English version of the materials are work in progress!
Expect bugs, typos, and other issues. The English version is expected to be completed during spring 2026.
Normal Forms
In the previous chapter, it was stated that the structure of a normalized relation reduces unnecessary redundancy and helps avoid inconsistencies in data. However, normalization is not a binary concept: a relation is not just either unnormalized or normalized. There are different possible anomalies and redundancies, and sometimes in different cases, it can be accepted that one relation structure is more "optimized" than another.
Normalization of relations is defined and performed in levels. A normal form is a set of requirements related to the relation's structure that a relation can satisfy. The requirements are usually presented via functional dependencies. A relation that satisfies the requirements of a certain normal form gets guarantees according to that normal form regarding anomaly tolerance or existence. There are several normal forms; this chapter introduces the following normal forms in order of their strength:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce/Codd Normal Form (BCNF)
- Fourth Normal Form (4NF)
Higher normal forms offer stronger guarantees about the absence or tolerance of anomalies. The first normal form is the basic form that every database following the relational model must satisfy. Subsequent forms are always defined through the preceding forms: a relation that satisfies 3NF also satisfies 2NF, and a relation that satisfies 2NF also satisfies 1NF.
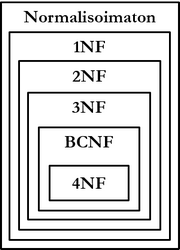
Normalization is always a relation-specific process, and not all relations in a database need to be in the same normal form. Normalization is also usually performed in levels: first, the requirements of 1NF are ensured, then 2NF, etc., until the relation is normalized to the desired level. If a relation does not satisfy the requirements of a normal form, the relation can be corrected, for example, by splitting it into two or more relations. However, splits and changes must be done so that domain data is not lost.
Next, the requirements of the first four normal forms and instructions for bringing a relation into them are presented. It should be mentioned that the requirements given in this material are not formal, but summaries made based on formulations by different authors ([34], [13], [21]).
Before each form, an example table is presented, and the types of anomalies that can arise in the table are considered.
Huomautus
Chapter 5.1 introduced inference rules based on which functional dependencies can be combined. Dependencies that can be inferred using inference rules are trivial. If a dependency cannot be invented using an inference rule, but is based on the table or domain, it is non-trivial.
The requirements presented in this chapter always concern non-trivial dependencies unless otherwise stated.
First Normal Form
Esimerkki
Webbikauppa.com is a company selling various household items and electronics. A website is set up for the company, through which customers can buy products.
The company set the following requirements for the database:
- Customers who want to buy items from the website first create a user account for themselves.
- After that, customers can add items to a shopping cart and buy them.
- The shopping cart is stored in the database so that the user can easily view their shopping cart on different devices (computer, phone) and so that the user could, if they wish, go order the products directly from the brick-and-mortar store.
The coder making the application and database ended up making a table USER which contains user information and their shopping cart. The following model data has been obtained for the table:
| username | shopping_cart |
|---|---|
| matthew123 | 2 pcs product-00000001, 3 pcs product-00000002 |
| hilda02 | 12 pcs product-00000003 |
| asko_96 | 3 pcs product-00000004, 1 pcs product-00000002, 8 pcs product-00000003, 1 pcs product-00000001 |
When creating the table, no primary key was set. Products are described by the product's EAN barcode (format product-12345678), whose information is found elsewhere.
Harjoittele
Look at the table and model data above. Consider what kind of anomalies or possible redundancy can arise. Remember that an anomaly is a contradiction in the table's data resulting from adding, modifying, or deleting data.
What other possible problems can arise when trying to use the table above?
After considering the matter, you can read the explanation below:
The core problem here is the lack of a primary key and the multi-valued nature of the shopping cart values. This can generate all sorts of anomalies:
- Rows with the same username can be added to the table. Since no primary key was selected, for example, 5 rows where
usernameis matthew123 can be added. According to the SQL spec this is allowed, but then user matthew123 would have many shopping carts. - If the shopping cart is emptied by deleting a row, the username disappears completely from the database.
- A product's EAN code might change. Then one would have to go through all users' shopping carts and correct the EAN code, which can be error-prone. One might accidentally leave some product's EAN code unupdated in someone's shopping cart without any warning.
