2 saattavat tietokannanhallintajärjestelmän deadlock-tilaan:
| T1 | T2 | Lopputulos |
|---|---|---|
| Kirjoituslukitus tietueeseen A. | Tietue A kirjoituslukittu. | |
| Kirjoituslukitus tietueeseen B. | Tietue B kirjoituslukittu. | |
| Kirjoituslukitus tietueeseen B. | Odotetaan, että T2 vapauttaa lukon. | |
| Kirjoituslukitus tietueeseen A. | Odotetaan, että T1 vapauttaa lukon. |
Vaikka ACID-ominaisuuksien eristyvyysvaatimusta voidaan kohdealueesta riippuen pitää tärkeämpänä kuin deadlock-tilanteiden välttämistä, myös deadlock-tilanteita voidaan käsitellä. On olemassa erilaisia lähestymistapoja deadlock-tilanteisiin:
- Estetään deadlock-tilanteet protokollalla, eli annetaan jokaiselle tapahtumalle prioriteetti aikaleiman perusteella:
- Wait-die-protokolla: vanhojen tapahtumien annetaan odottaa uudempien tapahtumien vapauttavan lukkoja. Tapahtumat peruutetaan (
ROLLBACK), jos ne joutuvat odottamaan itseään vanhempia tapahtumia. - Wound-wait-protokolla: uusien tapahtumien annetaan odottaa vanhempien tapahtumien vapauttavan lukkoja. Tapahtumat peruutetaan, jos ne joutuvat odottamaan itseään uudempia tapahtumia.
- Wait-die-protokolla: vanhojen tapahtumien annetaan odottaa uudempien tapahtumien vapauttavan lukkoja. Tapahtumat peruutetaan (
- Tunnistetaan deadlock-tilanteet ajasta, jonka tapahtuma on joutunut odottamaan ja peruutetaan tapahtuma määrätyn odotusajan jälkeen.
4.6.4 Eristyvyystasot
SQL-standardi määrittää neljä eristyvyystasoa (isolation level). Eristyvyystasolla voidaan vaikuttaa rinnakkaisten tapahtumien nopeuteen ja potentiaalisiin ongelmiin: väljempi eristyvyystaso johtaa teoriassa nopeampiin tapahtumiin, mutta nostaa potentiaalisten ongelmien määrää. Vain vahvin eristyvyystaso on nimensä mukaisesti sarjallistuva. Eristyvyystaso voidaan määrittää tapahtuma- tai tietokantapalvelinkohtaisesti. Joissakin tuotteissa on mahdollista määrittää myös taulukohtaisia eristyvyystasoja.
Seuraavassa on lueteltu SQL-standardin mukaiset eristyvyystasot vahvimmasta väljimpään:
- Sarjallistuva (SERIALIZABLE): vahvin eristyvyystaso, jonka seurauksena ovat hitaimmat tapahtumat. tapahtuma pitää kaikki käsittelemänsä tietueet lukittuina, kunnes tapahtuma on ohi. Lisäksi lukitaan tapahtuman käsittelemä arvoväli.
- Toistettavat lukuoperaatiot (REPEATABLE READ): tapahtuman käsittelemät tietueet ovat lukittuina, kunnes tapahtuma on ohi. Arvoväliä ei lukita.
- Vahvistettujen tietueiden luku (READ COMMITTED): vaikka tapahtuma T1 olisi lukenut muuttujan arvon muistiin, toinen tapahtuma T2 voi muokata tätä arvoa ennen kuin tapahtuma T1 on ohi.
- Vahvistamattomien tietueiden luku (READ UNCOMMITTED): eristyvyystasolla toimiva tapahtuma voi lukea muiden tapahtumien tekemät, vahvistamattomatkin muutokset. Vahvistamaton muutos tarkoittaa sellaista operaatiota, jonka tapahtuma ei ole saanut
COMMIT- taiROLLBACK-käskyä.
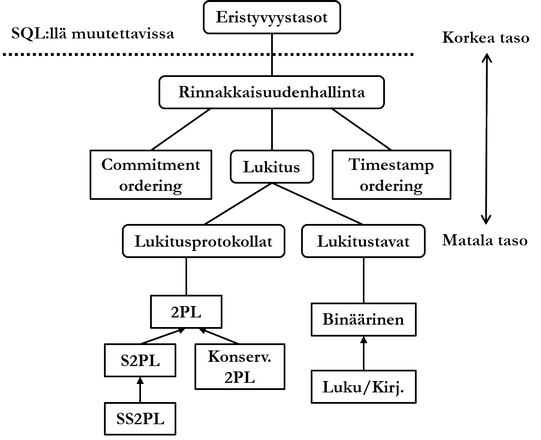
4.6.4.1 Ongelmatilanteet
Tarkastellaan seuraavaksi tarkemmin tunnistettuja ongelmia eli poikkeamia (anomaly), jotka rikkovat eristyvyyden perusvaatimusta.
4.6.4.1.1 Haamuluku (phantom read)
Saman tapahtuman samanlaiset lukuoperaatiot palauttavat erilaisen joukon rivejä. Ongelman saa aikaan jokin muu, samanaikainen tapahtuma, joka lisää tauluun rivin tai rivejä käsiteltävälle arvovälille. Kysymysmerkki on SQL-standardin mukainen merkintä sidotulle parametrille (bound parameter). Sidotun parametrin arvo saadaan sovellusohjelmalta ajon aikana.
| T1 | T2 |
|---|---|
BEGIN; |
|
SELECT tilinroFROM tiliWHERE saldo > 1000000; |
|
BEGIN; |
|
INSERT INTO tili (tilinro, saldo)VALUES (?, 2000000); |
|
COMMIT; |
|
SELECT tilinroFROM tiliWHERE saldo > 1000000; |
Nyt tapahtuman T1 kaksi lukuoperaatiota palauttavat erilaisen joukon rivejä, mikä rikkoo sarjallistuvuuden perusperiaatetta. Mikäli koko käsiteltävä arvoväli (saldo > 1000000) lukittaisiin tapahtuman T1 ajaksi, ei yllä kuvattua ongelmaa voisi esiintyä.
Syntaksilla :muuttuja merkitään SQL:ssä ns. dynaamisia parametreja. Parametrien arvot tulevat isäntäkielestä järjestelmän ajon aikana.
4.6.4.1.2 Ei-toistettavat lukuoperaatiot (non-repeatable reads)
Tapahtuman T1 yhden rivin palauttava lukuoperaatio R1 palauttaa erilaisen rivin kuin saman tapahtuman samanlainen lukuoperaatio R2. Ongelman saa aikaan toinen, samanaikainen tapahtuma T2, joka päivittää riviä.
| T1 | T2 |
|---|---|
BEGIN; |
|
SELECT saldoFROM tiliWHERE tilinro = ?; |
|
BEGIN; |
|
UPDATE tiliSET saldo = saldo + 100WHERE tilinro = ?; |
|
COMMIT; |
|
SELECT saldoFROM tiliWHERE tilinro = ?; |
Nyt tapahtuman T1 kaksi lukuoperaatiota palauttavat erilaisen rivin. Mikäli käsiteltävä rivi (tilinro = :a) pidettäisiin lukittuna koko tapahtuman T1 ajan, ei yllä kuvattua ongelmatilannetta voisi tapahtua.
4.6.4.1.3 Likainen lukuoperaatio (dirty read)
Tapahtuma T2 lukee taulusta sellaisen rivin, jota toisen tapahtuman T1 operaatio on päivittänyt, mutta tapahtumaa T1 johon kirjoitusoperaatio sisältyy, ei ole vahvistettu (commit). Ongelma likaisessa luvussa on mahdollisuus, että päivitystä ei koskaan suoriteta onnistuneesti loppuun, vaan se peruutetaan (rollback).
| T1 | T2 |
|---|---|
BEGIN; |
|
BEGIN; |
|
UPDATE tiliSET saldo = saldo + 100WHERE tilinro = ?; |
|
SELECT saldoFROM tiliWHERE tilinro = ?; |
|
ROLLBACK; |
Nyt tapahtumat T1 päivittää tilin saldoa, mutta kirjoitusoperaatio peruutetaan. Ennen kirjoitusoperaation peruuttamista tapahtuma T2 on ehtinyt lukea tilin uuden saldon. Jos vahvistamattomien tietueiden lukua ei sallittaisi, yllä kuvattua ongelmatilannetta ei voisi tapahtua.
Alla on esitetty taulukko standardin mukaisilla eristyvyystasoilla esiintyvistä potentiaalisista ongelmista.
| Haamuluvut | Ei-toistettavat luvut | Likaiset luvut | |
|---|---|---|---|
| Sarjallistuva | ei | ei | ei |
| Toistettavat lukuoperaatiot | kyllä | ei | ei |
| Vahvistettujen tietueiden luku | kyllä | kyllä | ei |
| Vahvistamattomien tietueiden luku | kyllä | kyllä | kyllä |
5. Normalisointi
Luvuissa 2 ja 3 käsiteltiin tietokannan suunnittelua analyysivaiheessa ottamatta suuresti kantaa siihen, millainen on hyvin suunniteltu tietokanta. Tässä luvussa käsitellään formaalia, normalisoinniksi kutsuttua teoriaa relaatiotietokannan suunnittelun taustalla. Tietokannan normalisointia käsitellään tässä luvussa inkrementaalisesti heikoimmasta normaalimuodosta vahvimpaan.
5.1 Normalisoinnin tarkoitus
Normalisointi voi olla ratkaisu kahteen ongelmaan. Sillä voidaan:
- korjata tietokannan virheellistä loogista rakennetta ja
- vähentää datan toisteisuutta (redundancy) muuten loogisesti oikeellisesti suunnitellussa rakenteessa.
Virheellisellä loogisella rakenteella tarkoitetaan huonosti kohdealuetta kuvaavien attribuuttien nimiä, rakenteita, jotka suosivat runsaasti tyhjäarvoja sekä relaatiorakenteita, joihin on tarpeettomasti valittu attribuutteja useasta reaalimaailman kohteesta.
Datan toisteisuudella tarkoitetaan samojen arvojen tarpeetonta toistamista. Toistamisesta seuraa erityisesti kasvavat tallennustilavaatimukset sekä erilaiset kirjoitusoperaatioista seuraavat poikkeamat. Tarkastellaan poikkeamia alla olevan, taulukkona esitetyn relaation opintosuoritus avulla.
| optun | opnimi | kurssitun | kurssinimi | arvosana |
|---|---|---|---|---|
| o7111 | Aatami Laippa | itka204 | Tietokannat | 5 |
| o7111 | Aatami Laippa | itkp113 | Oliosuunnittelu | 4 |
| o7111 | Aatami Laippa | tjta114 | Tietohallinto | HYV |
| o6800 | Bertta Hukari | itka204 | Tietokannat | 5 |
| o6604 | Cecilia Rastas | tjta114 | Tietohallinto | HYV |
Poikkeamat jaetaan lisäys-, poisto- ja muokkausoperaatioista johtuviin poikkeamiin (Codd 1972b). Tarkastellaan esimerkkejä poikkeamista yllä olevan taulukon mukaisessa relaatiossa. Relaatio on tietokannan ainoa.
- Jos lisätään opiskelijalle o7111 uusi opintosuoritus, on varmistuttava sekä opiskelijan että kurssin nimen yhdenmukaisuudesta muiden monikkojen suhteen.
- Jos poistetaan viimeinen kurssia itkp113 koskeva opintosuoritus, myös kurssin nimi katoaa tietokannasta.
- Jos muokataan kurssin tjta114 nimeä, muokkaus joudutaan tekemään jokaiselle kurssia koskevalle monikolle, tai data ei ole yhdenmukaista.
5.2 Funktionaalinen riippuvuus
Normalisoinnin tärkein käsite on funktionaalinen riippuvuus (functional dependency). Funktionaalisella riippuvuudella tarkoitetaan attribuutin arvon määräytymistä saman relaation attribuuttijoukon (joukossa on tästedes 1..n attribuuttia ellei toisin mainita) arvon perusteella. Funktionaalista riippuvuutta merkitään attribuuttien nimillä ja nuolilla, jossa nuoli osoittaa määräävästä attribuuttijoukosta riippuvaan attribuuttiin tai attribuutteihin:

Yllä oleva luetaan "Y on funktionaalisesti riippuvainen X:stä". Toisin sanoen, relaatiossa R pätee funktionaalinen riippuvuus  , jossa {X} on määräävä attribuuttijoukko, josta Y riippuu, jos {X}:n arvon ollessa a relaation R monikoilla, on Y:n arvo jokaisella vastaavalla monikolla aina b. Tarkastellaan funktionaalista riippuvuutta alla olevan taulukkona esitetyn relaation henkilö avulla.
, jossa {X} on määräävä attribuuttijoukko, josta Y riippuu, jos {X}:n arvon ollessa a relaation R monikoilla, on Y:n arvo jokaisella vastaavalla monikolla aina b. Tarkastellaan funktionaalista riippuvuutta alla olevan taulukkona esitetyn relaation henkilö avulla.
| htun | nimi |
|---|---|
| 010160-ABCD | Aatami Laippa |
| 020270-EFGH | Bertta Hukari |
| 030380-IJKL | Aatami Laippa |
| 040490-MNOP | Cecilia Rastas |
Yllä olevassa relaatiossa on kaksi attribuuttia, ja relaatiossa pätee funktionaalinen riippuvuus  , koska jokaisella monikolla, jolla htun-attribuutin arvo on a, on nimi-attribuutin arvo poikkeuksetta b. Kuitenkaan relaatiossa ei päde funktionaalinen riippuvuus
, koska jokaisella monikolla, jolla htun-attribuutin arvo on a, on nimi-attribuutin arvo poikkeuksetta b. Kuitenkaan relaatiossa ei päde funktionaalinen riippuvuus  , koska jokaisella monikolla, jolla nimi-attribuutin arvo on a, on htun-attribuutilla mahdollisesti muitakin arvoja. Yleisemmin voidaan sanoa, että attribuutti htun yksilöi nimen, mutta nimi ei yksilöi henkilötunnusta.
, koska jokaisella monikolla, jolla nimi-attribuutin arvo on a, on htun-attribuutilla mahdollisesti muitakin arvoja. Yleisemmin voidaan sanoa, että attribuutti htun yksilöi nimen, mutta nimi ei yksilöi henkilötunnusta.
On syytä huomata, että yllä mainitut funktionaaliset riippuvuudet on johdettu relaation sisällöstä. Tavallisesti normalisointitarkastelu tehdään silloin, kun tietokannassa ei ole vielä dataa, ja funktionaaliset riippuvuudet on pääteltävä kohdealuetta ymmärtämällä. Vaikka funktionaalisten riippuvuuksien esittämiseen käytetään matemaattista notaatiota, ei kysymyksessä ole matemaattinen ilmiö vaan nimenomaan relaation merkityksen ymmärtäminen.
| kurssikoodi | kurssinimi | vuosi | opettajatun | laajuus |
|---|---|---|---|---|
| itka201 | Algoritmit | 2015 | op447 | 4 |
| itka201 | Algoritmit | 2014 | op051 | 3 |
| itka204 | Tietokannat | 2014 | op300 | 5 |
| itka204 | Tietokannat | 2015 | op300 | 5 |
| itka204 | Tietokannat | 2013 | op300 | 4 |
| tjta118 | IT-infra | 2014 | op411 | 3 |
| tjta118 | IT-infra | 2015 | op411 | 3 |
5.2.1 Päättelysäännöt
Armstrong (1974) on esittänyt joukon sääntöjä, jotka pätevät funktionaalisiin riippuvuuksiin. Sellaisia funktionaalisia riippuvuuksia, joita ei voida edes teoriassa rikkoa, kutsutaan triviaaleiksi.
