English version of the materials are work in progress!
Expect bugs, typos, and other issues. The English version is expected to be completed during spring 2026.
Distribution
This chapter discusses the distribution of database systems through database system server and hardware architecture. By distribution (distribution) is meant in this chapter at a general level dividing the database system across multiple devices. Database system distribution can generally be divided into two parts: distribution of computing power and data. Distribution is common and largely becoming more common.
This chapter is divided into three parts: the first subchapter discusses the general model of server architecture, so-called three-tier architecture. The second subchapter discusses hardware architecture, which concerns in a database system especially the part responsible for the database in three-tier architecture. The last subchapter discusses distribution methods concerning data specifically.
Three-Tier Architecture
Nowadays it is common that the database system server architecture is at least three-tier (three tier). The client tier user interface enables the use of the database system for clients (so-called front-end). Logic tier application server contains the database system's application logic. Data tier database server contains the database management system and the database (so-called back-end).
The so-called predecessor of three-tier architecture is the file server. In its server architecture, the database or part of it is located on the client device, and the client device is also responsible for business logic (including calculation). According to [33], advantages of three-tier architecture over file server include:
- Client devices are not required to have large amount of memory or computing power, because other tiers of the architecture are responsible for calculation.
- Ensuring data consistency is effortless, because data is in one place.
- Information security is strengthened, because client devices do not process data directly, but through the application logic layer.
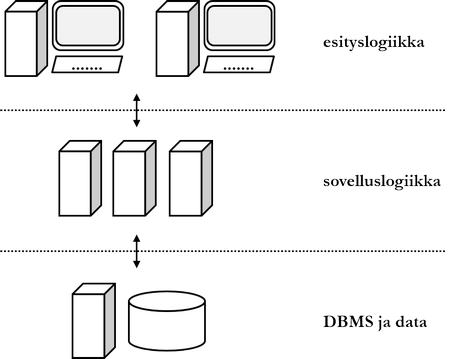
It is worth mentioning that three-tier (or n-tier) architecture can also mean application architecture. According to them, the application program is logically divided into three tiers (layer). The responsibilities of these tiers correspond generally to the responsibilities of the tiers of the server architecture described above: one tier is responsible for the user interface, another for calculation, and the third for data.
Parallel Architectures
By parallel architectures is meant in this subchapter hardware architectures that aim to solve database system problems especially by using multiple processors or multiple devices or both. There are two starting points for parallel architectures: shared disk and fully separate. This subchapter is based on source [18].
Shared Disk Architecture
According to shared disk parallel architecture (shared disk), multiple devices maintain database instances (i.e. a collection of processes and allocated memory) of the same database, i.e. mass storage is shared among devices. This relationship, where multiple database instances can connect simultaneously to one database, is called clustering (clustering). The purpose of clustering is to offer the client program the same functionality as a centralized system, but with better performance and fault tolerance.
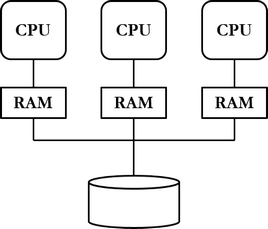
The strength of this parallel architecture in addition to speed is fault tolerance: even if one of the devices maintaining database instances is lost, clients can still be served. In an ideal case, the client device is not aware even if a device maintaining a database instance is lost in the middle of using the database system, but another node takes care of serving the client.
A threat to shared disk parallel architecture can be considered a fault situation in the device maintaining the database. However, this potential problem can be alleviated by replicating the database to multiple devices. A weakness of this parallel architecture can also be considered the challenge of designing and implementing the database system infrastructure.
Shared Nothing Architecture
According to fully separate architecture (shared nothing), the database is a logical entity that is physically divided among different devices. Each system database instance maintains a part of the database.
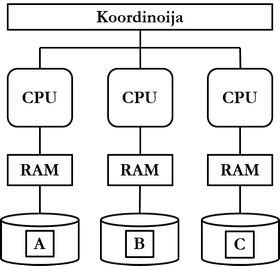
To the client program, the database management system looks and acts the same as a centralized system, and all traffic usually happens through a coordinator. The coordinator ensures that requests arriving from the client program are forwarded to the correct node in the database system. If there are multiple coordinators, losing any node in the system according to the architecture does not put the system in a non-functional state. Linear scalability is theoretically achieved with the architecture.
Shared Memory Architecture
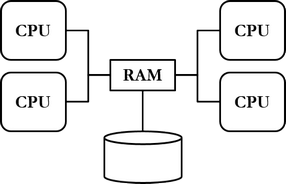
According to shared memory parallel architecture (shared memory or shared everything), a set of processors or cores shares the same main memory. Shared memory is nowadays no longer an actual parallel architecture, but an extension of parallel architecture which is in use alongside other parallel architectures, since all modern processors are multi-core.
Replication and Sharding
If a database resides on multiple devices (i.e. nodes), the database is called distributed (distributed). Distribution is divided in this subchapter into two categories: replication (data is copied to multiple devices) and sharding (data is divided across multiple devices).
Distribution aims at e.g. scalability, i.e. extensibility, whose purpose is enhancing system performance. Database system scalability can be scalability of the application logic layer of n-tier architecture or scalability of the database i.e. data. Furthermore, scalability can be vertical (scaling up), which aims to increase the performance of a single node, or horizontal (scaling out), which aims to increase system performance by adding nodes to the system.