Problems with redundancy:
- In principle, EAN codes and quantities have to be repeated. On the other hand, without it, shopping cart information cannot be presented. However, redundancy can cause the update anomaly mentioned above.
Other problems:
- The data type of the shopping cart is not clear. Specifically, it is not clear which SQL language data type (Chapter 4.3) it would belong to. The shopping cart now has quantities (number), but also EAN codes (string or number).
- It is difficult to examine multiple different shopping carts. If one wanted to know who has ordered product "product-00000003" and the shopping cart was e.g. a string, one would have to search for EAN codes within strings. This again can be error-prone.
- Shopping carts are difficult to maintain. If they are strings, shopping carts "1 pcs product-01, 1 pcs product-01" and "2 pcs product-01" would mean the same thing. This is not redundancy or an anomaly per se, but the same information is described in two different ways, which complicates database maintenance.
The first normal form is thus related to the basic properties of the relational model introduced in Chapter 3.1. Problems like the example can be reached at least in databases according to the SQL specification, as the specification does not require, for example, that a table has a primary key. Additionally, storing multiple values in one column easily leads to problems in database usage.
The first normal form practically demands that the table is designed according to the rules of the relational model.
Määritelmä
A relation is in 1NF if it satisfies the requirements of a relation:
- A suitable primary key must be selected for the relation.
- The order of tuples (i.e., rows) must not have significance for the data.
- Each attribute (i.e., column) must have one clear data type. Mixing different types of data in the same attribute is forbidden.
- Each attribute is atomic, i.e., does not contain multiple values.
If a relation does not satisfy 1NF, the correction steps are:
- Split multi-valued attributes so that each value gets its own row.
- If necessary, add attributes so that each is of a clear data type.
- Select a suitable primary key.
Esimerkki
Now clearly the example above does not satisfy 1NF.
As a correction, the shopping cart should be split into two attributes: cart_product (EAN code) and product_quantity (number). In addtion, every product in the shopping cart is improved to its own row. The result is:
| username | cart_product | product_quantity |
|---|---|---|
| matthew123 | product-00000001 | 2 |
| matthew123 | product-00000002 | 3 |
| hilda02 | product-00000003 | 12 |
| asko_96 | product-00000004 | 3 |
| asko_96 | product-00000002 | 1 |
| asko_96 | product-00000003 | 8 |
| asko_96 | product-00000001 | 1 |
Additionally, {username, cart_product} is selected as the primary key, so that each user can have multiple products in the shopping cart, but a second row cannot accidentally be added for the same product (instead the quantity must be updated). Furthermore if the product ID was made a foreign key to a table containing all products' information, one could not even accidentally add products that do not exist to users. In addition, the RDBMS would then automatically handle possible EAN code changes or product deletions.
Now the table is in 1NF. Note that 1NF does not solve all anomalies: for example, if hilda02's shopping cart is emptied by deleting a row, hilda02 disappears from the entire database.
Second Normal Form
Esimerkki
Let's continue the example above. The Webbikauppa.com company's website has been further developed. The company would like to add different customer types to the website, which would have different bonuses and discounts. The company initially considers three customer types: "Basic Customer", "Bonus Customer", and "VIP Customer".
After pondering for a moment, the coder making the application and database decided to simply extend the USER table based on the requirement by adding a column usertype to it. The result was the following updated table (primary key columns underlined):
| username | cart_product | product_quantity | usertype |
|---|---|---|---|
| matthew123 | product-00000001 | 2 | Basic Customer |
| matthew123 | product-00000002 | 3 | Basic Customer |
| hilda02 | product-00000003 | 12 | VIP Customer |
| asko_96 | product-00000004 | 3 | Bonus Customer |
| asko_96 | product-00000002 | 1 | Bonus Customer |
| asko_96 | product-00000003 | 8 | Bonus Customer |
| asko_96 | product-00000001 | 1 | Bonus Customer |
Harjoittele
Look at the table and model data above. Consider what kind of anomalies or possible redundancy can arise. Remember that an anomaly is a contradiction in the table's data resulting from adding, modifying, or deleting data.
What other possible problems can arise when trying to use the table above?
After considering the matter, you can read the explanation below:
In this case, the table is indeed in 1NF, but there are still high risks for anomalies.