Refleksiivisyyssäännön (axiom of reflectivity) mukaan aina jos attribuutti Y on attribuuttijoukon {X} osajoukko, pätee triviaali funktionaalinen riippuvuus "Y riippuu X:stä".

Sääntö on myös esitettävissä muodossa "X riippuu itsestään":

Transitiivisuussäännön (axiom of transitivity) mukaan aina jos pätevät funktionaaliset riippuvuudet "Y riippuu X:stä" ja "Z riippuu Y:stä" pätee myös funktionaalinen riippuvuus "Z riippuu X:stä".

Yhdistesäännön (axiom of union) mukaan aina jos pätevät funktionaaliset riippuvuudet "Y riippuu X:stä" ja "Z riippuu X:stä", pätee myös funktionaalinen riippuvuus "Y ja Z riippuvat X:stä".

Jakosäännön (axiom of decomposition) mukaan aina, jos pätee funktionaalinen riippuvuus "Y ja Z riippuvat X:stä", pätevät myös funktionaaliset riippuvuudet "Y riippuu X:stä" ja "Z riippuu X:stä".

Täydentämissäännön (axiom of augmentation) mukaan aina, jos pätee funktionaalinen riippuvuus "Y riippuu X:stä", pätee myös funktionaalinen riippuvuus "Y riippuu X:n ja Z:n yhdistelmästä", ts. jos "Y riippuu X:stä", niin "Y riippuu myös kaikista X:n ylijoukoista".

Huomaa kuitenkin, että määräävää attribuuttijoukkoa ei välttämättä voi jakaa osiin.
Alla olevassa kuviossa on esitetty toinen tapa kuvata funktionaalisia riippuvuuksia. Nuoli osoittaa tässäkin määräävästä attribuuttijoukosta riippuvaan attribuuttiin. Funktionaaliset riippuvuudet on numeroitu monivalintatehtävän vuoksi.
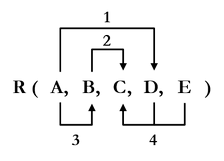
5.3 Normaalimuodot
Normalisointi on relaatiokohtaista, toisin sanoen kaikkien tietokannan relaatioiden ei tarvitse olla samassa normaalimuodossa. Myös normalisointitarkastelu tehdään aina relaatiokohtaisesti. Normalisoinnin tuloksia on kuitenkin tarkasteltava tietokantakohtaisesti: menetettiinkö normalisoinnin tuloksena informaatiota vai onko normalisointi suoritettu oikein? Normalisointiprosessi on inkrementaalinen: jokainen esitetty normaalimuoto on edellistä vahvempi, ja vaatii että relaatio täyttää edellisen normaalimuodon vaatimukset. Lihavoidut määritelmät kussakin alaluvussa ovat Elmasri & Navathen (2007) mukaiset. Määritelmät eivät ole formaaleja.
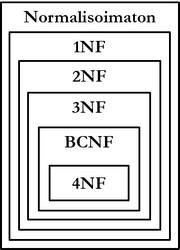
Jos relaatio ei täytä jonkin normaalimuodon vaatimuksia, se täytyy jakaa relaatioalgebran mukaisella projektiolla osiin, jotta normaalimuodon vaatimukset saavutetaan. Jaon täytyy tapahtua siten, että
- jakamisen tuloksena syntyvien relaatioiden liitos ei tuota erilaisia monikoita kuin alkuperäinen relaatio,
- jokainen jaettavassa relaatiossa esiintyvä funktionaalinen riippuvuus säilytetään jossakin jaon tuloksena muodostetussa relaatiossa tai näiden liitoksessa niin, että liitos ei tuota vääriä (spurious) monikoita ja
- lopulta relaatioita ei ole määrällisesti enempää kuin mitä tavoitellun normaalimuodon saavuttaminen vaatii.
Ennen normalisointitarkastelua on erityisen tärkeää tunnistaa relaation avainehdokkaat ja mahdollisesti myös valita niistä sopivin relaation perusavaimeksi. Jos perusavain on valittu väärin, normalisointitarkastelu voi menettää merkityksensä.
5.3.1 Ensimmäinen normaalimuoto
Kuten luvussa 3 mainittiin, relaation, jonka kaikki attribuutit ovat atomisia, sanotaan olevan normalisoitu. Muussa tapauksessa relaatio on normalisoimaton eikä täten relaatiomallin mukainen. Myöhemmin teorian tarkennuttua normalisoitua relaatiota on alettu kutsua ensimmäisen normaalimuodon (first normal form, 1NF) täyttäväksi relaatioksi.
Määritelmä: relaatio on 1NF:ssä, jos sen kaikki attribuutit ovat atomisia ja sopivaa tyyppiä.
Sopivalla tyypillä tarkoitetaan, että mikään attribuutti ei ole viittaus toiseen relaatioon (attribuutti voi kuitenkin olla viittaus toisen relaation attribuuttiin), eikä samaa tyyppiä kuin relaatio, johon attribuutti kuuluu.
Mitä “relaation tyyppi” tarkoittaa? En löytänyt määritelmää tästä monisteesta.
T: tämä on tosiaan epäselvästi ilmaistu. Käytännössä kohta tarkoittaa, että attribuutti ei saa olla lista, eikä myöskään mikään monimutkaisempi tietorakenne, esim. relaatio.
—On syytä huomata, että relaation täytyy todella olla alaluvussa 3.1 määritelty relaatio, jotta se voi täyttää 1NF:n vaatimukset. Ensimmäisen normaalimuodon vaatimukset täyttämätön SQL-taulu voisi olla seuraava:
| htun | puhelin |
|---|---|
| 010160-ABCD | 0401234567 |
| 020270-EFGH | [014123456, 040556123, 014567123] |
| 030380-IJKL | [05012345, 05098765] |
5.3.2 Toinen normaalimuoto
Toiseen normaalimuotoon (second normal form, 2NF) liittyy käsite täydestä funktionaalisesta riippuvuudesta (full functional dependency). Täydellä funktionaalisella riippuvuudella tarkoitetaan funktionaalista riippuvuutta , jossa attribuuttijoukkoa {X} ei voida jakaa osiin niin, että funktionaalinen riippuvuus säilytetään, joten myöskään täyden funktionaalisen riippuvuuden määräävää attribuuttijoukkoa ei voida jakaa osiin, ts. attribuutin Y arvo ei voi määräytyä {X}:n aidon osajoukon perusteella.
Määritelmä: relaatio on 2NF:ssä, jos se on 1NF:ssä ja relaation kaikki perusavaimeen kuulumattomat attribuutit ovat täysin funktionaalisesti riippuvia relaation perusavaimesta.
Alla olevassa kuviossa on kuvattu relaatiokaava R, joka ei ole 2NF:ssä. Funktionaalinen riippuvuus  rikkoo 2NF:n sääntöä, sillä D on riippuvainen relaation perusavaimen aidosta osajoukosta.
rikkoo 2NF:n sääntöä, sillä D on riippuvainen relaation perusavaimen aidosta osajoukosta.
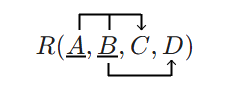
Jotta yllä olevasta relaatiokaavasta saataisiin 2NF:n vaatimukset täyttävät, se tulee jakaa. Jaon tuloksena saadaan relaatiot
- R1(A,B,C), jossa pätee funktionaalinen riippuvuus
 .
. - R2(B,D), jossa pätee funktionaalinen riippuvuus .
5.3.3 Kolmas normaalimuoto
Kolmanteen normaalimuotoon (third normal form, 3NF) liittyy käsite transitiivisesta riippuvuudesta. Transitiivisella riippuvuudella tarkoitetaan riippuvuutta  , jossa {X} on relaation perusavain ja funktionaaliset riippuvuudet ja
, jossa {X} on relaation perusavain ja funktionaaliset riippuvuudet ja  pätevät. Tällöin sanotaan, että attribuutti Z on transitiivisesti riippuvainen relaation perusavaimesta.
pätevät. Tällöin sanotaan, että attribuutti Z on transitiivisesti riippuvainen relaation perusavaimesta.
Määritelmä: relaatio on 3NF:ssä, jos se on 2NF:ssä ja mikään relaation perusavaimeen kuulumaton attribuutti ei ole transitiivisesti riippuvainen relaation perusavaimesta.
Poikkeus: Jos 3NF:ää rikkovan transitiivisen riippuvuuden määräävä attribuuttijoukko on relaation avainehdokas, riippuvuus ei riko 3NFää.
Alla olevassa kuviossa kuvattu relaatiokaava R on 2NF:ssä, mutta ei 3NF:ssä, sillä attribuutti C on transitiivisesti riippuvainen relaation perusavaimesta {A}. Toisin sanoen relaatiossa pätee transitiivinen riippuvuus  , sillä funktionaaliset riippuvuudet
, sillä funktionaaliset riippuvuudet  ja
ja  pätevät.
pätevät.
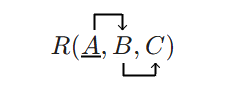
Jotta yllä olevasta relaatiokaavasta saataisiin 3NF:n vaatimukset täyttävä, se tulee jakaa osiin:
- R1(A,B), jossa pätee funktionaalinen riippuvuus .
- R2(B,C), jossa pätee funktionaalinen riippuvuus .
Huomaa, että transitiivisuussäännön perusteella on pääteltävissä funktionaalinen riippuvuus .
5.3.4 Boyce/Codd-normaalimuoto
Boyce/Codd-normaalimuoto (Boyce/Codd normal form, BCNF) tarkastelee attribuuttien funktionaalista riippuvuutta relaation avainehdokkaista ja niiden ylijoukoista (ts. superavaimista).
Määritelmä: relaatio on BCNF:ssä, jos se on 3NF:ssä ja jokaisen funktionaalisen riippuvuuden määräävä attribuuttijoukko {X} on myös relaation superavain.
Alla olevassa kuviossa on kuvattu relaatiokaava R, joka on 3NF:ssä, mutta ei BCNF:ssä, sillä relaatiossa pätee funktionaalinen riippuvuus  , mutta attribuuttijoukko {B,C} ei ole relaation superavain.
, mutta attribuuttijoukko {B,C} ei ole relaation superavain.
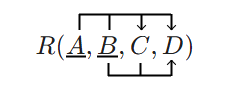
Jotta yllä olevasta relaatiokaavasta saataisiin BCNF:n vaatimukset täyttävät, se tulee jakaa osiin:
- R1(A,B,C), jossa pätee funktionaalinen riippuvuus .
- R2(B,C,D), jossa pätee funktionaalinen riippuvuus .
5.3.5 Neljäs normaalimuoto
Neljänteen normaalimuotoon (fourth normal form, 4NF) liittyy käsite moniarvoisesta riippuvuudesta (multivalued dependency, MVD). Moniarvoisella riippuvuudella tarkoitetaan tilannetta, jossa relaatio R sisältää attribuuttijoukot X, Y ja Z. Jokaisella monikolla, jolla X:n arvo on a, on Y:n arvojoukko b riippumatta Z:n arvoista sekä jokaisella monikolla, jolla X:n arvo on c, on Z:n arvojoukko d riippumatta Y:n arvoista. Tällöin sanotaan, että Y ja Z ovat moniarvoisesti riippuvaisia X:stä.
Moniarvoinen riippuvuus  on triviaali, jos
on triviaali, jos
- Y on X:n osajoukko tai
- X:n ja Y:n lisäksi relaatiossa ei ole muita attribuutteja eli
 .
.
Määritelmä: relaatio on 4NF:ssä, jos se on BCNF:ssä ja jokaisen ei-triviaalin moniarvoisen riippuvuuden määräävä attribuuttijoukko {X} on relaation superavain.
Otetaan esimerkiksi alla oleva taulukkona kuvattu relaatio kurssitoteutus (Hoffer, Prescott, McFadden 2002, s. 592). Relaatioon on kuvattu, mitä kurssia opettavat mitkäkin opettajat ja mitä kurssikirjoja kursseilla käytetään. Relaation perusavain on  , ja relaatio on BCNF:ssä. Kurssikirja on riippumaton kurssin opettajasta.
, ja relaatio on BCNF:ssä. Kurssikirja on riippumaton kurssin opettajasta.
| kurssitun | opettaja | kirja |
|---|---|---|
| itka204 | o100 | Fundamentals |
| itka204 | o100 | Basics |
| itka204 | o222 | Fundamentals |
| itka204 | o222 | Basics |
| itkp113 | o333 | Objects |
| itkp113 | o333 | Patterns |
Näinollen relaatiossa pätevät moniarvoiset riippuvuudet  ja
ja  . Koska kurssitun ei ole relaation superavain, molemmat moniarvoiset riippuvuudet rikkovat neljännen normaalimuodon vaatimusta. Jotta relaatio täyttäisi 4NF:n vaatimukset, se tulee jakaa osiin:
. Koska kurssitun ei ole relaation superavain, molemmat moniarvoiset riippuvuudet rikkovat neljännen normaalimuodon vaatimusta. Jotta relaatio täyttäisi 4NF:n vaatimukset, se tulee jakaa osiin:
- KURSSIN_OPETTAJA (kurssitun, opettaja)
- KURSSIN_KIRJA (kurssitun, kirja)
Tyypillinen ongelmatilanne 4NF:n suhteen on transformointisääntöjen vastaisesti transformoitu kohdetyyppi, jolla on ollut useampi kuin yksi moniarvoinen attribuutti. Neljännen normaalimuodon tarkastelussa on syytä kiinnittää erityistä huomiota relaatioihin, joiden jonkin attribuutin arvoa joudutaan tarpeettomasti toistamaan, jotta kaikki data saadaan tallennettua.
Normaalimuotoja on todellisuudessa muitakin. Jotkin niistä ovat vaativuudeltaan käsiteltyjen normaalimuotojen välissä, mutta useimmat ovat käsiteltyjä normaalimuotoja vahvempia. Erityisesti viides normaalimuoto vaatisi formaalia tarkastelua.
Vaikka relaatiomalli ei ota kantaa relaatiotietokannan fyysiseen suunnitteluun, useat tuotteet jakavat taulut eri tiedostoiksi levyllä. Tietokannan vahva normalisointi (esim. BCNF:ään) johtaa taulujen määrän kasvuun, joka johtaa tiedostojen määrän kasvuun, joka johtaa yhä hitaampiin lukuoperaatioihin. Toisaalta normalisoinnilla vähennetään toisteisuutta, joka vähentää tai poistaa kokonaan kirjoitusoperaatioista johtuvat poikkeamat sekä nopeuttaa kirjoitusoperaatioita. Onkin kohdealuekohtaisesti päätettävä, mihin normaalimuotoon tai normaalimuotoihin tietokannan relaatiot normalisoidaan.
Normalisoinnista seuraa tavallisesti relaatioiden jako asteluvultaan pienempiin relaatioihin. Denormalisointi puolestaan pyrkii väljentämään relaatioiden normaalimuotoja, joka tavallisesti johtaa relaatioiden yhdistämiseen. Normalisointia ja denormalisointia voidaankin pitää toistensa vastakohtina.
