English version of the materials are work in progress!
Expect bugs, typos, and other issues. The English version is expected to be completed during spring 2026.
Database Paradigms
This chapter introduces data models used in databases, i.e., database paradigms. So far, the material has focused on the relational database paradigm, and this chapter introduces generally six other database paradigms: object-oriented, object-relational, key-value, document, graph, and column-family.
Object-Oriented
An object database (object database) is a database following the object-oriented programming paradigm. A database management system utilizing an object database is called an object-oriented database management system (Object-Oriented Database Management System, OODBMS).
Key Concepts
Object databases do not have a general or formal model or standard, like the relational model of relational databases. On the other hand, the relational model provides a basis for only part of RDBMS functions, and established concepts of object-oriented programming influence the background of object databases. Object Data Management Group, Object Management Group, and Object Database Technology Working Group have tried to standardize object databases, but standards have remained incomplete or have not been widely adopted.
Object-oriented programming is a programming paradigm according to which an application is divided into objects. Objects own data and behavior, by means of which the object operates and communicates with other objects in the system. Next, basic concepts related to object-orientation are briefly explained from the perspective of object databases. Understanding basic concepts helps to understand the data model of an object database. Definitions are based on the presentation of Bertino and Martino [2]. If object-centric concepts are familiar, you can move to the next subchapter.
Object (object) is a part of the system describing a real-world thing or concept. Each object has a unique identifier (Object Identifier, OID), which determines the object's identity. Objects have data, i.e., attributes with their values. An attribute's value can be simple, such as an integer, or the value can be another object or a set of objects. Attribute values reflect the object's state (state).
Encapsulation (encapsulation) means that an object has both methods and an interface through which the object can be viewed and modified. Methods consist of a name (signature) and implementation (implementation): by calling the method name, the method implementation is executed. An object's interface is a set of methods by calling which the object can operate. An object's methods reflect the object's behavior (behaviour).
Scope (scope) determines per attribute and method, which object can read and change attribute values or call a method.
Class (class) is a set of objects. All objects that have the same attributes and methods belong to the same class. All objects belong to some class. An object belonging to class X is said to be an instance of class X.
Inheritance (inheritance) means that a class can be an instance of one or more other classes and inherit attributes and methods of these classes. A class defined this way is called a subclass (subclass) and classes that define the subclass are called superclasses (superclass).
Overloading (overloading) means that a method with the same name can have multiple implementations. This way the system can decide which method implementation is used to perform which operation.
Persistence (persistence) of objects means with what kind of policy objects are stored in and removed from the object database. Generalizing, it can be said that in an object-centric information system, objects exist in memory. However, there is often a need to store objects in mass storage database so that they persist and memory is freed for other objects' use. An object located in memory is called short-lived (volatile) and an object located on disk persistent (persistent). There are basically three ways to solve persistence:
- According to the first approach, all system objects are implicitly persistent. In this case, when a new object is created, it is stored in the database.
- According to the second approach, persistence is an explicit feature. In this case, on object creation it is not stored in the database and at the end of its life cycle the object is destroyed permanently, unless the object has been specifically made persistent. The strength of this approach can be considered flexibility and weakness complexity.
- According to the third approach, persistence is something between the two previous ones. For example, some system classes guarantee persistence of objects belonging to them, whereas persistence of others must be determined per object.
An object attribute value can be a reference to another object or other objects. Deletion of objects involves handling references, for which there are two ways. According to the first way, object deletion is allowed only if no other object refers to the object being deleted. According to the second way, object deletion is allowed freely, and references to deleted objects cause an exception. According to this way, there is no separate operation for object deletion, and a persistent object is deleted only if all external names and references to which the persistent object refers are deleted.
Object-Relational Impedance Mismatch
In a database system where the database management system is relational and the application program is object-oriented, an advantage can be considered that the system's database is clearly distinguishable from the application program: the database is seen as relations and the application program as objects. However, object databases have some features that relational databases lack:
- Complex data structures: in relational databases, one entity is usually divided into multiple tables, e.g., a customer and products ordered by them are in total in four tables: customer, order, order row, and product.