Possible anomalies:
- If hilda02's shopping cart were emptied by deleting her row, there are two dangers: first, hilda02 disappears from the database as a user. If one wanted to know hilda02's customer type, it disappears with the deletion of the shopping cart. Second, if hilda02's row were removed and the database was asked what different customer types exist, the answer would be only two customer types instead of three possible ones.
- If matthew123's customer type updates (e.g. to VIP customer), all rows belonging to matthew123 must be updated. If accidentally some matthew123 row's customer type is not updated, matthew123's customer type becomes contradictory.
- Similarly, if matthew123 adds new products to the shopping cart, new rows are generated. In this case, one might accidentally add a row where matthew123's customer type is different from matthew123's other rows. We end up in a contradiction again.
Problems with redundancy:
- As already mentioned, an individual user's customer type has to be repeated with every product added to the shopping cart.
Other problems:
- If we get a new customer, their customer type cannot be stored before the customer adds some product to the shopping cart.
Functional dependencies are indeed needed for the second normal form. Specifically, 2NF relates to how the determinant set of functional dependencies in the relation and the relation's primary key relate to each other.
Määritelmä
A relation is in 2NF, if it satisfies the following requirements:
- The relation is in 1NF.
- No attribute not belonging to the primary key depends only on a part of the primary key, but on the whole primary key.
In other words, if a functional dependency {X} -> {Y} holds, where X has attributes belonging to the relation's primary key and Y does not belong to the primary key, then attributes belonging to the primary key cannot be removed from X such that the functional dependency would still hold. Such a functional dependency is called a full functional dependency.
Note that in 2NF only those functional dependencies where the determinant set includes all attributes belonging to the primary key need to be checked. Dependencies whose determinant set has attributes not belonging to the primary key do not violate 2NF. As a consequence, if a relation's primary key has only one attribute, the relation is always in 2NF.
Another way to think about 2NF is: the functional dependency between the primary key and attributes not belonging to the primary key must be non-trivial (i.e., it cannot be derived from inference rules). Specifically, the primary key cannot be split into parts so that any dependency between the primary key and other attributes would persist.
If a relation does not satisfy 2NF, it can be corrected by making a separate relation for every functional dependency violating 2NF, containing the attributes that are parties to the functional dependency. The determinant set becomes the primary key of the new relation.
Esimerkki
Let's continue the example above. Let's think through what functional dependencies are found in the table and how they satisfy 2NF:
{username, cart_product} -> {product_quantity}- "If a specific user's ID and product are known, it is known how many pieces the user in question has ordered of said product."
- 2NF is OK: the determinant attribute set is
{username, cart_product}, which is the same as the relation's primary key AND if either attribute were taken away from it, the dependency could no longer hold.
{username} -> {usertype}- "If a specific user's ID is known, this user's user type is known."
- 2NF FAIL: The determinant attribute set is
{username}, which is only part of the relation's primary key and not the whole primary key. In other words, dependency{username, cart_product} -> {usertype}is trivial.
To satisfy 2NF, the relation must be split. Let's make separate relations for the two functional dependencies:
USER_CART(username, cart_product, product_quantity), which corresponds to functional dependency {username, cart_product} -> {product_quantity}:
| username | cart_product | product_quantity |
|---|---|---|
| matthew123 | product-00000001 | 2 |
| matthew123 | product-00000002 | 3 |
| hilda02 | product-00000003 | 12 |
| asko_96 | product-00000004 | 3 |
| asko_96 | product-00000002 | 1 |
| asko_96 | product-00000003 | 8 |
| asko_96 | product-00000001 | 1 |
USER(username, usertype), which corresponds to functional dependency {username} -> {usertype}:
| username | usertype |
|---|---|
| matthew123 | Basic Customer |
| hilda02 | VIP Customer |
| asko_96 | Bonus Customer |
Now we got two tables where unnecessary redundancy has been removed and worries related to anomalies solved:
- Users have their own table, so now a user does not disappear from the database even if they don't have a shopping cart.
- Similarly, users can be added to the database without them having anything in the shopping cart.
- Every customer's user type is not repeated unnecessarily, and there is no possibility for contradiction.