Replication
Replication (replication) means copying data to multiple nodes: the database is seen as a logical entity ABC, which is copied in its entirety to multiple nodes. The purpose of replication is improving fault tolerance or performance or both.

There are two different configurations for implementing replication: master-slave (master-slave or primary-secondary) and peer-to-peer configuration (peer-to-peer). In master-slave configuration, client applications usually make write operations to the master node and read operations from slave nodes as shown in the figure below. In peer-to-peer configuration, client applications make read (read, R) and write operations (write, W) to any node.
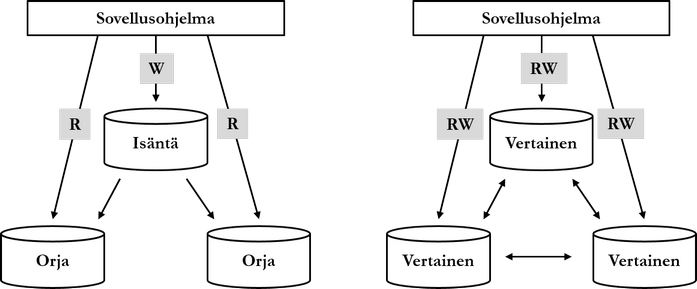
Master-slave configuration can also be implemented so that all write and read operations are done only to the master node, and data is replicated to slave nodes only to guarantee fault tolerance. This way data is consistent for all clients, but operations are potentially slower. In the figure above (left), slave nodes replicate data from the master node. Depending on the product, it is also possible by changing settings that slave nodes replicate data from each other.
Since write operations can be made to all nodes in peer-to-peer configuration, anomalies due to write operations are possible. On the other hand, peer-to-peer configuration does not load only one node with write operations, but the load is balanced among nodes.
Replication can further be synchronous or asynchronous. In synchronous replication, the node receiving the write operation waits until all or a determined part of other nodes has replicated the data to themselves before sending an acknowledgment to the application program. In asynchronous replication, an acknowledgment is sent immediately when the node receiving the write operation has saved the data.
Sharding
According to sharding (sharding), the database is a logical entity ABC, which is logically and physically divided to multiple different nodes. Each node has its own schema, a so-called schema instance. Sharding is common especially in NoSQL databases. In relational databases, so-called partitioning (partitioning) is also used, according to which the database is divided into logical parts within one schema. in practice this means dividing relations into multiple different tables horizontally, i.e. by tuples.

Sharding is typically used alongside replication. For this reason, it is possible for a database system replicated with master-slave configuration to have multiple master nodes, each of which takes care of a certain part of data, i.e. one shard (shard). The purpose of sharding is improving performance, and on the other hand also improving fault tolerance, if one is ready to serve clients with incomplete data.
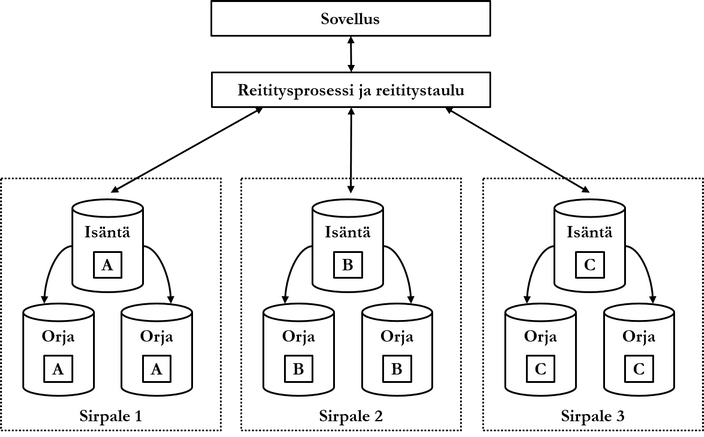
In the figure above, the database is distributed to nine nodes, which are located in three shards. Data is replicated to three nodes. The application program communicates with the database via a routing process, and the application program does not need to know that the database is distributed.
Database sharding is done using a shard key (shard key). A shard key is, depending on the data model, some record based on whose values sharding is performed. Most NoSQL products support so-called autosharding feature. With it, the database management system takes care of balancing data among nodes automatically when a shard key is selected. Balancing data among nodes is performed by dividing each node's data into chunks (chunk) and moving chunks between nodes so that each node has approximately the same amount of data.
Let's look finally at a low-level example utilizing the figure above. Assume that there is information about customers in the database. Customer's birth date has been selected as the database shard key. In shard 1 are stored customers whose birth date is between minimum-3.4.1970, in shard 2 customers whose birth date is between 4.4.1970-1.2.1989 and in shard 3 customers whose birth date is between 2.2.1989-maximum. The application program adds a new customer to the database whose birth date is 10.1.1989:
- After receiving the request, the routing process checks from the routing table which shard the new customer belongs to. According to the routing table, the customer belongs to shard 2.
- The routing process forwards the new customer to shard 2's master node.
- Shard 2's master node detects that chunk number 109 holds customers whose birth date is between 5.1.1989-1.2.1989 and groups the new customer into this chunk.
- The database management system's autosharding process detects that shard 3 has an amount of data less than other shards exceeding the threshold.
- Chunk 109 is moved to shard 3's master node so that the amount of data balances out between shards.
- Information about the shards' new value sets is saved in the routing table.
- Chunk 109 is replicated to shard 3's slave nodes.
These are the current permissions for this document; please modify if needed. You can always modify these permissions from the manage page.