6. Tietovarastointi
Tietovarastoinnilla (data warehousing) tarkoitetaan suunnitelmallista ja jaksotettua datan kopioimista, muuntamista ja jalostamista useista eri lähteistä ympäristöön, joka on tarkoitettu tiedon analysointiin. Tätä kohdetietokantaa tai -tietokantoja kutsutaan tietovarastoksi (data warehouse).
6.1 Yleistä tietovarastoinnista
Organisaatiot, joilla on vain yksi tietokanta, ovat harvinaisia. Organisaatioilla on yhä enemmän ja enemmän dataa, ja data sijaitsee eri tietokannoissa hyvinkin erilaisissa muodoissa. Koska operatiiviset tietokannat ovat tarkoitettuja pääasiassa päivittäisen liiketoiminnan mahdollistamiseksi, ne harvoin tyydyttävät organisaation johtajien tai analyytikoiden tietotarpeita. Tiedonhallinnan kannalta tietovarastointi edesauttaa merkittävästi organisaation menestymistä.
Tässä alaluvussa tutustutaan tietovarastoinnin yleiseen arkkitehtuuriin ja tarkoitukseen.
6.1.1 Arkkitehtuuri
Alla olevassa kuviossa on kuvattu tietovarastoinnin yleinen arkkitehtuuri käyttäen esimerkkinä pankkia. Pankilla on kaksi operatiivista eli päivittäisen liiketoiminnan mahdollistavaa tietokantajärjestelmää (online transaction processing, OLTP): maksuliikenne ja pörssi. Lisäksi kuviossa on pankin ulkopuolinen, luottolaitoksen tietokantajärjestelmä luottotiedot, jota pankki käyttää. Nämä tietokantajärjestelmät sisältävät ns. lähdetietokannat, jotka tavallisesti muistuttavat loogiselta rakenteeltaan tällä kurssilla jo käsiteltyjä tietokantoja.
Lähdetietokannoista kerätään haluttu data (extract, E) ns. lataustietokantaan (staging area). Koska data kerätään mahdollisesti hyvinkin erilaisista lähteistä, se täytyy muuntaa yhtenäiseen muotoon. Lisäksi datasta suodatetaan huonolaatuinen, virheellinen ja muuten ei-toivottu data sekä mahdollisesti johdetaan haluttu tieto. Kaikki tämä muuntoprosessi (transform, T) suoritetaan lataustietokannassa. Lataustietokanta on varsinaisen tietokannan lisäksi joukko väliohjelmistoja (middleware). Lopuksi muunnettu data saatetaan (load, L) varsinaiseen tietovarastoon (data warehouse), tavallisesti jaksottain eräajona, esimerkiksi kerran viikossa tai jokaisen vuosineljänneksen päätteeksi.
Lataustietokanta tyhjennetään tasaisin väliajoin. Tietovarastoa on kuvattu kuviossa yhdellä tietokannalla, mutta tavallisesti tietovarastoon kuuluu useita tietokantoja. Väliohjelmiston toteuttama ETL-prosessi on kohdealueen tarpeista riippuen monimutkainen, erityisesti datan laadunvalvonnan osalta. On myös mahdollista, että laadunvalvontaprosessin päätteeksi dataa syötetään takaisin lähdetietokantoihin. Näin virheellinen tai muuten puutteellinen data korjataan myös lähdetietokannoissa.
Lopuksi tietovaraston data voidaan jakaa ns. paikallisvarastoihin (data mart). Paikallisvarastot voivat olla fyysisiä tietokantoja tai ne voidaan toteuttaa puhtaasti loogisilla tietorakenteilla kuten näkymillä. Tietovaraston jako paikallisvarastoihin helpottaa monimutkaisen rakenteen ymmärtämistä sekä rajoittaa loppukäyttäjien oikeuksia jalostettuun dataan. Paikallisvarastojen tai tietovaraston dataa käsitellään edelleen raportoimalla, analysoimalla ja louhimalla.
6.1.2 Tarkoitus
Tietovarastointi voi olla yrityksen sisäinen tapa saavuttaa hyötyä tai tietovarastointi voi itsessään olla liiketoimintaa. Tietovarastoinnin juuret ovatkin markkinatutkimuksessa, jonka kaikki data kerätään ulkopuolisista lähteistä. Kun organisaation data on kerätty tietovarastoon, dataa voidaan hyödyntää eri tavoin edistämään liiketoimintaa, esimerkiksi päätöksenteon apuna, markkinoiden ennustamisessa tai uhkien kartoittamisessa.
Teknisemmästä näkökulmasta (Inmon 1992) tietovarastoinnin tarkoituksena on yhdistää eritasoisissa ja eri-ikäisissä tietojärjestelmissä (legacy systems) oleva epäyhtenäinen ja eriaikainen (time-variant) tieto tietyistä aihe-alueista (subject-oriented) pysyvästi tallennetuksi (non-volatile) ja mielekkäällä tavalla haettavaksi.
Tietovaraston datan hyödyntäminen voidaan jakaa hyödyn tavoittelun näkökulmasta kolmeen osaan:
- Raportointiin, jonka avulla saadaan yksinkertaisia vastauksia yksinkertaisiin kysymyksiin kuten "Mitä tapahtui lainojen koroissa vuoden 2015 ensimmäisellä kvartaalilla".
- Analysointiin, jonka avulla saadaan vastauksia monimutkaisiinkin kysymyksiin kuten "Mitä on tapahtunut punaisten tuotteiden myynnissä vuonna 2014 ja miksi". Liiketoimintatiedon analysoinnin työkaluja ja tekniikoita kutsutaan yleisesti nimellä OLAP (online analytical processing).
- Tiedonlouhintaan, jonka avulla saadaan monimutkaisiakin vastauksia monimutkaisiinkin kysymyksiin kuten "Mitä kehitystä todennäköisesti tapahtuu Ranskan bruttokansantuotteessa vuonna 2020" tai "Mitä mielenkiintoista yrityksen henkilöstössä tapahtuu ensi vuonna". Tiedonlouhintaa käsitellään yleisellä tasolla tämän luvun lopussa.
6.1.3 Ydintieto
Organisaation keskeinen tieto eli ydintieto (master data) kootaan yhteen ja vain yhteen paikkaan oikeellisuuden varmistamiseksi. Ydintieto on tietoa, joka on organisaatiossa tunnustettu oikeelliseksi ja toimijoiden kesken jaettu. Ydintieto voi olla organisaation toiminnan kannalta kriittistä dataa (esimerkiksi pankin tilitiedot), mutta ydintiedon ei tarvitse rajoittua siihen. Ydintietoon ja sen hallintaan liittyy datan kannalta kaksi keskeistä käsitettä: system of entry (SOE) tarkoittaa datan lähdettä (esim. ERP-järjestelmä), joka on hyväksytty, ts. tunnustettu luotettavaksi. Koska hyväksyttyjä datalähteitä voi olla useita, täytyy ristiriitojen ilmetessä olla keino varmistua siitä, mikä hyväksytyistä tietoalkioista on oikea. Käsitteellä system of record (SOR) tarkoitetaan oikeelliseksi tunnustettua versiota datasta. Niitä voi olla ainoastaan yksi, jolloin ei ole edes teoriassa mahdollista, että data on ristiriitaista.
- Downstream-toteutus on tavallisesti yksinkertaisin toteuttaa, mutta datan jäljittäminen takaisin oikeaan lähdejärjestelmään voi olla haastavaa. Tässä toteutuksessa organisaation tietojärjestelmät toimivat hyväksyttyinä datan lähteinä. Data tuodaan integrointiprosessiin, joka muistuttaa tietovarastointiarkkitehtuurin muunnosprosessia (transform). Dataa voidaan tarvittaessa syöttää takaisin lähdejärjestelmiin. Integroinnin jälkeen data tuodaan rakenteelliseen tietokantaan, joka toimii oikeellisena datana. Tätä dataa käytetään edelleen raportointiin, analysointiin ja tiedonlouhintaan.
- Hub-toteutuksessa yksi lähdejärjestelmä toimii ainoana hyväksyttynä datalähteenä ja oikeellisena versiona datasta. Data syötetään muihin organisaation tietojärjestelmiin sellaisessa muodossa, jossa tietojärjestelmät sitä tarvitsevat.
- Enterprise-toteutus on tavallisesti vaativin toteuttaa. Siinä ydintietokanta toimii sekä hyväksyttynä datan lähteenä ja oikeellisena datana. Vaikka data alun perin tuodaan lähdetietojärjestelmistä, sen tulee läpäistä integrointiprosessi ennen kuin data on todettu oikeelliseksi. Oikeelliseksi todettu data syötetään takaisin lähdetietojärjestelmiin.
6.2 Tietovaraston kehittäminen
Tietovaraston kehittämisen vaiheet noudattavat pääpiirteiltään tietojärjestelmän kehitysvaiheita. Vaiheet eivät ole tiukasti perättäisiä, vaan osittain limittäisiä ja vaiheisiin voidaan palata. Kehittämisen tekevät tavallisesti ohjelmoijista ja analyytikoista (tai muista kohdealueen liiketoimintalogiikan tuntijoista) koostuva ryhmä. Tietovarastoinnin kehityksessä toimijoiden yhteistyö on erityisen tärkeää.
6.2.1 Analyysi ja suunnittelu
Ensimmäiseksi on valittava tietovarastoinnin painopisteet tai fokukset, eli mitä tietovarastoinnilla halutaan saavuttaa. Painopisteiden on oltava selvästi eroteltavissa, ja niitä voi olla useita. Painopiste voi olla esimerkiksi:
- Kenelle voidaan antaa lainoja ja millaisella korolla?
- Mitä tuotteita tuotetta X verkkokaupassa katselleet lopulta ostivat?
Seuraavaksi selvitetään, millaisella informaatiolla vaatimukset saavutetaan.
Lisäksi selvitetään, mitä dataa tarvitaan tarvittavan informaation johtamiseen, ja mistä lähteistä data saadaan. Päätetään myös, kuinka kauan dataa säilytetään. Esimerkiksi vartioimisliikkeen tulee lain mukaan säilyttää tapahtumailmoitukset viisi vuotta. Toisaalta verkkokauppa voi haluta säilyttää myyntihistoriansa perustamisvuodesta lähtien.
Suunnitteluun kuuluu looginen ja fyysinen suunnittelu: tietokannan skeeman, indeksien, tietotarpeiden ja saantipolkujen, laitteiston sekä integroinnin suunnittelu. Valitaan myös OLAP-työkalut, jotka tukevat tietotarpeita ja valittuja tekniikoita. Jos tietovarasto toteutetaan relaatiotietokannalla, suunnitellaan mahdolliset summataulut ja näkymät. Summataulut ovat tauluja, jotka sisältävät johdettua dataa. Tämä johdettu data tavallisesti vastaa usein toistuviin, koostamista vaativiin tietotarpeisiin. Summataulun avulla dataa ei tarvitse koostaa jokaisen kyselyn yhteydessä, vaan data on jo koostettuna taulussa.
Tietovarastojen ja operatiivisten tietokantojen skeemat poikkeavat toisistaan. Kolme tietovarastojen tunnistettua skeemaa ovat ns. tähti-, lumihiutale- ja tähtihiutalemallit. Kaikissa malleissa on yhteistä tietokannan skeeman keskiössä sijaitseva faktataulu tai faktataulut. Faktataulu on kuten luvussa 3 käsitelty suhderelaatio, joka yhdistää useat kohteet toisiinsa ja sisältää mitattavaa dataa tapahtumista, esimerkiksi tilauksista tai tilisiirroista. Faktataululle on tavallista, että sillä on moniosainen perusavain, joka koostuu muiden, ns. ulottuvuustaulujen perusavaimista. Ulottuvuustaulut ovat kuten kohderelaatioita: ne sisältävät kuvaavaa dataa esimerkiksi tuotteista tai asiakkaista. Perusavaimensa lisäksi faktataululla voi olla lisäsarakkeita.
Tähtimalliksi kutsutaan tietovaraston skeemaa, jonka ulottuvuustauluja ei ole pitkälle normalisoitu. Lumihiutalemallin mukaisessa skeemassa ulottuvuustaulut on normalisoitu esimerkiksi 3. normaalimuotoon. Tähtihiutalemalli on ns. hybridimalli, jossa jotkin ulottuvuustaulut ovat pitkälle normalisoituja ja toiset eivät.
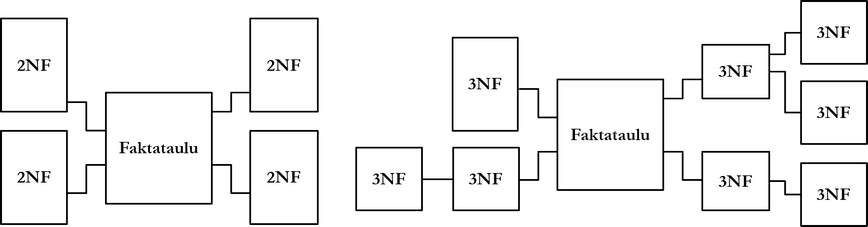
Suunniteluvaiheessa myös päätetään, käytetäänkö operatiivista tietovarastoa (operational data store, ODS). Sen avulla voidaan tarkastella reaaliaikaista operationaalista dataa OLAP-työkaluilla, vaikka dataa ei olisi vielä tuotu tietovarastoon. Tekniikan heikkoutena ovat kasvavat tallennustila- ja tiedonsiirtovaatimukset.
6.2.2 Toteutus, käyttöönotto ja ylläpito
Tässä vaiheessa toteutetaan tietovarasto ja lataustietokanta. Toteutetaan datan kerääminen lähdetietokannoista (extract), datan käsittely lataustietokannassa (transform) ja käsitellyn, laadukkaan datan saattaminen tietovarastoon (load). Potentiaalisia ongelmia ETL-vaiheissa (extract-transform-load) voivat olla esimerkiksi
- Data kerätään monesta eri lähteestä. Eri lähteiden data voi olla toisteista, ja toisteisuus voi olla hankalaa havaita. Esimerkiksi yksi järjestelmä tallentaa tuotenumerot eri muodossa kuin toinen.
- Dataa voi liikkua lataustietokantaan ja sieltä pois huomattavia määriä. Milloin on operatiivisesti hyväksyttävää kuormittaa tietokantajärjestelmää tietovarastoinnilla?
- Käytetäänkö operaationaalista tietovarastoa?
- Miten datan laatua mitataan ja miten heikkolaatuista datan tulee olla jotta se hylätään?
- Miten reagoidaan ja varaudutaan esim. loogisen rakenteen muutoksiin erityisesti ulkoisissa lähdetietokantajärjestelmissä?
Lataustietokannan väliohjelmisto toteutetaan, tai jos käytetään kolmannen osapuolen ohjelmistoja, liitetään tietovarastoon.
Tässä vaiheessa tietovarasto ja OLAP-työkalut esitellään niitä käyttäville loppukäyttäjille. Lisäksi koulutetaan, miten tietoa noudetaan tietovarastosta ja miten tietoa hyödynnetään.
Jos suunnitteluvaiheessa ei ole suunniteltu paikallisvarastoja, ne voidaan luoda tässä vaiheessa. Paikallisvarastot palvelevat tiettyjä tietotarpeita, esimerkiksi markkinoinnin paikallisvaraston avulla markkinointiosaston analyytikot voivat saada tietoa tuotteiden myyntimääristä. Paikallisvarastojen sisältämä data on joko kerätty kokonaisuudessaan tietovarastosta tai se voi sisältää lisäksi muutakin dataa. Ensimmäistä tulkintaa kutsutaan Inmonin koulukunnaksi (Inmon 1992) ja jälkimmäistä Kimballin koulukunnaksi (Kimball 1996).