- If suitable foreign keys are also defined (e.g.,
USER_CART.username -> USER.username), one would get referential integrity guaranteed by the RDBMS and its niceties: shopping carts could not be added for non-existent users, and changing or deleting a user ID would cause the RDBMS to automatically handle changes or deletions of the shopping cart.
In principle, some small danger spots can still be found. For example, it is possible that there would only be basic customers in the database, in which case there would be no information about other user types. Though depending on the domain, this is not necessarily a critical issue. If it is, the next normal form takes a stand on this case too.
Third Normal Form
Esimerkki
Development of the Webbikauppa.com company's website continues. The company would like to clarify earning of user types by adding a numerical bonus level to the application. The bonus level is a number 1-9, and the bonus level always rises when a customer orders products. In the future, the user's user type would be determined based on the bonus level as follows:
- Bonus level 1-3: Basic user
- Bonus level 4-6: Bonus customer
- Bonus level 7-9: VIP customer
The coder making the application and database states that the user's bonus level is clearly a user property, like the user type, and thus it belongs to the USER table. So the coder adds a column bonus_level to the table. The table looks like this after the change:
| username | usertype | bonus_level |
|---|---|---|
| matthew123 | Basic Customer | 3 |
| hilda02 | VIP Customer | 8 |
| asko_96 | Bonus Customer | 5 |
This time the coder is enlightened about normalization. The coder notes that the table is clearly still in 1NF, as the primary key did not change, the bonus_level column has a clear data type (number), and the new column does not contain multi-valued values.
The coder thinks through the functional dependencies. They state that from the primary key comes the functional dependency
{username} -> {usertype, bonus_level}
This does not violate 2NF, as the determinant attribute set is the whole primary key and it cannot be split further. Additionally, the coder notes that now based on the bonus level, the user type can be uniquely deduced, i.e., a new functional dependency was born:
{bonus_level} -> {usertype}
Even this does not violate 2NF, as the determinant attribute set {bonus_level} is not in the primary key at all. The requirements of 2NF concern only those functional dependencies where the determinant attribute set has attributes belonging to the primary key.
Harjoittele
Look at the table and model data above. Consider what kind of anomalies or possible redundancy can arise. Remember that an anomaly is a contradiction in the table's data resulting from adding, modifying, or deleting data.
What other possible problems can arise when trying to use the table above?
After considering the matter, you can read the explanation below:
As stated, the relation satisfies the requirements of 2NF. Anomalies can still arise.
Possible anomalies:
- If matthew123's bonus level is increased to the next level, his user type should also change. However, it can be forgotten, leading to a contradiction where matthew123's bonus level does not correspond to his user type.
- Related to the same issue, if user types are wanted to be changed sometime (e.g. define that VIP customer status is obtained only at level
9), one has to go through every user's data and update their user type based on the new rules. If some user's user type is not updated correctly, a contradiction with the new rules arises.
Problems with redundancy:
- The user type is now repeated unnecessarily, as the user type can be deduced directly from the bonus level.
Other problems:
- Similarly as before, there is not yet an easy way to map out what user types exist and what correspond to their levels. This is not a problem per se, but in practice either the application using the database or the database maintainer must know themselves how bonus levels and user types are determined. This is not necessarily a problem, but to avoid contradictions, it would be better if the correspondence between bonus level and user type was defined directly in the database structure.
At the core of the third normal form are so-called transitive functional dependencies, i.e., dependencies that depend on the primary key indirectly via another attribute. In the example above usertype depends on the bonus level ({bonus_level} -> {usertype}), which in turn depends on the primary key ({username} -> {bonus_level}). It can thus be said that the user type depends transitively on the username; it can be denoted as follows:
{username} -> {bonus_level} -> {usertype}
Määritelmä
A relation is in 3NF, if all following requirements hold:
- The relation is in 2NF.
- All attributes not belonging to the relation's primary key depend only, solely, and strictly on the primary key and not on any other attribute.
Exception: If the determinant attribute set of a functional dependency is a candidate key of the relation (i.e., it identifies all attributes of the relation), it does not violate 3NF.
In other words, 3NF requires that every attribute not belonging to the primary key depends only on the primary key. The only functional dependencies that 3NF practically allows are dependencies resulting from candidate keys.