- Operations can be associated with records.
- Behavior of records does not change according to application program needs, but behavior is stored in the record.
- A record has an identity that is separate from the record's state.
In addition to the lack of features mentioned above, connecting a relational database management system and an object-oriented application program can lead to a set of identified problems and inconsistencies called object-relational impedance mismatch (object-relational impedance mismatch). Mismatch does not directly mean that RDBMS does not fit together with an object-oriented application program, but that connecting them can be error-prone and laborious. Potential problem situations are summarized in the table below.
| Problem | Description |
|---|---|
| Encapsulation | Data handled via object interface is exposed in database. |
| Queries | SQL is a high-level language. Programming language is lower-level. |
| Scopes | Access rights are relative in database, but absolute for objects. |
| Inheritance | Inheritance cannot be easily modeled in database. |
| Structure | Objects can be structurally more complex than database rows. |
| Relationships | Relationships between objects cannot necessarily be described with foreign keys. |
| Data types | Database has different data types and they work differently than in application program. |
Object or NoSQL databases can be one solution to the problem situations presented above. Another alternative is to try to design the application program on relational database terms. A third alternative is to choose as RDBMS a product supporting object-oriented features, i.e., an object-relational database management system (Object-Relational Database Management System, ORDBMS). A fourth alternative are so-called ORM tools (Object-Relational Mapper), which aim to facilitate connecting the application program and RDBMS.
Query Languages
Object databases do not have a common standardized query language like SQL, but nowadays it is common that queries are made in the host language, as so-called native queries. A known query component is Microsoft's LINQ (Language Integrated Query) for .NET languages, with which different expressions can be executed on collections. Such a collection can be for example a relational database relation or an object database collection. Below are presented examples of equivalents of the following SQL query in other languages.
LINQ (C# 9):
OODBMS GemStone, using native query in SmallTalk programming language:
OODBMS db4o (database for objects), using native query in Java:
Query languages of object-oriented database management systems can be weaker in expressive power than SQL, in which case languages can be easier to adopt. Queries can usually also be implemented as native queries, which correspond in expressive power to the host language, but can be challenging to implement. In an extreme case, actual query language does not exist at all, and OODBMS offers only an application programming interface (application programming interface, API) to stored objects used in the host language. Such object databases are called persistent object store.
Most known object-oriented database management systems include e.g. db4o, Perst, and ObjectDB.
ORM Tools
In the chapter concerning problems of connecting RDBMS and object-oriented system, ORM tools (Object-Relational Mapper) were mentioned. ORM tools are usually additional libraries for the host language. They are designed to connect objects located in the object-oriented system memory to a relational database located on disk so, that object-relational impedance mismatches would not occur. ORM tools relate thus according to their name to database systems where a relational database is used.
The greatest benefit of ORM tools is acceleration of application development, especially initial phases: a large part of application program queries can be implemented without SQL using ORM methods to retrieve, modify, and delete data. Below are presented examples of equivalents of the following SQL query with different ORM tools:
Especially versatile jOOQ intended for Java:
Ruby language application of known ActiveRecord:
ORM of Django framework (framework), especially popular in web development, in Python programming language:
Popular and versatile ORM module SQLAlchemy, which works in Python programming language:
In practice, ORM tools generate SQL statements based on their methods, which are sent to RDBMS. ORM tools are not always on the level of SQL in expressive power, and can generate poorly optimized SQL. The time benefit achieved with use of ORM tools in the initial phase of application development can be lost later to optimization, in the worst case manifold. For this reason, use of an ORM tool does not remove the need to know SQL, if a relational database is used in the database system.
Object-Relational
Object-relational database management systems (Object-Relational Database Management System, ORDBMS) are usually relational database management systems to which features supporting object-oriented programming have been added later. Features have also been added to SQL standard, and database products like Greenplum, Oracle, PostgreSQL, and Informix have adopted them. This subchapter discusses generally three most important of these features: user-defined types, inheritance, and object behavior. This subchapter is based on source [27].