Paikallisvarastojen sisältämä data suunnitellaan painopisteitä vastaaviksi. Painopisteet voivat olla hyvinkin monimuotoisia, esimerkiksi
- Maantieteelliseen sijaintiin perustuvia, esimerkiksi Jyväskylän toimistojen paikallisvarasto.
- Yrityksen eri osastojen tietotarpeisiin perustuvia, esimerkiksi pankin riskit ja asiakasprofiilit.
- Datan koontiin perustuvia, esimerkiksi koko yrityksen myynti maailmanlaajuisesti.
- Markkina-alueisiin perustuvia, kuten yritysten x ja y osuus markkinoista.
- Datan arkaluontoisuuteen perustuvia, esimerkiksi jokin paikallisvarasto voi olla julkinen, toinen vain organisaation johdon käyttöön ja kolmannen data myytävänä kolmansille osapuolille.
Alla olevaan taulukkoon on koottu tietovarastojen ja operatiivisten tietokantojen (OLTP) eroja eri näkökulmista (Elmasri & Navathe 2007 sekä Watson 2006, s. 433-453).
| Operatiivinen tietokanta | Tietovarasto | |
|---|---|---|
| Käyttötarkoitus | Päivittäinen liiketoiminta | Analysointi, suunnittelu, ongelmanratkaisu |
| Datan lähde | Sovellusohjelma, käyttäjät | Lähdetietokannat |
| Datan rakeisuus | Tarkka | Koottu, tarkka |
| Datan luonne | Dynaaminen tilannekuva | Staattinen historia, koonti |
| Datan määrä | Pieni, keskikokoinen | Suuri, massiivinen |
| Hakulauseet | Yksinkertaisia, vähän rivejä palauttavia | Monimutkaisia, koostavia |
| Muokkauslauseet | Loppukäyttäjiltä tulevia: pieniä, nopeita | Eräajo: suuria, hitaita |
| Indeksejä | Vähän | Paljon |
| Normaalimuoto | Pitkälle normalisoitu | Denormalisoitu |
| Palvelee | Lähes kaikkia asiakkaita | Osaa käyttäjistä |
| Käyttötapa | Toistuvaa, ennustettavissa | Rakenteeton, heuristinen, ennustamaton |
6.3 Tietovarastointi ja liiketoiminta
Tässä alaluvussa tarkastellaan tietovarastointiin liittyvien käsitteiden ja tekniikoiden kehittymistä liiketoiminnan näkökulmasta.
6.3.1 Tiedonlouhinta ja siihen liittyvä kehitys
Tiedonlouhinnalla (data mining) tarkoitetaan tilastomenetelmiin pohjautuvien algoritmien avulla toteutettua tiedon jalostamista suurista datamääristä käytettäväksi liiketoiminnan päätöksenteossa. Tiedonlouhinnan voisi yleisellä tasolla sanoa eroavan analyysistä monimutkaisuudellaan ja siten, että datan analysointi pyrkii vastaamaan ennalta määrättyyn kysymykseen, kun tiedonlouhinta puolestaan pyrkii etsimään mielenkiintoisia malleja datasta, vaikka loppukäyttäjä ei erityisesti mitään kysyisikään.
Tiedonlouhintaa voidaan soveltaa tietovarastoihin tai operatiivisiin tietokantoihin. Data täytyy ennen louhintaa valmistella louhittavaksi. Valmistelu voi pitää sisällään samantyyppisiä operaatioita kuin tietovarastoinnin käsittelyvaihe (transform):
- Erotetaan oikeellinen, virheellinen ja häiriöllinen data toisistaan. Häiriöllisellä (noisy) datalla tarkoitetaan dataa, jonka arvot ovat mahdollisesti virheellisiä, esimerkiksi 20% rekisteröityneistä käyttäjistä on syntynyt 1. tammikuuta.
- Päätetään, mitä tehdään puuttuvien arvojen suhteen. Esimerkiksi potilastiedoissa voi olla paljon tyhjäarvoja sukupuolesta tai iästä johtuen.
- Vähennetään louhittavien attribuuttien määrää niin, että tarkastellaan vain vertikaalisesti ositettua osajoukkoa datasta.
Tarkastellaan seuraavaksi muutamaa korkean tason esimerkkiä tiedonlouhintatekniikoista ja mitä niillä voidaan saavuttaa. Tekniikoiden jako perustuu löyhästi lähteeseen Leskovec, Rajaraman & Ullman (2014). Esitys ei ole kattava.
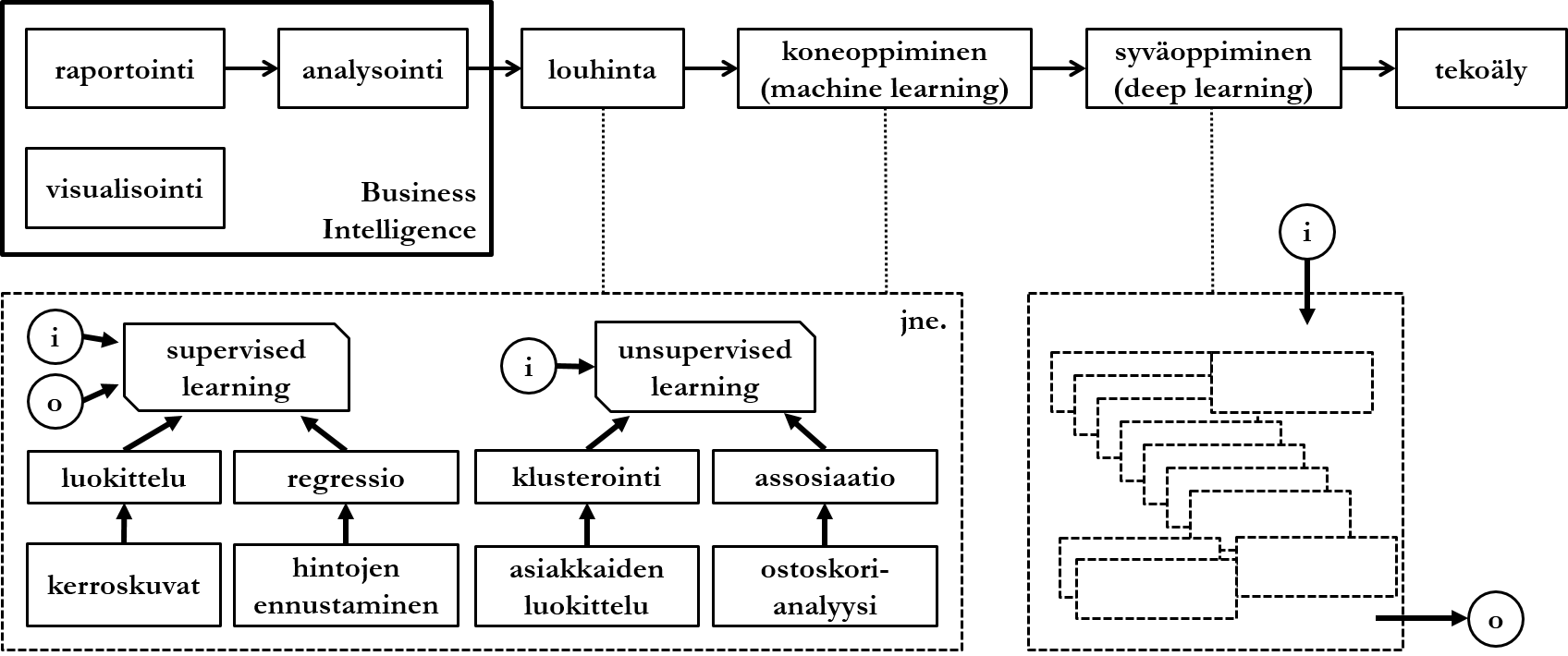
6.3.1.1 Ohjattu oppiminen
Tiedonlouhintatekniikat jaetaan usein ohjattuun (supervised), ohjaamattomaan (unsupervised) ja puoliohjattuun (semisupervised) oppimiseen (learning). Ohjattu oppiminen on yleisnimitys tekniikoille, jotka toimivat annetun syötteen ja odotetun tulosteen mukaisesti. Yksinkertaistettuna tällä tarkoitetaan, että varsinaisen analysoitavan datan (syöte) lisäksi algoritmille annetaan oppimisaineisto (odotettu tuloste), jota vastaan syöte analysoidaan.
Luokittelu (classification) on yksi yleisimmistä tiedonlouhinnan sovellutuksista. Luokittelualgoritmit pyrkivät ennustamaan epäjatkuvien (diskreettien) muuttujien arvoja perustuen muiden muuttujien arvoihin datassa:
- Yhtään demotehtävää tekemättömän opiskelijan kurssiarvosana on tavallisesti hylätty.
- Asiakas A käyttää luottokorttiaan tavallisesti Suomessa, Ruotsissa tai Virossa.
- Kerroskuvista voidaan tunnistaa, että tällä potilaalla ei ole keuhkosyöpää.
Luokittelualgoritmien tulosten perusteella voidaan ryhtyä jatkotoimenpiteisiin. Järjestelmä, joka toimii opiskelijan oppimisen tukena voi lähettää opiskelijalle muistutuksen demotehtävistä, tai pankki voi estää asiakkaan luottokortin käytön poikkeamiin perustuen.
Regressioalgoritmit pyrkivät ennustamaan jatkuvien muuttujien arvoja perustuen muiden muuttujien arvoihin datassa:
- Omakotitalojen myyntihinnat todennäköisesti nousevat seuraavalla kvartaalilla potentiaalisten ostajien määrän kasvaessa.
- Lisättyyn todellisuuteen liittyvien laitteiden maailmanlaajuinen liikevaihto ylittänee 100 miljardin euron rajan vuonna 2020.
Regressioalgoritmien toiminta perustuu historiallisen datan, ns. aikasarjadatan analysointiin. Yleinen tekniikka regressioalgoritmien toteuttamiseen on neuroverkot.
6.3.1.2 Ohjaamaton oppiminen
Ohjaamattomalla oppimisella tarkoitetaan tekniikoita, joilla ei ole erityistä, ennalta annettua kysymystä tai asettelua, vaan jotka pyrkivät etsimään mielenkiintoisia malleja datasta. Algoritmeille annetaan ainoastaan syöte.
Klusterointi- tai ryhmittelyalgoritmit pyrkivät jakamaan dataa ryhmiin datan ominaisuuksien mukaan:
- Asiakkaat X, Y ja Z syövät paljon leipää, koska he ovat ostaneet viimeisen vuoden aikana ainakin kolme leivänpaahdinta.
- Virukset voidaan jakaa ryhmiin A, B, C ja D niiden sisältämän perintöinformaation määrän mukaisesti.
- Dokumentit J, K ja L käsittelevät kissoja, koska sana kissa mainitaan niissä useasti.
Ryhmittelyalgoritmien tuloksia visualisoidaan usein 2- tai 3-ulotteisilla neliöillä tai kuutioilla, jossa akselit kuvaavat joukkojen kannalta relevanttien attribuuttien arvoja. Yksinkertaista ryhmittelyä on esimerkiksi TF-IDF-metodi (term frequency-inverse document frequency), jolla voidaan selvittää miten relevantti jokin sana on dokumentissa, kun datana on joukko dokumentteja:
")
Jossa:
 on sanan
on sanan  lukumäärä dokumentissa
lukumäärä dokumentissa  ,
, on dokumentissa esiintyvän yleisimmän sanan
on dokumentissa esiintyvän yleisimmän sanan  lukumäärä,
lukumäärä, on dokumenttien lukumäärä ja
on dokumenttien lukumäärä ja on dokumenttien lukumäärä, jossa sana esiintyy ainakin kerran.
on dokumenttien lukumäärä, jossa sana esiintyy ainakin kerran.
Assosiaatioalgoritmit pyrkivät etsimään eri muuttujien välisiä korrelaatioita datassa:
- Käyttäjät X ja Y tuntevat toisensa, koska he lähettävät paljon sähköpostia toisilleen.
- Lääkkeistä A ja B aiheutui eniten sivuvaikutuksia H, K ja L ikäryhmille P ja Q.
- Asiakkaat, jotka ostavat tuotetta X ostavat todennäköisesti myös tuotetta Y.
- Asiakaskertomuksia lukeneet asiakkaat eivät tavallisesti tee sähkösopimusta.
- Tilauksen tekeminen peruutetaan yleensä maksutavan valinta -vaiheessa.
Termi tiedonlouhinta alkoi yleistyä jo 1990-luvulla. Tekniikoiden kehittyessä ja laajentuessa kattamaan lisää erilaisia algoritmeja, lanseerattiin termi koneoppiminen (machine learning). Käsitteiden raja on häilyvä, ja tämän kurssin puitteissa ne voi käsittää synonyymeiksi. Syväoppimisella (deep learning) tarkoitetaan yksinkertaistaen erilaisten tiedonlouhintatekniikoiden yhdistämistä sellaiseksi kokonaisuudeksi, joka jäljittelee monimutkaisuudellaan ihmisen päätöksentekoa. Käytännössä tämä tarkoittaa, että koneen ns. päättelyketjua tietystä syötteestä tiettyyn tulosteeseen on haastava jäljittää.
6.3.2 Tiedonhallinta ja siihen liittyvä kehitys
Tietovarastointi on perinteisesti perustunut rakenteisen datan tallentamiseen niin, että lähdedatasta suodatetaan ainoastaan haluttu data, joka sen jälkeen muunnetaan sopivaksi tietovarastoon. Tarvittaessa dataa voidaan palauttaa lähdejärjestelmiin. Uusien tekniikoiden ja kohdealueiden (esim. sosiaalinen media ja erilaiset IoT-laitteet) yleistymisen myötä nouseva trendi ovat olleet ns. data lake -ratkaisut. Data lake eroaa tietovarastosta rakenteettomuudellaan: sinne kerätään tavallisesti kaikki data lähdejärjestelmistä, eikä dataa pakoteta ennalta määrättyyn rakenteeseen, kuten relaatiotietokannan tauluihin.
Data lake -ratkaisuja kuvataan tavallisesti matalaksi ja laajaksi järveksi, jossa on paljon dataa monesta eri lähdejärjestelmästä. Kun data halutaan raportoida, analysoida tai louhia, sille luodaan tehtävään soveltuva rakenne. Siinä missä tietovarastojen tekninen toteutus perustuu usein perinteisiin ja kypsiin (usein myös kaupallisiin) relaatiotietokannanhallintajärjestelmiin, data lake -ratkaisuihin käytetään kypsyysasteeltaan tuoreempia tekniikoita, joista suosituin lienee Apache Hadoop -viitekehys.
Data lake -ratkaisun potentiaalisena ongelmana nähdään datan räjähdysmäinen kasvu, ja rakenteettoman datan sekoittuminen toisiinsa ilman tehokasta metadatan hallintaa. Gartner käyttää epäonnistuneesta data lake -toteutuksesta kuvaavaa nimeä data swamp, jolla viitataan tärkeän tiedon uppoamiseen tarpeettomaan dataan. Tietovarastointi- ja data lake -tekniikoiden parhaiden puolien yhdistämiseen perustuvaa ratkaisua kutsutaan nimellä data vault. Data vault on tavallisesti ratkaisu, jossa käytetään sekä rakenteista relaatiotietokantaa että rakenteetonta data lake -ratkaisua rinnakkain.