Note especially that although 2NF requirements are automatically satisfied in relations with a primary key of only one attribute, the requirement of 3NF does not necessarily hold.
If desired, the requirement of 3NF can also be formulated via the definition of transitive dependency: a relation is in 3NF if no attribute not belonging to the relation's primary key is transitively dependent on the relation's primary key.
If a relation is not in 3NF, it is corrected practically by making separate relations for the violating functional dependencies. In this case too, one can use one's own discretion regarding how many relations to make.
Esimerkki
Let's return to the example above and correct it to satisfy 3NF.
As stated, the new table USER(username, usertype, bonus_level) has two functional dependencies:
{username} -> {bonus_level}- "If the user's username is known, their bonus level is known."
- 3NF OK: The determinant set is
{username}, which is the primary key.
{bonus_level} -> {usertype}- "If the user's bonus level is known, their user type is known."
- 3NF FAIL: The determinant set is
{bonus_level}, which is not the relation's primary key.
Here the dependency resulting from the primary key {username} -> {bonus_level, usertype} is trivial, as it can be derived from the transitivity rule.
The solution is thus to remove the column usertype from the USER table, so the result is:
| username | bonus_level |
|---|---|
| matthew123 | 3 |
| hilda02 | 8 |
| asko_96 | 5 |
Additionally, a separate table BONUSLEVEL_TYPE is created for the violating functional dependency {bonus_level} -> {usertype}, and associations between bonus levels and user types are entered there:
| bonus_level | usertype |
|---|---|
| 1 | Basic Customer |
| 2 | Basic Customer |
| 3 | Basic Customer |
| 4 | Bonus Customer |
| 5 | Bonus Customer |
| 6 | Bonus Customer |
| 7 | VIP Customer |
| 8 | VIP Customer |
| 9 | VIP Customer |
With this solution, practically all worries are fixed:
- When a user's bonus level rises, the user type does not need to be updated simultaneously, as it can be deduced from a different table.
- It is easy to change bonus level rules: it is easy to add new bonus levels or change user type names by just modifying rows of the
BONUSLEVEL_TYPEtable. - The bonus level can now be made a foreign key
USER.bonus_level -> BONUSLEVEL_TYPE.bonus_level, obtaining all referential integrity checks offered by the RDBMS: a user's bonus level could no longer be accidentally set to a number other than 1-9; deletion and modification of a bonus level would be automatically propagated to users whom the change concerns. - A plus is that all possible user types are coded into the database. It is extremely easy to find out what different user types exist.
Boyce/Codd Normal Form
Boyce/Codd normal form is only a small variation of 3NF, which prunes out the final "deficient" dependencies. Let's introduce the definition of BCNF right at the start for comparison:
Määritelmä
A relation is in BCNF if the following requirements hold:
- The relation is in 3NF.
- All attributes of the relation depend only, solely, and strictly on some candidate key and not on any other attribute.
In other words, functional dependencies where the determinant set is not some candidate key of the relation are forbidden.
Note the difference in requirements between 3NF and BCNF:
- 3NF: "All attributes not belonging to the relation's primary key depend only, solely, and strictly on the primary key and not on any other attribute."
- BCNF: "All attributes of the relation depend only, solely, and strictly on some candidate key and not on any other attribute."
Note that BCNF requires that all candidate keys (i.e., attribute sets identifying all other attributes of the relation) are identified from the relation. Remember that the primary key is also a candidate key. On the other hand, the definition of BCNF is slightly more general and might be easier to remember.
In practice, the difference between BCNF and 3NF is very small. Very often relations in 3NF are also in BCNF. Usually BCNF is violated in cases where the relation has multiple "overlapping" candidate keys, i.e., some attributes appear in multiple different candidate keys.
However, let's look at an example where 3NF holds but BCNF does not.
Esimerkki
One case where BCNF does not necessarily hold is in requirements related to concurrency of resources or times.
The Webbikauppa.com company wants to offer big corporate customers a possibility to book appointments for consultation (e.g. price comparison, planning big purchases, etc.). The consultation is held on a certain day and time in the shop's brick-and-mortar store and a room and salesperson are booked for it. A salesperson reserves their room for the whole day. On different days the same salesperson might have a different room, as rooms might be booked. Only one consultation is booked for the same day for a customer, so that there would be room for all customers.