User-Defined Types
User-defined types (User-Defined Type, UDT) are as their name implies new, self-creatable data types. The feature aims to alleviate some problems of object-relational impedance mismatch such as problems related to table data types and structure. With user-defined data types, RDBMS and application program data types can be:
- made compatible by creating new data types corresponding to the host language in RDBMS and
- complicate the structure of RDBMS table row to correspond to complexity of application program objects.
SQL standard defines generally two kinds of user-defined data types: distinct (distinct) and structured (structured). Distinct data types are simply definable, and with their help e.g. comparison of incompatible attributes or modification of attribute value with arithmetic can be effortlessly prevented. A distinct user-defined data type can be created with SQL e.g. in the following way:
Integer has been set as source data type for two new data types. Comparison of attributes jalka (shoe size) and äo (IQ) of the created table (...WHERE jalka = äo;) or changing with mathematical operators (...SET jalka = jalka + 2;) does not succeed. If one wanted to perform mentioned operations on attributes, they would have to be converted first with type cast to a data type for which operations are allowed.
Structured data types are more complex than distinct data types, and with them one column can be defined as composite. With the feature, one object can be more efficiently equated to one table row:
In the table defined above, there are two composite columns: katu (street) and kaupunki (city). Keywords NOT FINAL belong to the standard and are mandatory. In the latter example, notation regarding query on structured data type and its syntax is presented.
Inheritance
As counterpart to inheritance of object-oriented programming, SQL standard defines inheritance of structured data types (type inheritance). According to inheritance, structured data types can act as a subtype of one structured data type and form hierarchies. Subtype inherits methods and columns of its supertype.
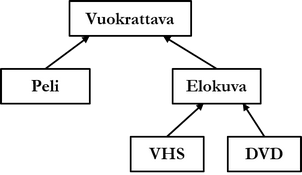
Above is presented an example of inheritance. From Vuokrattava (Rentable) supertype, columns and methods are inherited for data types peli (game) and elokuva (movie), and further elokuva columns and methods are inherited for subtypes vhs and dvd. According to SQL standard, multiple inheritance (multiple inheritance), according to which a data type can have more than one direct (direct) supertype, is not allowed. Below are presented standard examples for implementing inheritance:
With the first statement of the example above, supertype vuokrattava is created. Additional attribute NOT INSTANTIABLE has been set for it, which prevents creation of data type instances, i.e., data type is abstract. This is because a hypothetical rental shop does not store rentables in the database, but concrete rentable products: games and movies. Data type vuokrattava thus acts only as aid for its subtypes. In the latter statement, concrete data type peli has been created, for which vuokrattava has been defined as supertype. Instances of data type peli thus have seven columns.
Inheritance extends in addition to user-defined data types to table level. Let's continue the example above by creating two tables based on user-defined data types and using table-level inheritance:
In the first example, a so-called self-referencing column (self-referencing column) is defined with keyword REF. It is ORDBMS counterpart for primary key, and with it DBMS separates table rows (stored objects) from each other, even if they were otherwise identical. Values of self-referencing columns are globally unique, i.e. they are not table- but database-specific. In the table huonot according to the example above, there are finally four columns: columns of data type vuokrattava and self-referencing column id. Table halvat_huonot_pelit has eight columns: inherited and defined columns from data types plus self-referencing column id inherited from table huonot.
Object Behavior
Object behavior (object behaviour) refers in practice to methods. Methods are according to SQL standard a kind of functions that are strongly reduced to an instance of a user-defined data type (i.e. table row). User-defined data type to which the method belongs is called the method's associated type (associated type).
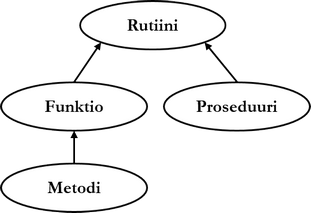
According to SQL standard, a method is defined in two places: method name, input parameters, and return value type are defined in connection with data type definition and method operation with a separate command:
In the example above, method call kesto_luettavana (duration readable) has been defined for user-defined data type elokuva_info (movie_info). The method does not take explicit input parameters when called, and returns a string.