Muun muassa data lake -ratkaisuihin liittyy käsite big data. Se on yleisnimitys suurelle määrälle tietynlaista dataa, sekä tällaisen datan hallintaan liittyville tekniikoille ja haasteille. Big data määritellään datan määrän (volume) lisäksi kolmella ominaispiirteellä:
- Monimuotoisuudella (variety) tarkoitetaan, että data ei ole rakenteellista, esim. relaatiotietokannan näkökulmasta data ei sijaitse ennalta määritellyissä tauluissa ja niiden nimetyissä, tietotyypiltään määrätyissä sarakkeissa.
- Todenmukaisuudella (veracity) tarkoitetaan, että data tunnustetaan mahdollisesti osittain virheelliseksi, jolla voidaan tarkoittaa esim. vanhentunutta, ristiriitaista tai puutteellista dataa.
- Nopeudella (velocity) tarkoitetaan, että datavirta on jatkuvaa ja dataa virtaa tietokantaan runsaasti.
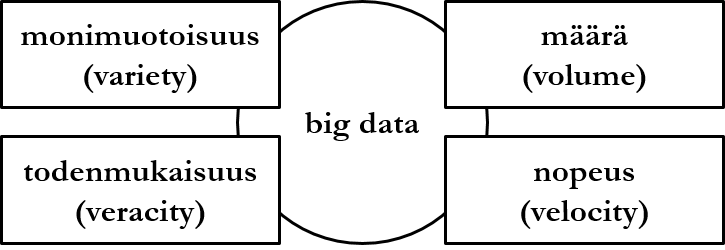
7. Hajautus
Tässä luvussa käsitellään tietokantajärjestelmän palvelin- ja laitteistoarkkitehtuurin kautta tietokantajärjestelmien hajautusta. Hajautuksella (distribution) tarkoitetaan tässä luvussa yleisellä tasolla tietokantajärjestelmän jakamista usealle laitteelle. Tietokantajärjestelmän hajautus voidaan yleisellä tasolla jakaa kahteen osaan: laskentatehon ja datan hajautukseen. Hajautus on yleistä ja suuressa määrin yleistyvää.
Tämä luku jakautuu kolmeen osaan: ensimmäinen alaluku käsittelee palvelinarkkitehtuurin yleistä mallia, ns. kolmitasoarkkitehtuuria. Toinen alaluku käsittelee laitteistoarkkitehtuuria, joka koskee tietokantajärjestelmässä erityisesti kolmitasoarkkitehtuurin tietokannasta vastaavaa osaa. Viimeinen alaluku käsittelee erityisesti dataa koskevia hajautusmenetelmiä.
7.1 Kolmitasoarkkitehtuuri
Nykyään on tavallista, että tietokantajärjestelmä on palvelinarkkitehtuuriltaan ainakin kolmitasoinen (three tier). Asiakastason käyttöliittymä mahdollistaa tietokantajärjestelmän käytön asiakkaille (ns. front-end). Logiikkatason sovelluspalvelin sisältää tietokantajärjestelmän sovelluslogiikan. Datatason tietokantapalvelin sisältää tietokannanhallintajärjestelmän ja tietokannan (ns. back-end).
Kolmitasoarkkitehtuurin nk. edeltäjä on tiedostopalvelin. Sen mukaisessa palvelinarkkitehtuurissa tietokanta tai sen osa sijaitsee asiakaslaitteella, ja asiakaslaitteen vastuulla on myös liiketoimintalogiikka (eli mm. laskenta). Kolmitasoarkkitehtuurin etuja tiedostopalvelimeen ovat Quinlanin (1995) mukaan mm.:
- Asiakaslaitteilta ei vaadita suurta määrää muistia tai laskentatehoa, koska arkkitehtuurin muut tasot vastaavat laskennasta.
- Datan yhdenmukaisuuden varmistaminen on vaivattomampaa, koska data on yhdessä paikassa.
- Tietoturva vahvistuu, koska asiakaslaitteet eivät käsittele dataa suoraan, vaan sovelluslogiikkakerroksen kautta.
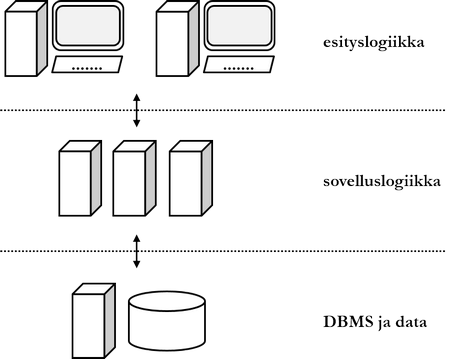
On syytä mainita, että kolmitasoisella (tai n-tasoisella) arkkitehtuurilla voidaan tarkoittaa myös sovellusarkkitehtuuria. Niiden mukaisesti sovellusohjelma jaetaan loogisesti kolmeen tasoon (layer). Näiden tasojen vastuut vastaavat yleisesti yllä kuvatun palvelinarkkitehtuurin tasojen vastuita: yksi taso on vastuussa käyttöliittymästä, toinen laskennasta ja kolmas datasta.
7.2 Rinnakkaisarkkitehtuurit
Rinnakkaisarkkitehtuureilla tarkoitetaan tässä alaluvussa laitteistoarkkitehtuureja, jotka pyrkivät ratkaisemaan tietokantajärjestelmien ongelmia erityisesti käyttämällä useita prosessoreita tai useita laitteita tai molempia. Lähtökohtia rinnakkaisarkkitehtuureille on kaksi: jaettu levy sekä täysin erillinen. Tämä alaluku perustuu lähteeseen Hellerstein, Stonebraker & Hamilton (2007, s. 165-175).
7.2.1 Jaettu levy -arkkitehtuuri
Jaettu levy -rinnakkaisarkkitehtuurin (shared disk) mukaan usea laite pitää yllä tietokantainstansseja (ts. kokoelmaa prosesseja ja varattua muistia) samasta tietokannasta, ts. massamuisti jaetaan laitteiden kesken. Tätä suhdetta, jossa usea tietokantainstanssi voi yhdistää samanaikaisesti yhteen tietokantaan, kutsutaan klusteroinniksi tai ryvästämiseksi (clustering). Ryvästämisen tarkoituksena on tarjota asiakasohjelmalle sama toiminnallisuus kuin keskitetynkin järjestelmän, mutta paremmalla suorituskyvyllä ja vikasietoisuudella.
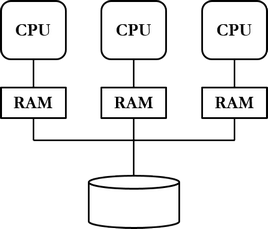
Tämän rinnakkaisarkkitehtuurin vahvuutena nopeuden lisäksi on vikasietoisuus: vaikka jokin tietokantainstansseja ylläpitävistä laitteista menetetään, voidaan asiakkaita silti palvella. Ideaalitapauksessa asiakaslaite ei ole tietoinen, vaikka tietokantainstanssia ylläpitävä laite menetetään kesken tietokantajärjestelmän käytön, vaan toinen solmu ottaa huolekseen asiakkaan palvelemisen.
Jaettu levy -rinnakkaisarkkitehtuurin uhkana voidaan pitää vikatilannetta tietokantaa ylläpitävässä laitteessa. Tätä potentiaalista ongelmaa voidaan kuitenkin lieventää toisintamalla tietokanta usealle laitteelle. Toisintamista käsitellään tarkemmin myöhemmin alaluvussa 7.3. Tämän rinnakkaisarkkitehtuurin heikkoutena voidaan pitää myös tietokantajärjestelmän infrastruktuurin suunnittelun ja toteutuksen haastavuutta.
7.2.2 Täysin erillinen -arkkitehtuuri
Täysin erillinen -arkkitehtuurin (shared nothing) mukaan tietokanta on looginen kokonaisuus, joka on jaettu fyysisesti eri laitteille. Jokainen järjestelmän tietokantainstanssi pitää yllä osaa tietokannasta.
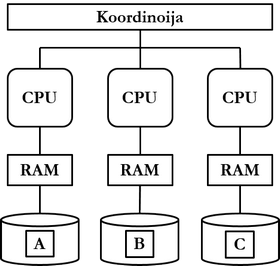
Asiakasohjelmalle tietokannanhallintajärjestelmä näyttää ja toimii samoin kuin keskitetty järjestelmäkin, ja kaikki liikenne tapahtuu tavallisesti koordinoijan kautta. Koordinoija huolehtii siitä, että asiakasohjelmalta saapuvat pyynnöt välitetään oikealle solmulle tietokantajärjestelmässä. Jos koordinoijia on useita, arkkitehtuurin mukaisessa järjestelmässä minkä tahansa solmun menettäminen ei saata järjestelmää toimimattomaan tilaan. Arkkitehtuurilla saavutetaan teoriassa lineaarinen skaalautuvuus.
7.2.3 Jaettu muisti -arkkitehtuuri
Jaettu muisti -rinnakkaisarkkitehtuurin (shared memory tai shared everything) mukaisesti joukko prosessoreita tai ytimiä jakaa saman keskusmuistin. Jaettu muisti ei ole nykyään enää varsinainen rinnakkaisarkkitehtuuri, vaan rinnakkaisarkkitehtuurin laajennos, joka on käytössä muiden rinnakkaisarkkitehtuurien ohessa, sillä kaikki nykyaikaiset prosessorit ovat moniytimisiä.
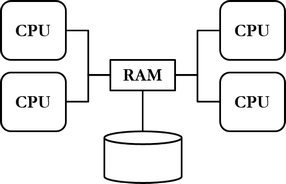
7.3 Toisintaminen ja sirpalointi
Jos tietokanta sijaitsee usealla laitteella (ts. solmulla), tietokantaa kutsutaan hajautetuksi (distributed). Hajautus jaetaan tässä alaluvussa kahteen luokkaan: toisintamiseen (data on kopioitu usealle laitteelle) ja sirpalointiin (data on jaettu usealle laitteelle).
Hajautuksella pyritään mm. skaalautuvuuteen eli laajennettavuuteen, jonka tarkoituksena on järjestelmän suorituskyvyn tehostaminen. Tietokantajärjestelmien skaalautuvuus voi olla n-tasoisen arkkitehtuurin sovelluslogiikkakerroksen skaalautuvuutta tai tietokannan eli datan skaalautuvuutta. Edelleen skaalautuvuus voi olla vertikaalista (scaling up), joka pyrkii yhden solmun suorituskyvyn lisäämiseen tai horisontaalista (scaling out), joka pyrkii lisäämään järjestelmän suorituskykyä lisäämällä järjestelmään solmuja.
7.3.1 Toisintaminen
Toisintamisella (replication) tarkoitetaan datan kopioimista usealle solmulle: tietokanta nähdään loogisena kokonaisuutena ABC, joka kopioidaan kokonaisuudessaan usealle solmulle. Toisintamisen tarkoituksena on vikasietoisuuden tai suorituskyvyn parantaminen tai molemmat.

Toisintamisen toteutukselle on kaksi erilaista kokoonpanoa: isäntä-orja- (master-slave tai primary-secondary) ja vertaiskokoonpano (peer-to-peer). Isäntä-orja -kokoonpanossa asiakassovellukset tekevät tavallisesti kirjoitusoperaatiot isäntäsolmuun ja lukuoperaatiot orjasolmuihin alla olevan kuvion mukaisesti. Vertaiskokoonpanossa asiakassovellukset tekevät luku- (read, R) ja kirjoitusoperaatioita (write, W) mihin solmuun tahansa.
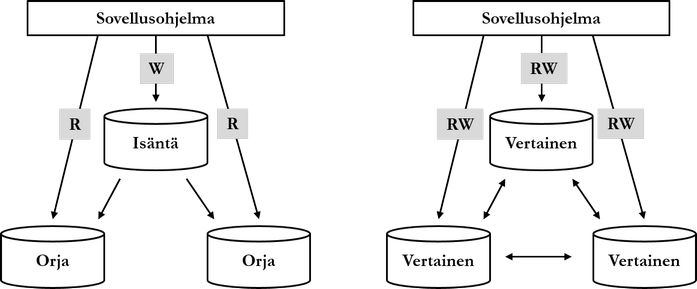
Isäntä-orja -kokoonpano voidaan toteuttaa myös niin, että kaikki kirjoitus- ja lukuoperaatiot tehdään vain isäntäsolmuun, ja data toisinnetaan orjasolmuihin ainoastaan vikasietoisuuden takaamiseksi. Näin data on kaikille asiakkaille yhdenmukainen, mutta operaatiot potentiaalisesti hitaampia. Yllä olevassa kuviossa (vasen) orjasolmut toisintavat datan isäntäsolmulta. On myös tuotteesta riippuen asetuksia muuttamalla mahdollista, että orjasolmut toisintavat dataa toisiltaan.
Koska vertaiskokoonpanossa kaikkiin solmuihin voidaan tehdä kirjoitusoperaatioita, kirjoitusoperaatioista johtuvat poikkeamat ovat mahdollisia. Toisaalta taas vertaiskokoonpano ei kuormita ainoastaan yhtä solmua kirjoitusoperaatioilla, vaan kuorma on tasattu solmujen kesken.
Toisintaminen voi edelleen olla synkronista tai asynkronista. Synkronisessa toisintamisessa kirjoitusoperaation vastaanottava solmu odottaa, että kaikki tai määrätty osa muista solmuista on toisintanut datan itselleen ennen kuittauksen lähettämistä sovellusohjelmalle. Asynkronisessa toisintamisessa kuittaus lähetetään heti, kun kirjoitusoperaation vastaanottanut solmu on tallentanut datan.
7.3.2 Sirpalointi
Sirpaloinnin (sharding) mukaisesti tietokanta on looginen kokonaisuus ABC, joka jaetaan loogisesti ja fyysisesti usealle eri solmulle. Jokaisessa solmussa on oma skeemansa, ns. skeemainstanssi. Sirpalointi on yleistä erityisesti NoSQL-tietokannoissa. Relaatiotietokannoissa käytetään myös ns. partitiointia (partitioning), jonka mukaisesti tietokanta jaetaan loogisiin osiin yhden skeeman sisäisesti. Käytännössä tämä tarkoittaa relaatioiden jakamista useisiin eri tauluihin vaakasuuntaisesti eli monikoittain.

Sirpalointia käytetään tyypillisesti toisintamisen rinnalla. Tästä syystä isäntä-orja-kokoonpanolla toisinnetussa tietokantajärjestelmässä on mahdollista olla useita isäntäsolmuja, joista jokainen huolehtii tietystä osasta dataa, ts. yhdestä sirpaleesta (shard). Sirpaloinnin tarkoituksena on suorituskyvyn parantaminen, ja toisaalta myös vikasietoisuuden parantaminen, jos ollaan valmiita palvelemaan asiakkaita puutteellisella datalla.
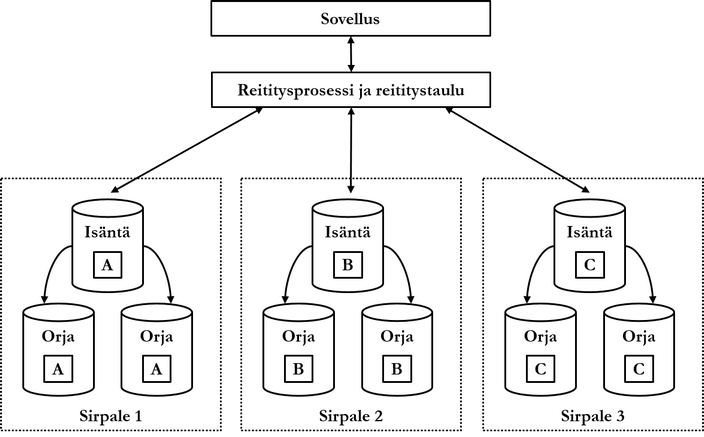
Yllä olevassa kuviossa tietokanta on hajautettu yhdeksään solmuun, jotka sijaitsevat kolmessa sirpaleessa. Data on toisinnettuna kolmeen solmuun. Sovellusohjelma kommunikoi tietokannan kanssa reititysprosessin välityksellä, eikä sovellusohjelman tarvitse tietää, että tietokanta on hajautettu.