For consultations, a table must be added to the database to keep track of consultation information (time, customer, which salesperson handles it, room).
Based on the requirements, the coder created the following table:
| username | day | time | sid | room_number |
|---|---|---|---|---|
| matthew123 | 2025-01-30 | 12:00 | seller01 | room101 |
| matthew123 | 2025-02-10 | 12:00 | seller02 | room102 |
| hilda06 | 2025-01-30 | 15:00 | seller01 | room101 |
| asko_96 | 2025-03-01 | 13:00 | seller03 | room100 |
Based on the table and requirements, the coder deduced the following functional dependencies:
{username, day} -> {time, sid, room_number}- "If the user's username and consultation day are known, the time of consultation, ID of participating salesperson, and booked room are known."
- Based on this
{username, day}is a candidate key, it is also the primary key in this case
{sid, day, time} -> {username, room_number}- "If the salesperson's ID, consultation day, and time are known, the ID of the customer coming to the consultation and the booked room are known."
- This holds, as a salesperson can be in only one consultation at the same time
- Note: based on this
{sid, day, time}is also a candidate key
{room_number, day, time} -> {username, sid}- "If the consultation day, time, and room are known, the IDs of the customer and salesperson coming to the place are known."
- This holds, as there can be only one consultation in a room at the same time, i.e., from the room number, day, and time it is known who participates in the consultation.
- Note: based on this
{room_number, day, time}is also a candidate key
{sid, day} -> {room_number}- "If the salesperson's ID and day are known, it is known which room they have reserved for the day"
- Note:
{sid, day}is not a candidate key! From the salesperson's ID and day, only the room number reserved by the salesperson can be known based on the requirements, but not who the customer coming is.
Note that 1NF, 2NF, and 3NF hold:
- 1NF is OK, as a primary key is selected, attributes have a clear data type and there are no multi-valued attributes.
- 2NF is OK, as dependency
{username, day} -> {time, sid, room_number}is full.timedepends fully on the primary key{username, day}and not just on its part; without username or day it is not uniquely known at what time the consultation could besiddepends fully on the primary key{username, day}and not just on its part; without username or day it is not known which salesperson participates in the consultationroom_numberdepends fully on the primary key{username, day}and not just on its part; without username or day it is not known in which room the consultation is
- 3NF is OK due to the exception rule: in all functional dependencies the determinant set is either a primary key or a candidate key.
However, now BCNF requires that every attribute must depend only and solely on the relation's candidate keys. For functional dependency {sid, day} -> {room_number} this does not hold, as {sid, day} is not a candidate key.
The solution is to move the violating functional dependency to its own table. So finally we end up with table CONSULTATION_BOOKING, which tells the time and salesperson of the booked consultation:
| username | day | time | sid |
|---|---|---|---|
| matthew123 | 2025-01-30 | 12:00 | seller01 |
| matthew123 | 2025-02-10 | 12:00 | seller01 |
| hilda06 | 2025-01-30 | 15:00 | seller02 |
| asko_96 | 2025-03-01 | 13:00 | seller03 |
Additionally, for functional dependency {sid, day} -> {room_number} a table ROOM_BOOKING is made, telling which room the salesperson reserved for themselves for the day:
| sid | day | room_number |
|---|---|---|
| seller01 | 2025-01-30 | room101 |
| seller01 | 2025-02-10 | room102 |
| seller02 | 2025-01-30 | room101 |
| seller03 | 2025-03-01 | room100 |
Fourth Normal Form
Usually BCNF is sufficient for normalization. For certain tables that model multi-valued data, the definition of functional dependency is not enough to identify anomalies.
Esimerkki
Let's look at the Webbikauppa.com company's database one last time.
Webbikauppa.com wants to start selling their own pre-built desktop computers. Different models of desktop computers are offered, and each model has a set of customizable features, such as amount of RAM, processor model, and graphics card model. They would like to model in the database what features are available for different models.