Above, the operation of the method has been defined. It is worth noting that method and associated data type are bound to each other in definitions of both data type and method. Keyword SELF refers to the instance itself. Method operation is simple: it returns its instance's duration in hours and minutes when called. Finally, an example of calling the method is presented.
NoSQL
This subchapter examines four different database paradigms, which form the majority of the so-called NoSQL paradigm family. If in the RDBMS field the relational model and SQL standard form a basis for different products, in the NoSQL world different products can be seen as forming a basis for their database paradigms. Nevertheless, different products of the same database paradigms have even large differences. Let's look initially slightly at fundamental differences of NoSQL databases to relational databases.
BASE and CAP
It is typical for NoSQL database products that ACID properties are abandoned or relaxed in different ways. So-called BASE properties (Basically Available, Soft state, Eventually consistent) can be considered the NoSQL counterpart of ACID properties typical for relational databases. BASE properties describe those constraints that are often typical for distributed systems:
- Basically available means that all requests can be answered regardless of whether the answer is up-to-date or even correct.
- Soft state means that system data is not necessarily correct at a certain moment, even if no write operations happened at that moment. State changes can be due to for example automatic data balancing or replication performed by the system.
- Eventually consistent means that the system ends up finally in a consistent state if no new write operations are directed to it.
NoSQL database products are often described from the perspective of the so-called CAP theorem. According to the CAP theorem (or Brewer's theorem), it is possible for a system to implement at most two of three traits:
- Consistency (consistency): the system contains one and only one version of data.
- Availability (availability): all active nodes of the system perform operations.
- Partition tolerance (partition tolerance): the system tolerates partitioning.
Classification of products according to the CAP theorem is however often problematic, because by changing product settings they can implement different CAP traits. Additionally in many products it is possible to choose per transaction or operation how important transaction success is. In this case different transactions of the same product can implement different CAP traits.
NoSQL database management systems are often compared from different perspectives to relational database management systems. NoSQL products have been described e.g. with following general names to make a distinction from relational products: BASE-oriented, non-relational, NoJoin, schemaless, aggregate oriented, NoACID, and cluster oriented.
BASE-oriented and NoACID refer to relaxation of ACID properties or viewing transaction management from a different perspective. NoJoin and aggregate oriented refer to logical structures of NoSQL databases, where often needed data is aggregated together against normalization rules. Among other things due to this, strictly speaking not all NoSQL products enable making joins in queries at all.
Schemaless refers to schematicless logical structure. Whereas the structure of relational database tables is determined in advance and columns strongly typed, in a NoSQL database records comparable to table rows may differ considerably in structure from each other. Cluster oriented refers to the nature of NoSQL products favoring distribution.
Key-Value Databases
Key-value data model (key-value store) is the simplest of the NoSQL family. According to it, a record consists of a key and a key's value: the key is a unique identifier of its value and the principle is the same as e.g. hash table (hash table) familiar from programming or logical level file system. Some products allow even complex data types as values such as multidimensional lists, hash tables, XML documents, or binary data.
The logical structure of the database determines strongly the information needs of the database system. For example, key-value pair values of an online store database can consist of all customer's information and products ordered by them. This way all data related to the client can be retrieved with a simple query, and joins do not need to be formed. In some products joins cannot be formed at all. The data model is described below with the help of general structure (left) and example (right).