Tietokannan sirpalointi tehdään sirpaleavaimen (shard key) avulla. Sirpaleavain on tietomallista riippuen jokin tietue, jonka arvojen perusteella sirpalointi suoritetaan. Useimmat NoSQL-tuotteet tukevat ns. autosharding-ominaisuutta. Sen avulla tietokannanhallintajärjestelmä huolehtii automaattisesti datan tasaamisesta solmujen kesken, kun sirpaleavain on valittu. Datan tasaaminen solmujen kesken suoritetaan jakamalla kunkin solmun data kimpaleisiin (chunk) ja siirtämällä kimpaleita solmujen välillä niin, että jokaisessa solmussa on suunnilleen sama määrä dataa.
Tarkastellaan lopuksi matalan tason esimerkkiä yllä olevaa kuviota hyödyntäen. Oletetaan, että tietokannasssa on tietoa asiakkaista. Tietokannan sirpaleavaimeksi on valittu asiakkaan syntymäaika. Sirpaleessa 1 ovat tallennettuina asiakkaat, joiden syntymäaika on välillä minimi-3.4.1970, sirpaleessa 2 asiakkaat, joiden syntymäaika on välillä 4.4.1970-1.2.1989 ja sirpaleessa 3 asiakkaat, joiden syntymäaika on välillä 2.2.1989-maksimi. Sovellusohjelma lisää tietokantaan uuden asiakkaan, jonka syntymäaika on 10.1.1989:
- Reititysprosessi tarkastaa pyynnön saatuaan reititystaulusta, mihin sirpaleeseen uusi asiakas kuuluu. Reititystaulun mukaan asiakas kuuluu sirpaleeseen 2.
- Reititysprosessi välittää uuden asiakkaan sirpaleen 2 isäntäsolmulle.
- Sirpaleen 2 isäntäsolmu havaitsee, että kimpale numero 109 pitää sisällään asiakkaat, joiden syntymäaika on välillä 5.1.1989-1.2.1989 ja ryhmittää uuden asiakkaan tähän kimpaleeseen.
- Tietokannanhallintajärjestelmän autosharding-prosessi havaitsee, että sirpaleessa 3 on kynnyksen ylittävä määrä vähemmän dataa kuin muissa sirpaleissa.
- Kimpale 109 siirretään sirpaleen 3 isäntäsolmuun, jotta datan määrä tasaantuu sirpaleiden välillä.
- Tieto sirpaleiden uusista arvojoukoista tallennetaan reititystauluun.
- Kimpale 109 toisinnetaan sirpaleen 3 orjasolmuihin.
8. Tietokantaparadigmat
Tässä luvussa esitellään tietomalleja, joita käytetään tietokannoissa, ts. tietokantaparadigmoja. Tähän mennessä kurssimateriaali on keskittynyt relaationaaliseen tietokantaparadigmaan, ja tässä luvussa esitellään yleisellä tasolla kuusi muuta tietokantaparadigmaa: oliosuuntautunut, oliorelaationaalinen, avain-arvopari, dokumentti, graafi ja sarakeperhe.
8.1 Oliosuuntautunut
Oliotietokanta (object database) on oliosuuntautunutta ohjelmointiparadigmaa noudattava tietokanta. Oliotietokantaa käyttävästä tietokannanhallintajärjestä käytetään nimitystä oliotietokannanhallintajärjestelmä (Object-Oriented Database Management System, OODBMS).
8.1.1 Keskeiset käsitteet
Oliotietokannoilla ei ole yleistä tai formaalia mallia tai standardia, kuten relaatiotietokantojen relaatiomalli. Toisaalta relaatiomalli tarjoaa perustan vain osalle RDBMS:n toiminnoista ja oliotietokantojen taustalla vaikuttavat oliosuuntautuneen ohjelmoinnin vakiintuneet käsitteet. Oliotietokantoja on yrittänyt standardisoida Object Data Management Group, Object Management Group ja Object Database Technology Working Group, mutta standardit ovat jääneet keskeneräisiksi tai niitä ei ole otettu laaja-alaisesti käyttöön.
Oliosuuntautunut ohjelmointi on ohjelmointiparadigma, jonka mukaan sovellus jaetaan olioihin. Oliot omistavat dataa ja käyttäytymisen, joiden avulla olio toimii ja kommunikoi järjestelmän muiden olioiden kesken. Seuraavaksi on lyhyesti selitetty oliosuuntautuneisuuteen liittyvät peruskäsitteet oliotietokantojen näkökulmasta. Peruskäsitteiden ymmärtäminen auttaa ymmärtämään oliotietokannan tietomallin. Määritelmät perustuvat Bertinon & Martinon (1993, s. 12-34) esitykseen. Jos oliokeskeiset käsitteet ovat tuttuja, voit siirtyä seuraavaan alalukuun 8.1.2.
Olio (object) on reaalimaailman asiaa tai käsitettä kuvaava osa järjestelmää. Jokaisella oliolla on yksilöivä tunniste (Object Identifier, OID), joka määrää olion identiteetin. Olioilla on dataa eli attribuutteja arvoineen. Attribuutin arvo voi olla yksinkertainen, kuten kokonaisluku tai arvo voi olla toinen olio tai olioiden joukko. Attribuuttien arvot kuvastavat olion tilaa (state).
Kapselointi (encapsulation) tarkoittaa, että oliolla on sekä metodit että rajapinta joilla oliota voidaan tarkastella ja muokata. Metodit koostuvat nimestä (signature) ja toteutuksesta (implementation): metodin nimeä kutsumalla metodin toteutus suoritetaan. Olion rajapinta on joukko metodeja, joita kutsumalla olio voi toimia. Olion metodit kuvastavat olion käytöstä (behaviour).
Näkyvyysalue (scope) määrää attribuutti- ja metodikohtaisesti, mikä olio voi lukea ja muuttaa attribuutin arvoja tai kutsua metodia.
Luokka (class) on olioiden joukko. Kaikki oliot, joilla on samat attribuutit ja metodit, kuuluvat samaan luokkaan. Kaikki oliot kuuluvat johonkin luokkaan. Olio, joka kuuluu luokkaan X sanotaan olevan luokan X instanssi.
Perintä (inheritance) tarkoittaa, että luokka voi olla yhden tai useamman muun luokan instanssi ja periä näiden luokkien attribuutit ja metodit. Näin määriteltyä luokkaa kutsutaan aliluokaksi (subclass) ja luokkia, jotka aliluokan määrittävät kutsutaan yliluokiksi (superclass).
Ylikuormituksella (overloading) tarkoitetaan, että saman nimisellä metodilla voi olla useita toteutuksia. Näin järjestelmä voi päättää, mitä metodin toteutusta käytetään minkäkin operaation suorittamiseksi.
Olioiden pysyvyydellä (persistence) tarkoitetaan sitä, millaisella politiikalla oliot tallennetaan ja poistetaan oliotietokantaan. Yleistäen voidaan sanoa, että oliokeskeisessä tietojärjestelmässä oliot ovat olemassa muistissa. Usein olioita on kuitenkin tarve tallentaa tietokantaan massamuistiin, jotta ne säilyvät ja jotta muistia vapautuu muiden olioiden käyttöön. Muistissa sijaitsevaa oliota kutsutaan lyhytkestoiseksi (volatile) ja levyllä sijaitsevaa oliota pysyväksi (persistent). Pysyvyyden ratkaisemiseen on lähtökohtaisesti kolme tapaa (Bertino & Martino, 1993, s. 25-26):
- Ensimmäisen lähestymistavan mukaan järjestelmän kaikki oliot ovat implisiittisesti pysyviä. Tällöin kun uusi olio luodaan, se tallennetaan tietokantaan.
- Toisen lähestymistavan mukaan pysyvyys on eksplisiittinen piirre. Tällöin olion luonnin yhteydessä sitä ei tallenneta tietokantaan ja sen elinkaaren päätteeksi olio tuhotaan pysyvästi, ellei oliota ole erityisesti muutettu pysyväksi. Tämän lähestymistavan vahvuutena voidaan pitää joustavuutta ja heikkoutena monimutkaisuutta.
- Kolmannen lähestymistavan mukaan pysyvyys on jotakin kahden edellisen väliltä. Esimerkiksi osa järjestelmän luokista takaa niihin kuuluvien olioiden pysyvyyden, kun taas toisten pysyvyys on määrättävä oliokohtaisesti.
Olion attribuutin arvo voi olla viite toiseen olioon tai toisiin olioihin. Olioiden poistamiseen liittyy viitteiden käsittely, jolle on kaksi tapaa. Ensimmäisen tavan mukaan olioiden poistaminen sallitaan vain, jos mikään toinen olio ei viittaa poistettavaan olioon. Toisen tavan mukaan olioiden poistaminen sallitaan vapaasti, ja viittaukset poistettuihin olioihin aiheuttavat poikkeuksen. Tämän tavan mukaan olioiden poistoon ei ole erillistä operaatiota, ja pysyvä olio poistetaan vain, jos kaikki ulkoiset nimet ja viittaukset, johon pysyvä olio viittaa, poistetaan.
8.1.2 Olio-relaatioyhteensopimattomuus
Tietokantajärjestelmässä, jossa tietokannanhallintajärjestelmä on relaationaalinen ja sovellusohjelma oliosuuntautunut voidaan pitää etuna sitä, että järjestelmän tietokanta on selvästi erotettavissa sovellusohjelmasta: tietokanta nähdään relaatioina ja sovellusohjelma olioina. Oliotietokannoilla on kuitenkin joitakin ominaisuuksia, jotka relaatiotietokannoilta puuttuvat:
- Monimutkaiset tietorakenteet: relaatiotietokannoissa yksi asiakokonaisuus on tavallisesti jaettuna useaan tauluun, esim. asiakas ja hänen tilaamansa tuotteet ovat yhteensä neljässä taulussa: asiakas, tilaus, tilausrivi ja tuote.
- Tietueisiin voidaan liittää operaatioita.
- Tietueiden käytös ei muutu sovellusohjelman tarpeiden mukaan, vaan käytös on tallennettu tietueeseen.
- Tietueella on identiteetti, joka on erillään tietueen tilasta.
Yllä mainittujen ominaisuuksien puuttumisen lisäksi relaatiotietokannanhallintajärjestelmän ja oliosuuntautuneen sovellusohjelman liittäminen voi johtaa tunnistettujen ongelmien ja epäjohdonmukaisuuksien joukkoon nimeltä olio-relaatioyhteensopimattomuus (object-relational impedance mismatch). Yhteensopimattomuus ei sinänsä tarkoita, että RDBMS ei sovi yhteen oliosuuntautuneen sovellusohjelman kanssa, vaan että niiden yhteenliittäminen voi olla virhealtista ja työlästä. Alla olevaan taulukkoon on koottu potentiaaliset ongelmatilanteet.
| Ongelma | Kuvaus |
|---|---|
| Kapselointi | Olion rajapinnan kautta käsiteltävä data asetetaan tietokannassa näkyviin. |
| Kyselyt | SQL on korkean tason kieli. Ohjelmointikieli on matalatasoisempi. |
| Näkyvyysalueet | Käyttöoikeudet ovat tietokannassa suhteellisia, mutta olioilla absoluuttisia. |
| Perintä | Perintää ei voida helposti mallintaa tietokannassa. |
| Rakenne | Oliot voivat olla rakenteeltaan monimutkaisempia kuin tietokannan rivit. |
| Suhteet | Olioiden välisiä suhteita ei voida välttämättä kuvata viiteavaimilla. |
| Tietotyypit | Tietokannassa on erilaiset tietotyypit ja ne toimivat eri tavalla kuin sovellusohjelmassa. |
Olio- tai NoSQL-tietokannat voivat olla yksi ratkaisu yllä esitettyihin ongelmatilanteisiin. Toinen vaihtoehto on yrittää suunnitella sovellusohjelma relaatiotietokannan ehdoilla. Kolmas vaihtoehto on valita RDBMS:ksi jokin oliosuuntautuneita ominaisuuksia tukeva tuote, ts. oliorelaationaalinen tietokannanhallintajärjestelmä (Object-Relational Database Management System, ORDBMS). Neljäs vaihtoehto ovat ns. ORM-työkalut (Object-Relational Mapper), jotka pyrkivät helpottamaan sovellusohjelman ja RDBMS:n yhteenliittämistä.
8.1.3 Kyselykielet
Oliotietokannoilla ei ole yhteistä standardoitua kyselykieltä kuten SQL, vaan nykyään on tavallista, että kyselyt tehdään isäntäkielellä, ns. natiivikyselyinä. Eräs tunnettu kyselykomponentti on Microsoftin LINQ (Language Integrated Query) .NET-kieliin, jolla voidaan suorittaa erilaisia lausekkeita kokoelmiin. Tällainen kokoelma voi olla esimerkiksi relaatiotietokannan relaatio tai oliotietokannan kokoelma. Alla on esitetty esimerkkejä seuraavan SQL-kyselyn vastineita muilla kielillä.
LINQ:
OODBMS GemStone, jossa on käytetty natiivikyselyä SmallTalk-ohjelmointikielellä:
OODBMS db4o (database for objects), jossa on käytetty natiivikyselyä Javalla:
Oliotietokannanhallintajärjestelmien kyselykielet voivat olla ilmaisuvoimaltaan SQL:ää heikompia, jolloin kielet voivat olla helpommin omaksuttavissa. Kyselyt voidaan tavallisesti myös toteuttaa natiivikyselyinä, jotka vastaavat ilmaisuvoimaltaan isäntäkieltä, mutta voivat olla haastavia toteuttaa. Äärimmäisessä tapauksessa varsinaista kyselykieltä ei ole lainkaan, ja OODBMS tarjoaa vain isäntäkielellä käytettävän ohjelmointirajapinnan (application programming interface, API) tallennettuihin olioihin. Tällaisista oliotietokannoista käytetään nimitystä persistent object store.
Tunnetuimpia oliotietokannanhallintajärjestelmiä ovat mm. db4o, Perst ja ObjectDB.
8.1.4 ORM-työkalut
RDBMS:n ja oliosuuntautuneen järjestelmän yhteenliittämisen ongelmia koskevassa luvussa mainittiin ORM-työkalut (Object-Relational Mapper). ORM-työkalut ovat tavallisesti isäntäkielen lisäkirjastoja. Ne on suunniteltu oliosuuntautuneen järjestelmän muistissa sijaitsevien olioiden liittämiseen levyllä sijaitsevaan relaatiotietokantaan niin, että olio-relaatioyhteensopimattomuuksia ei tapahtuisi. ORM-työkalut liittyvät siis nimensä mukaisesti tietokantajärjestelmiin, joissa on käytössä relaatiotietokanta.