Based on the requirement, a table PC_MODEL_VERSIONS was made:
| model | ram | cpu_model | gpu_model |
|---|---|---|---|
| Brick | 4 GB | AMD Ryzen 3 | NVIDIA GeForce GTX 1080 |
| Brick | 8 GB | AMD Ryzen 3 | NVIDIA GeForce GTX 1080 |
| Brick | 4 GB | AMD Ryzen 5 | NVIDIA GeForce GTX 1080 |
| Brick | 8 GB | AMD Ryzen 5 | NVIDIA GeForce GTX 1080 |
| Brick | 4 GB | AMD Ryzen 3 | NVIDIA GeForce RTX 2060 |
| Brick | 8 GB | AMD Ryzen 3 | NVIDIA GeForce RTX 2060 |
| Brick | 4 GB | AMD Ryzen 5 | NVIDIA GeForce RTX 2060 |
| Brick | 8 GB | AMD Ryzen 5 | NVIDIA GeForce RTX 2060 |
| Chunk | 32 GB | Intel Core i7 | NVIDIA GeForce GTX 1080 |
| Chunk | 64 GB | Intel Core i7 | NVIDIA GeForce GTX 1080 |
| Chunk | 32 GB | Intel Core i9 | NVIDIA GeForce GTX 1080 |
| Chunk | 64 GB | Intel Core i9 | NVIDIA GeForce GTX 1080 |
| Chunk | 32 GB | Intel Core i7 | NVIDIA GeForce RTX 2060 |
| Chunk | 64 GB | Intel Core i7 | NVIDIA GeForce RTX 2060 |
| Chunk | 32 GB | Intel Core i9 | NVIDIA GeForce RTX 2060 |
| Chunk | 64 GB | Intel Core i9 | NVIDIA GeForce RTX 2060 |
Based on the table, two PC models are available: Brick and Chunk. Each model has two different RAM, processor, and graphics card options.
Note that the primary key contains all columns {model, ram, cpu_model, gpu_model}. There are no functional dependencies here, as no column identifies any other column: a model can have many different feature options, and a single feature (e.g. processor model) can be used in different models.
There are no functional dependencies, and thus there is nothing that would violate the requirements of BCNF.
Harjoittele
Look at the table and model data above. Consider what kind of anomalies or possible redundancy can arise. Remember that an anomaly is a contradiction in the table's data resulting from adding, modifying, or deleting data.
What other possible problems can arise when trying to use the table above?
After considering the matter, you can read the explanation below:
There is redundancy in the table, but due to the choice of primary key it cannot be avoided. As stated, there are no functional dependencies, but the table can still be ruined by carelessness:
Possible anomalies:
- If one now wanted to add a larger RAM option (e.g. 16 GB) for the Brick model, one would have to add a whole 8 rows for every processor and graphics card option that is now available for the Brick model. If one option is forgotten, one is left in a contradictory state where not all processor and graphics card options are available for the 16 GB model.
Other:
- Redundancy is extremely high! For every new feature, one would have to add so many rows that all possible combinations are listed.
In the example above, columns do not have functional dependencies. Can something still be said about how columns relate to each other? From the example table, it can be stated that:
- The Brick model has exactly two RAM options: 4 GB or 8 GB. RAM options do not depend on the processor model or graphics card model.
- Likewise, the Chunk model has exactly two RAM options: 32 GB or 64 GB, and that too does not depend on the processor or graphics card.
- Similarly, models have exactly two options for
cpu_modelcolumn value, likewise forgpu_modelcolumn, and their values do not depend directly on each other.
In a functional dependency, an attribute can identify single values of another attribute. In this example, it is not so, but we are close: attribute model identifies the set of values of attribute ram. In other words, if the model is known, it can be known what RAM options it has. Let's generalize this observation into a definition:
Määritelmä
If a set of attributes X of relation R identifies the value set of another set of attributes Y of the same relation regardless of the relation's other attributes, it is said that a multi-valued dependency {X} ->> {Y} holds in the relation.
In other words, if a relation contains attribute sets X, Y and Z, then for every tuple where the value of attribute set X is a, the set of values of attribute set Y is always b regardless of the values of attribute set Z.
Additionally, if the determinant and dependent attribute set together {X, Y} contain all attributes of the relation, it is said that dependency {X} ->> {Y} is trivial. Otherwise, the dependency is non-trivial.
Based on the example above, it can thus be stated that {model} ->> {ram}, {model} ->> {cpu_model} and {model} ->> {gpu_model}. In other words, possible value options of RAM (or processor model or graphics card) depend only on the model and not on any other attribute.