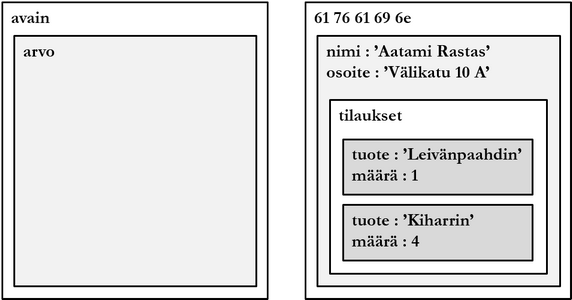
Generalizing, it can be said that the advantage of a key-value database is e.g. performance due to the simple data model, weakness on the other hand restricted query languages due to the same reason. Key-value databases resemble document databases in data model, but a fundamental difference is usually considered that a document database management system understands data structure in the sense that DBMS query language is able to handle document parts.
Known key-value database products are for example Redis, Riak, and Memcached. Many products can be set to operate only in memory (so-called in-memory database), in which case even better performance is achieved, but hardware failures can be fatal for data. In-memory key-value databases support especially vertical scalability.
Column-Family Databases
Column-family database (column-family) terms are often defined strongly product-specifically, and many terms are same as with relational databases even though they mean different thing. In a column-family database, data is stored at lowest logical level as key-value pairs, which are called column and column value. Related columns with values are located on the same row, which has a unique identifier (row id). Rows resembling each other are grouped into the same column family. Unlike in a relational database table, column family rows do not need to have the same amount or same columns.
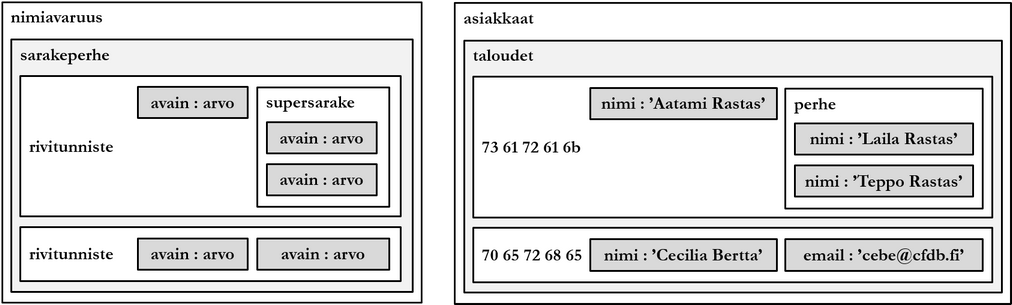
At the highest logical level, a column-family database has a keyspace (keyspace), which contains one or more column families. Keyspace corresponds loosely to relational database schema or database. Some column-family database products additionally have so-called super columns (super column). Super columns can contain other columns enabling thus at most four-level hierarchy: keyspace, column family, super column, and column.
Known column-family database products are for example Cassandra, HBase, and Hypertable. All of these database management systems enable maintaining different versions of data. Finally, it is worth mentioning that there are even large differences in product naming conventions regarding data model.
Document Databases
Document databases (document-oriented database) store documents. Documents are usually stored a bit like in a key-value database: a document consists of a document identifier and content. Document content can be by structure even a very complex hierarchy, and the document data model can be considered the most flexible of the NoSQL family. A document database management system is usually able to understand document structure, and make more precise queries to it than for example a key-value database management system to key value. Additionally, different products have additional structures e.g. for grouping similar documents.

Documents are usually stored in XML (Extensible Markup Language), JSON (JavaScript Object Notation), or BSON format (Binary JSON), of which the latter two are in rising popularity, and their query language is usually JavaScript-based. In XML document databases database operations are usually done with XQuery query language. Below is presented an example document in XML format.
<asiakas id="a800">
<nimi>
<etunimi>Matti</etunimi>
<sukunimi>Meikäläinen</sukunimi>
</nimi>
<osoite>
<katu>Kuja 2</katu>
<postinro>40100</postinro>
<kaupunki>Jyväskylä</kaupunki>
</osoite>
<tilaukset>
<tilaus id="t101">
<tuotenimi>Paahdin</tuotenimi>
<maara>1</maara>
</tilaus>
<tilaus id="t102">
<tuotenimi>PC</tuotenimi>
<maara>1</maara>
</tilaus>
</tilaukset>
</asiakas>Corresponding document in JSON format:
Known document database products are for example MongoDB and CouchDB, both of which utilize JSON format. In many popular RDBMSs (e.g. SQL Server, Oracle, and PostgreSQL) there is functionality supporting XML. Additionally, PostgreSQL contains versatile tools for storing JSON documents or returning table rows in JSON format.