ORM-työkalujen suurin hyöty on sovelluskehityksen, erityisesti alkuvaiheiden vauhdittuminen: suuri osa sovellusohjelman kyselyistä voidaan toteuttaa ilman SQL:ää käyttäen ORM:n metodeja datan noutamiseen, muokkaamiseen ja poistamiseen. Alla on esitetty esimerkkejä seuraavan SQL-kyselyn vastineita erilaisilla ORM-työkaluilla:
Erityisen monipuolinen Javalle tarkoitettu jOOQ:
Tunnetun ActiveRecordin Ruby-kielinen sovellus:
Eritysesti web-kehityksessä suositun Django-viitekehyksen (framework) ORM Python-ohjelmointikielellä:
Suosittu ja monipuolinen ORM-moduuli SQLAlchemy, joka toimii Python-ohjelmointikielessä:
Käytännössä ORM-työkalut generoivat metodiensa perusteella SQL-lauseita, jotka lähetetään RDBMS:lle. ORM-työkalut eivät aina ole ilmaisuvoimaltaan SQL:n tasolla, ja voivat generoida heikosti optimoitua SQL:ää. Sovelluskehityksen alkuvaiheessa ORM-työkalujen käytöllä saavutettu ajallinen hyöty voidaankin myöhemmin menettää optimoinnille, pahimmassa tapauksessa moninkertaisena. Tästä syystä ORM-työkalun käyttö ei poista tarvetta osata SQL:ää, jos tietokantajärjestelmässä on käytössä relaatiotietokanta.
8.2 Oliorelaationaalinen
Oliorelaationaaliset tietokannanhallintajärjestelmät (Object-Relational Database Management System, ORDBMS) ovat tavallisesti relaatiotietokannanhallintajärjestelmiä, joihin on myöhemmin lisätty oliosuuntautunutta ohjelmointia tukevia ominaisuuksia. Ominaisuudet on lisätty myös SQL-standardiin (SQL:1999), ja tietokantatuotteet kuten Greenplum, Oracle, PostgreSQL ja Informix ovat ottaneet niitä käyttöönsä. Tässä alaluvussa käsitellään yleisellä tasolla näistä ominaisuuksista kolme tärkeintä: mukautetut tietotyypit, perintä ja oliokäytös. Tämä alaluku perustuu lähteeseen Melton (2003a, s. 26-57, 68-105).
8.2.1 Mukautetut tietotyypit
Mukautetut tietotyypit (User-Defined Type, UDT) ovat nimensä mukaisesti uusia, itse luotavia tietotyyppejä. Ominaisuus pyrkii lieventämään joitakin olio-relaatio yhteensopimattomuuden ongelmia kuten alaluvussa 8.1.2 esitetyn taulukon tietotyyppeihin ja rakenteeseen liittyviä ongelmia. Mukautetuilla tietotyypeillä RDBMS:n ja sovellusohjelman tietotyypit voidaan:
- sovittaa yhteensopiviksi luomalla RDBMS:ään uusia, isäntäkieltä vastaavia tietotyyppejä sekä
- monimutkaistaa RDBMS:n taulun rivin rakennetta vastaamaan sovellusohjelman olioiden monimutkaisuutta.
SQL-standardi määrittää yleisellä tasolla kahdenlaisia mukautettuja tietotyyppejä: erillisiä (distinct) ja rakenteisia (structured). Erilliset tietotyypit ovat yksinkertaisesti määriteltävissä, ja niiden avulla voidaan vaivattomasti estää esim. yhteensopimattomien attribuuttien vertailu keskenään tai attribuuttien arvon muokkaaminen aritmetiikalla. Erillisen mukautetun tietotyypin voi luoda SQL:llä esim. seuraavalla tavalla:
Kahdelle uudelle tietotyypille on asetettu lähdetietotyypiksi kokonaisluku. Luodun taulun attribuuttien jalka ja äo vertailu (...WHERE jalka = äo;) tai muuttaminen matemaattisilla operaattoreilla (...SET jalka = jalka + 2;) ei onnistu. Jos attribuuteille haluttaisiin tehdä mainittuja operaatioita, ne täytyisi muuntaa ensin tyyppimuunnoksella sellaiseksi tietotyypiksi, jolle operaatiot sallitaan.
Rakenteiset tietotyypit ovat erillisiä tietotyyppejä monimutkaisempia, ja niiden avulla yksi sarake voidaan määrittää kootuksi. Ominaisuuden avulla yksi olio voidaan tehokkaammin rinnastaa yhteen tauluriviin:
Yllä määritetyssä taulussa on kaksi koottua saraketta: katu ja kaupunki. Avainsanat NOT FINAL kuuluvat standardiin ja ovat pakolliset. Jälkimmäisessä esimerkissä on esitelty notaatio rakenteista tietotyyppiä koskevasta kyselystä ja sen syntaksista.
8.2.2 Perintä
Oliosuuntautuneen ohjelmoinnin perinnän vastineeksi SQL-standardi määrittää rakenteisten tietotyyppien perinnän (type inheritance). Perinnän mukaisesti rakenteiset tietotyypit voivat toimia yhden rakenteisen tietotyypin alityyppinä ja muodostaa hierarkioita. Alityyppi perii ylityyppinsä metodit ja sarakkeet.
Yllä on esitetty esimerkki perinnästä. Vuokrattava-ylityypiltä peritään sarakkeet ja metodit tietotyypeille peli ja elokuva, ja edelleen elokuvan sarakkeet ja metodit periytyvät alityypeille vhs ja dvd. SQL-standardin mukaisesti moniperintää (multiple inheritance), jonka mukaan tietotyypillä voi olla useampi kuin yksi välitön (direct) ylityyppi, ei sallita. Alla on esitetty standardin mukaiset esimerkit perinnän toteuttamiseksi:
Yllä olevan esimerkin ensimmäisellä lauseella luodaan ylityyppi vuokrattava. Sille on asetettu lisämääre NOT INSTANTIABLE, joka estää tietotyypin instanssien luonnin, ts. tietotyyppi on abstrakti. Tämä johtuu siitä, että kuvitteellinen vuokraamo ei tallenna tietokantaan vuokrattavia, vaan konkreettisia vuokrattavia tuotteita: pelejä ja elokuvia. Tietotyyppi vuokrattava toimii siis ainoastaan alityyppiensä apuna. Jälkimmäisessä lauseessa on luotu konkreettinen tietotyyppi peli, jonka ylityypiksi on määritetty vuokrattava. Tietotyypin peli instansseilla on siis seitsemän saraketta.
Perintä ulottuu mukautettujen tietotyyppien lisäksi taulujen tasolle. Jatketaan yllä olevaa esimerkkiä luomalla kaksi taulua perustuen mukautettuihin tietotyyppeihin ja käyttämällä taulujen tasoista perintää:
Ensimmäisessä esimerkissä määritetään ns. itseensä viittaava sarake (self-referencing column) avainsanalla REF. Se on ORDBMS:n vastine perusavaimelle, ja sen avulla DBMS erottaa taulun rivit (tallennetut oliot) toisistaan, vaikka ne olisivat muuten identtiset. Itseensä viittaavien sarakkeiden arvot ovat uniikkeja globaalisti, ts. ne eivät ole taulu- vaan tietokantakohtaisia. Yllä olevan esimerkin mukaisessa taulussa huonot on lopulta neljä saraketta: tietotyypin vuokrattava sarakkeet sekä itseensä viittaava sarake id. Taulussa halvat_huonot_pelit on kahdeksan saraketta: perityt ja määritetyt sarakkeet tietotyypeiltä sekä taululta huonot peritty, itseensä viittaava sarake id.
8.2.3 Oliokäytös
Oliokäytöksellä (object behaviour) tarkoitetaan käytännössä metodeita. Metodit ovat SQL-standardin mukaan eräänlaisia funktioita, jotka liittyvät vahvasti johonkin mukautetun tietotyypin instanssiin (ts. tauluriviin). Mukautettu tietotyyppi, johon metodi kuuluu, kutsutaan metodiin liittyväksi tietotyypiksi (associated type).
SQL-standardin mukaan metodi määritetään kahdessa paikassa: metodin nimi, syöteparametrit ja palautusarvon tyyppi määritetään tietotyypin määrityksen yhteydessä ja metodin toiminta erillisellä käskyllä:
Yllä olevassa esimerkissä mukautetulle tietotyypille elokuva on määritetty metodikutsu kesto_luettavana. Metodi ei ota kutsuttaessa eksplisiittisiä syöteparametrejä, ja palauttaa merkkijonon.
Yllä on puolestaan määritetty metodin toiminta. On syytä huomata, että metodin ja siihen liittyvä tietotyyppi on sidottu toisiinsa sekä tietotyypin että metodin määrityksessä. Avainsana SELF viittaa instanssiin itseensä. Metodin toiminta on yksinkertainen: se palauttaa kutsuttaessa instanssinsa keston tunteina ja minuutteina. Lopuksi on esitetty esimerkki metodin kutsumisesta.
8.3 NoSQL
Tässä alaluvussa tarkastellaan neljää eri tietokantaparadigmaa, jotka muodostavat suurimman osan ns. NoSQL-paradigmaperheestä. Jos RDBMS-kentällä relaatiomalli ja SQL-standardi muodostavat perustan eri tuotteille, NoSQL-maailmassa eri tuotteiden voidaan katsoa muodostavan perustan tietokantaparadigmoilleen. Siitä huolimatta samojen tietokantaparadigmojen eri tuotteilla on suuriakin eroja. Tarkastellaan aluksi hieman NoSQL-tietokantojen perustavanlaatuisia eroja relaatiotietokantoihin.
8.3.1 BASE ja CAP
NoSQL-tietokantatuotteille on tyypillistä, että ACID-ominaisuuksista luovutaan tai niitä löyhennetään eri tavoin. Relaatiotietokannoille tyypillisien ACID-ominaisuuksien NoSQL-vastineeksi voidaan mieltää ns. BASE-ominaisuudet (Basically Available, Soft state, Eventually consistent). BASE-ominaisuudet kuvaavat niitä rajoitteita, jotka ovat usein tyypillisiä hajautetuille järjestelmille:
- Basically available tarkoittaa, että kaikkiin pyyntöihin pystytään vastaamaan huolimatta siitä, onko vastaus ajantasainen tai edes oikeellinen.
- Soft state tarkoittaa, että järjestelmän data ei ole välttämättä oikeellinen tietyllä hetkellä, vaikka tuolla hetkellä kirjoitusoperaatioita ei tapahtuisikaan. Tilan muutokset voivat johtua esimerkiksi järjestelmän automaattisesti suorittamasta datan tasauksesta tai toisintamisesta.
- Eventually consistent tarkoittaa, että järjestelmä päätyy lopulta yhdenmukaiseen tilaan, jos siihen ei kohdistu uusia kirjoitusoperaatioita.
NoSQL-tietokantatuotteita kuvataan usein ns. CAP-teoreeman näkökulmasta. CAP-teoreeman (tai Brewerin teoreema) mukaan järjestelmän on mahdollista toteuttaa kolmesta piirteestä korkeintaan kaksi:
- Yhdenmukaisuus (consistency): järjestelmä sisältää yhden ja vain yhden version datasta.
- Saatavuus (availability): kaikki järjestelmän aktiiviset solmut suorittavat operaatioita.
- Osioinnin sietokyky (partition tolerance): järjestelmä sietää osiointia.
Tuotteiden luokittelu CAP-teoreeman mukaan on kuitenkin monesti ongelmallista, sillä tuotteiden asetuksia muuttamalla ne voivat toteuttaa eri CAP-piirteitä. Lisäksi useassa tuotteessa on mahdollista valita tapahtuma- tai operaatiokohtaisesti, miten tärkeää tapahtuman onnistuminen on. Tällöin saman tuotteen eri tapahtumat voivat toteuttaa eri CAP-piirteitä.
NoSQL-tietokannanhallintajärjestelmiä verrataan usein eri näkökulmista relaationaalisiin tietokannanhallintajärjestelmiin. NoSQL-tuotteita on kuvattu mm. seuraavilla yleisnimillä eron tekemiseksi relaationaalisiin tuotteisiin: BASE-oriented, non-relational, NoJoin, schemaless, aggregate oriented, NoACID ja cluster oriented.
BASE-oriented ja NoACID viittaavat ACID-ominaisuuksien löyhentämiseen tai tapahtumanhallinnan tarkasteluun eri näkökulmasta. NoJoin ja aggregate oriented viittaavat NoSQL-tietokantojen loogisiin rakenteisiin, joissa usein tarvittu data koostetaan yhteen vastoin normalisointisääntöjä. Muun muassa tästä johtuen kaikki NoSQL-tuotteet eivät mahdollista lainkaan liitosten tekemistä kyselyissä.
Schemaless viittaa skeemattomaan loogiseen rakenteeseen. Siinä missä relaatiotietokannan taulujen rakenne on määrätty etukäteen ja sarakkeet vahvasti tyypitetty, NoSQL-tietokannassa tauluriveihin rinnastettavat tietueet saattavat poiketa rakenteeltaan huomattavasti toisistaan. Cluster oriented viittaa NoSQL-tuotteiden hajautusta suosivaan luonteeseen.
8.3.2 Avain-arvoparitietokannat
Avain-arvoparitietomalli (key-value store) on NoSQL-perheen yksinkertaisin. Sen mukaan tietue koostuu avaimesta ja avaimen arvosta: avain on arvonsa yksilöivä tunniste ja periaate on sama kuin esim. ohjelmoinnistakin tuttu hajautustaulu (hash table) tai loogisen tason tiedostojärjestelmä. Jotkin tuotteet sallivat arvoiksi monimutkaisetkin tietotyypit kuten moniulotteiset listat, hajautustaulut, XML-dokumentit tai binääridata.
Tietokannan loogisen rakenteen määrittävät vahvasti tietokantajärjestelmän tietotarpeet. Esimerkiksi verkkokaupan tietokannan avain-arvoparien arvot voivat koostua asiakkaan kaikista tiedoista sekä hänen tilaamistaan tuotteista. Näin kaikki asiakkaaseen liittyvä data voidaan noutaa yksinkertaisella kyselyllä, eikä liitoksia tarvitse muodostaa. Joissakin tuotteissa liitoksia ei ylipäätään voi muodostaa. Tietomallia on kuvattu alla yleisen rakenteen (vasemmalla) sekä esimerkin (oikealla) avulla.
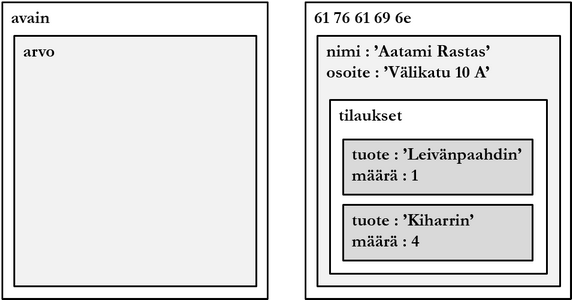
Yleistäen voidaan sanoa, että avain-arvoparitietokannan etuna on mm. yksinkertaisesta tietomallista johtuva suorituskyky, heikkoutena puolestaan samasta syystä johtuvat rajoittuneet kyselykielet. Avain-arvoparitietokannat muistuttavat tietomalliltaan dokumenttitietokantoja, mutta perustavanlaatuisena erona pidetään tavallisesti sitä, että dokumenttitietokannanhallintajärjestelmä ymmärtää datan rakennetta siinä merkityksessä, että DBMS:n kyselykieli pystyy käsittelemään dokumentin osia.
Tunnettuja avain-arvoparitietokantatuotteita ovat esimerkiksi Redis, Riak ja Memcached. Monet tuotteet on mahdollista asettaa toimimaan ainoastaan muistissa (ns. in-memory database), jolloin saavutetaan entistä parempi suorituskyky, mutta laitevirheet voivat olla datalle kohtalokkaita. Muistissa toimivat avain-arvotietokannat tukevat erityisesti vertikaalista skaalautuvuutta.
8.3.3 Sarakeperhetietokannat
Sarakeperhetietokantojen (column-family) termit on usein määritelty vahvasti tuotekohtaisesti, ja monet termit ovat samoja relaatiotietokantojen kanssa vaikka tarkoittavatkin eri asiaa. Sarakeperhetietokannassa data on matalimmalla loogisella tasolla tallennettu avain-arvopareiksi, joista käytetään nimitystä sarake ja sarakkeen arvo. Toisiinsa liittyvät sarakkeet arvoineen sijaitsevat samalla rivillä, jolla on yksilöivä tunnus (row id). Toisiaan muistuttavat rivit on ryhmitelty samaan sarakeperheeseen. Toisin kuin relaatiotietokannan taulussa, sarakeperheen riveillä ei tarvitse olla samaa määrää tai samoja sarakkeita.
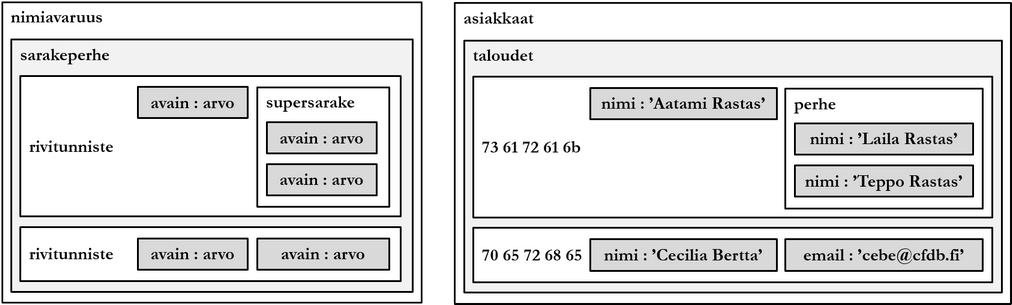
Ylimmällä loogisella tasolla sarakeperhetietokannassa on nimiavaruus (keyspace), joka sisältää yhden tai useamman sarakeperheen. Nimiavaruus vastaa löyhästi relaatiotietokannan skeemaa tai tietokantaa. Joissakin sarakeperhetietokantatuotteissa on lisäksi ns. supersarakkeita (super column). Supersarakkeet voivat sisältää muita sarakkeita mahdollistaen näin korkeintaan nelitasoisen hierarkian: nimiavaruus, sarakeperhe, supersarake ja sarake.
Tunnettuja sarakeperhetietokantatuotteita ovat esimerkiksi Cassandra, HBase ja Hypertable. Kaikki näistä tietokannanhallintajärjestelmistä mahdollistavat datan eri versioiden ylläpitämisen. Lopuksi on syytä mainita, että tuotteiden nimeämiskäytännöissä on tietomallin osalta suuriakin eroja.
8.3.4 Dokumenttitietokannat
Dokumenttitietokannat (document-oriented database) tallentavat dokumentteja. Dokumentit tallennetaan tavallisesti hieman avain-arvoparitietokannan tapaisesti: dokumentti koostuu dokumentin tunnisteesta ja sisällöstä. Dokumentin sisältö voi olla rakenteeltaan hyvinkin monimutkainen hierarkia, ja dokumenttitietomallia voidaankin pitää NoSQL-perheen joustavimpana. Dokumenttitietokannanhallintajärjestelmä pystyy tavallisesti ymmärtämään dokumentin rakennetta, ja tekemään siihen tarkempia kyselyitä kuin esimerkiksi avain-arvoparitietokannanhallintajärjestelmä avaimen arvoon. Lisäksi eri tuotteissa on lisärakenteita esim. samankaltaisten dokumenttien ryhmittelyyn.

Dokumentit tallennetaan tavallisesti XML- (Extensible Markup Language), JSON- (JavaScript Object Notation) tai BSON-muodossa (Binary JSON), joista kaksi jälkimmäistä ovat nousevassa suosiossa, ja niiden kyselykieli on tavallisesti JavaScript-pohjainen. XML-dokumenttitietokannoissa tietokantaoperaatiot tehdään tavallisesti XQuery-kyselykielellä. Alla on esitetty esimerkkidokumentti XML-muodossa.
<asiakas id="a800">
<nimi>
<etunimi>Matti</etunimi>
<sukunimi>Meikäläinen</sukunimi>
</nimi>
<osoite>
<katu>Kuja 2</katu>
<postinro>40100</postinro>
<kaupunki>Jyväskylä</kaupunki>
</osoite>
<tilaukset>
<tilaus id="t101">
<tuotenimi>Paahdin</tuotenimi>
<maara>1</maara>
</tilaus>
<tilaus id="t102">
<tuotenimi>PC</tuotenimi>
<maara>1</maara>
</tilaus>
</tilaukset>
</asiakas>Vastaava dokumentti JSON-muodossa:
Tunnettuja dokumenttitietokantatuotteita ovat esimerkiksi MongoDB ja CouchDB, joista molemmat hyödyntävät JSON-formaattia. Monessa suositussa RDBMS:ssä (esim. SQL Server, Oracle ja PostgreSQL) on puolestaan XML:ää tukevaa toiminnallisuutta. Lisäksi PostgreSQL sisältää monipuoliset työkalut JSON-dokumenttien tallentamiseen tai taulurivien palauttamiseen JSON-muodossa.
8.3.5 Graafitietokannat
Graafitietokannat (graph database) on tarkoitettu spesifisiin kohdealueisiin, joissa on tarpeen mallintaa erityisesti datan välisiä suhteita. Tietomalli perustuu verkkoteoriaan: se koostuu solmuista (node), suunnatuista kaarista (edge) ja ominaisuuksista. Ominaisuudet voivat kuulua joko kaariin tai solmuihin, ja ominaisuus koostuu avaimesta ja avaimen arvosta. Huomaa, että verkkoteorian solmu ei tarkoita samaa asiaa kuin esim. hajautusta koskevassa luvussa esitetty solmu. Graafitietomallin solmut kuvastavat tavallisesti reaalimaailman kohteita (kuten relaatiotietokannan kohderelaatiot) ja suunnatut kaaret solmujen välisiä suhteita (kuten relaatiotietokannan suhderelaatiot). Kaarten ominaisuudet kuvaavat suhteiden laatua tai piirteitä.
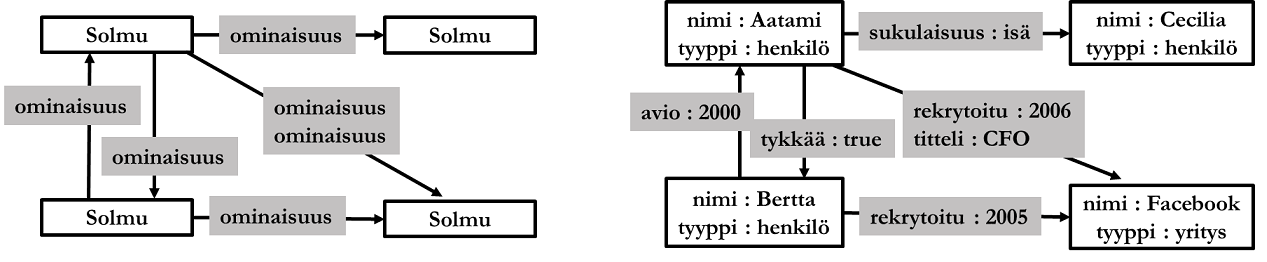
Graafitietokantojen perustavanlaatuinen ominaisuus on kyky suorittaa kohteiden suhteisiin perustuvat kyselyt nopeasti. Relaatiotietokannassa taulujen liitokset ovat yleisesti hitaita, koska DBMS joutuu liittämään relaatiot kyselyn aikana, mahdollisesti suhderelaatioita käyttäen. Graafitietokannassa puolestaan kaaret muodostavat sekä tietokannan rakenteen että datan, ts. datan rakenne on data itse. Kaaret myös muodostavat datan fyysisen rakenteen, ja kaari viittaa fyysisellä tasolla siihen liittyviin solmuihin.
Tunnettuja graafitietokantatuotteita ovat esimerkiksi Neo4J, OrientDB ja Infinite Graph. Tunnistettuja kohdealueita ovat esimerkiksi sosiaalisen median palvelut, bioinformatiikka, verkkosivujen indeksointi ja ydintiedonhallinta.
8.4 Lopuksi
Vuonna 2017 näyttää, että NoSQL-tuotteet ovat tulleet jäädäkseen korvaamatta kuitenkaan relaationaalisia tuotteita. Yleistyvä tapa näyttää olevan ns. monikielisyys (polyglot persistence), jolla tarkoitetaan tietokantajärjestelmän käyttävän useita eri tietomalleja. Näkemyksen mukaan kutakin tietomallia käytetään sellaisessa osassa tietokantajärjestelmää, johon se parhaiten soveltuu. Esimerkiksi verkkohuutokauppa voisi jakautua tietomalleiltaan seuraavalla tavalla:
| Osa-alue | Kriittistä osa-alueessa | Tietomalli |
|---|---|---|
| Huudot | Nopeus | Avain-arvopari |
| Maksutapahtumat | Datan oikeellisuus | Relaationaalinen |
| Tuotesuositukset | Nopeat liitokset | Graafi |
| Käyttäjien suhteet | Nopeat liitokset | Graafi |
| Raportointi | Monipuoliset raportointiominaisuudet | Relaationaalinen |
| Analysointi | Suurten datamäärien reaaliaikainen analysointi | Sarakeperhe |
Alla olevaan taulukko on yleistetty NoSQL-tuotteiden ja relaationaalisten tuotteiden vahvuuksia ja heikkouksia eri näkökulmista. On syytä huomata, että piirteet ovat tyypillisiä, eivät joustamattomia. Esimerkiksi RDBMS:n tapahtumanhallinta voidaan muuttaa asetuksin heikoksi tai tapahtumanhallinnan heikkous voi olla jopa tapahtumakohtaista.
| Relaationaaliset | NoSQL | |
|---|---|---|
| Paikallisvaste | Suuri | Pieni |
| Kyselykielet | Monipuoliset | Yksinkertaiset |
| Tapahtumanhallinta | Vahva | Heikko |
| Hajautus | Työlästä | Vaivatonta |
| Käyttökohteet | Yleiskäyttöisiä | Spesifiset kohdealueet |
| Raportointi | Monipuolista | Rajoittunutta |
| Tuotteiden kypsyys | Kypsiä | Tuoreita |
| Yhteisön tuki | Monipuolinen | Vaihteleva |
| Maksullisuus | Maksuttomia ja kaupallisia | Tavallisesti maksuttomia |
| Datan toisteisuus | Pyritään minimoimaan | Toistoa siedetään, jopa suositaan |
Viitatut
Armstrong, W.W. (1974). Decompositions and Functional Dependencies in Relations. ACM Transactions on Database Systems, 5(4), s. 404-430.
Bertino, E. & Martino, L. (1993). Object-Oriented Database Systems - Concepts and Architectures. Addison-Wesley.
Bramer, M. (2013). Principles of Data Mining. Springer.
Chang, F. ... Gruber, R.E. (2006) Bigtable: A Distributed Storage System for Structured Data. Google Inc.
Chen, P. (1976). The Entity-Relationship Model - Toward a Unified View of Data. ACM Transactions on Database Systems 1(1), s. 9–36.
Codd, E.F. (1970). A Relational Model of Data for Large Shared Data Banks. Communications of the ACM 13(6), s. 377–387.
Codd, E. F. (1972a). Further Normalization of the Data Base Relational Model. Data Base Systems: Courant Computer Science Symposia Series 6, Prentice-Hall.
Codd, E. F. (1972b). Relational Completeness of Data Base Sublanguages. Data Base Systems: Courant Computer Science Symposia Series 6, Prentice-Hall.
Connolly T. & Begg C. (2005). Database systems - practical approach to design, implementation and management Addison-Wesley.
Constine, J. (2012). How big is Facebook's data? Noudettu 28.1.2016 osoitteesta http://techcrunch.com/2012/08/22/how-big-is-facebooks-data-2-5-billion-pieces-of-content-and-500-terabytes-ingested-every-day/
Darwen, H. (2010). An Introduction to Relational Database Theory. Ventus.
Darwen, H., Date, C.J. & Fagin, R. (2012). A Normal Form Preventing Redundant Tuples in Relational Databases. ICDT '12 Proceedings of the 15th International Conference on Database Theory, s. 114-126.
Date, C.J. (2009). SQL and Relational Theory. O'Reilly.
Elmasri, R. & Navathe, S.B. (2007). Fundamentals of Database Systems. Addison-Wesley.
Fagin, R. (1981). A Normal Form for Relational Databases that is Based on Domains and Keys. ACM Transactions on Database Systems, 6(3), s. 387-415.
Garcia-Molina, H., Ullman, J.D. & Widom, J. (2002). Database Systems: the Complete Book. Prentice Hall.
Hellerstein J.M., Stonebraker, M. & Hamilton, J. (2007). Architecture of a Database System. Foundations and Trends in Databases 1(2), s. 141-259.
Hoffer, J.A., Prescott, M.B. & McFadden, F.R. (2002). Modern Database Management. Prentice-Hall.
Inmon, W.H. (1992). Building the Data Warehouse. Wiley and Sons.
Kimball, R. (1996). The Data Warehouse Toolkit. Wiley.
Krikorian, R. (2013). New tweets per second record, and how! Noudettu 28.1.2016 osoitteesta https://blog.twitter.com/2013/new-tweets-per-second-record-and-how
Martin, E. (2013). Top posts of 2013, stats, and snoo year's resolutions. Noudettu 28.1.2016 osoitteesta http://www.redditblog.com/2013/12/top-posts-of-2013-stats-and-snoo-years.html
Matos, V.M. & Grasser, R. (2002). A simpler (and better) SQL approach to relational division. Journal of Information Systems Education, 13(2), s. 85-87.
Melton, J. (2003a). Advanced SQL:1999. Morgan Kaufmann.
Melton, J. (2003b). SQL:1999. Morgan Kaufmann.
Mosley et al. (toim.) (2010). The DAMA Guide to the Data Management Body of Knowledge. Dama International.
Leskovec, J., Rajaraman, A. & Ullman, J.D. (2014). Mining of Massive Datasets. Stanford University.
Quinlan, T. (1995). The Second Generation of Client/Server. Database Programming & Design, 8(5), s. 31-39.
Reddit (2015). About reddit. Noudettu 28.1.2016 osoitteesta http://www.reddit.com/about
Zaniolo. C. (1982). A New Normal Form for the Design of Relational Database Schemata. ACM Transactions on Database Systems, 7(3), s. 489-499.
Venkatesh, P. & Nirmala, S. (2012). NewSQL — The New Way to Handle Big Data. Noudettu 28.1.2016 osoitteesta http://opensourceforu.com/2012/01/newsql-handle-big-data/
Vincent, M.W. (1998). Redundancy Elimination and a New Normal Form for Relational Database Design. Artikkeli kirjassa Semantics in Databases, s. 247-264. Springer Verlag.
Watson, R.T. (2006). Data Management: Databases and Organizations. Wiley.
These are the current permissions for this document; please modify if needed. You can always modify these permissions from the manage page.