Graph Databases
Graph databases (graph database) are intended for specific domains, where it is necessary to model especially relationships between data. The data model is based on graph theory: it consists of nodes (node), directed edges (edge), and properties. Properties can belong to either edges or nodes, and a property consists of a key and a key's value. Note that a graph theory node does not mean the same thing as e.g. node presented in chapter concerning distribution. Graph data model nodes usually reflect real-world objects (like relational database entity relations) and directed edges relationships between nodes (like relational database relationship relations). Edge properties describe quality or features of relationships.
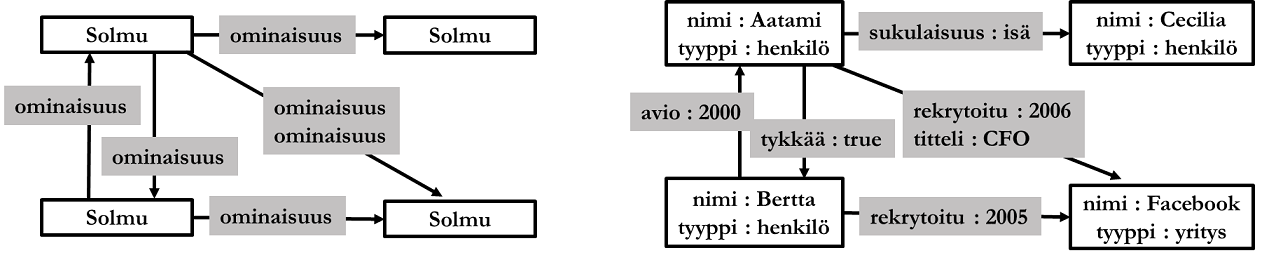
A fundamental feature of graph databases is the ability to perform queries based on object relationships quickly. In a relational database table joins are generally slow, because DBMS has to join relations during query, possibly using relationship relations. In a graph database, edges form both database structure and data, i.e. data structure is the data itself. Edges also form the physical structure of data, and an edge refers at physical level to related nodes.
Known graph database products are for example Neo4J, OrientDB, and Infinite Graph. Identified domains are for example social media services, bioinformatics, web page indexing, and master data management.
Finally
In 2017 it seems that NoSQL products have come to stay without however replacing relational products. A generalizing way seems to be so-called polyglot persistence (polyglot persistence), which means a database system using several different data models. According to the view each data model is used in such part of the database system for which it is best suitable. For example, an online auction could be divided by its data models in the following way:
| Area | Critical in area | Data model |
|---|---|---|
| Bids | Speed | Key-value |
| Payment transactions | Data correctness | Relational |
| Product recommendations | Fast joins | Graph |
| User relationships | Fast joins | Graph |
| Reporting | Versatile reporting features | Relational |
| Analysis | Real-time analysis of large data amounts | Column-family |
Table below generalizes strengths and weaknesses of NoSQL products and relational products from different perspectives. It is worth noting that traits are typical, not inflexible. For example, RDBMS transaction management can be changed with settings to weak or transaction management weakness can be even transaction-specific.
| Relational | NoSQL | |
|---|---|---|
| Locality Response | Large | Small |
| Query Languages | Versatile | Simple |
| Transaction Management | Strong | Weak |
| Distribution | Laborious | Effortless |
| Use Cases | General purpose | Specific domains |
| Reporting | Versatile | Restricted |
| Product Maturity | Mature | Fresh |
| Community Support | Versatile | Variable |
| Cost | Free and commercial | Usually free |
| Data Redundancy | Aimed to be minimized | Redundancy tolerated, even favored |
These are the current permissions for this document; please modify if needed. You can always modify these permissions from the manage page.