Based on this definition, the requirements of the fourth normal form can be presented:
Määritelmä
A relation is in 4NF, if all following requirements are met:
- The relation is in BCNF.
- The determinant attribute set of all non-trivial multi-valued dependencies of the relation must be a candidate key of the relation.
In other words, if there is a multi-valued dependency {X} ->> {Y} in the relation, then attribute set X must be a candidate key of the relation.
Note that 4NF concerns only non-trivial dependencies. Due to this, 4NF applies in practice only to tables with more than two columns. Due to the restriction, tables modeling binary N:M relationships also satisfy 4NF.
In practice, 4NF can be broken only if one tries to model multiple N:M relationships simultaneously in the same table during the database design phase. If transformation is performed correctly and according to rules, non-trivial multi-valued dependencies should not appear in the table at all.
Esimerkki
Let's finally normalize the example table. As stated, the following multi-valued dependencies were found:
{model} ->> {ram}- "If the model is known, all RAM options are uniquely known"
{model} ->> {cpu_model}- "If the model is known, all processor model options are uniquely known"
{model} ->> {gpu_model}- "If the model is known, all graphics card options are uniquely known"
All three dependencies are non-trivial: the union of the determinant and dependent set is not the whole table.
Additionally {model} is not the table's primary key {model, ram, cpu_model, gpu_model}, so 4NF does not hold. As a solution, a separate table is made for each dependency:
MODEL_RAMS:
| model | ram |
|---|---|
| Brick | 4 GB |
| Brick | 8 GB |
| Chunk | 32 GB |
| Chunk | 64 GB |
MODEL_CPUS:
| model | cpu_model |
|---|---|
| Brick | AMD Ryzen 3 |
| Brick | AMD Ryzen 5 |
| Chunk | Intel Core i7 |
| Chunk | Intel Core i9 |
MODEL_GPUS:
| model | gpu_model |
|---|---|
| Brick | NVIDIA GeForce GTX 1080 |
| Brick | NVIDIA GeForce RTX 2060 |
| Chunk | NVIDIA GeForce GTX 1080 |
| Chunk | NVIDIA GeForce RTX 2060 |
Note especially that the number of rows has been reduced: from the original 16 rows to 12 rows. Additionally, it is now easier to add new features to models: adding a new graphics card option means adding just a couple of rows to the table.
Closing Words on Normalization
This material is surely read by three distinct groups: future programmers and database administrators, future researchers and database designers, and those who possibly stay far away from databases after this material (hopefully not due to this material though).
Programmers and administrators: examining normalization can be difficult, and it requires good understanding of the domain. Normalization could actually be summarized largely into two main rules, based on which tables should be designed:
- A table should store only information immediately related to the object.
- For example, a student's post office is information related to the zip code, not the student. If a table stores information of different objects, it signals a need to create a separate table.
- Update of each piece of information should happen in only one place.
- For example, if a student's zip code changes and because of that both zip code and post office must be updated in two different columns, it signals a need to create a separate table.
By following these two rules, one gets very far in database design.
Researchers and designers: Conceptual modeling is extremely profitable. If an ER diagram is made considering the needs of the domain and transformation is performed correctly, the result is often relations implementing 3NF or even BCNF.
It should be mentioned that there are other normal forms in reality. Some of them are between the treated normal forms in strictness, but most are stronger than the treated normal forms. Especially the fifth normal form would require more formal examination.
Normalization has been attempted to be presented in this chapter as simply as possible without going into too formal definitions. Definitions introduced in this chapter are by no means official; those interested in precise definitions can continue familiarizing themselves with the topic for example in Elmasri and Navathe's book [15].
Other readers: Hopefully this was not too heavy a chapter 😅. The most essential thing that should remain in mind is that the structure of tables can influence the usability and "foolproofness" of the database. On the other hand, the more information is distributed into different tables, the slower database queries are. Additionally, in current database management systems normalization beyond 2NF can even increase disk space usage [36]. Thus, it can be stated that actually normalization is not always even profitable. Nowadays storage space is quite cheap, and users want ever faster applications. In that sense, it can be justified to add a little redundancy to data if it reduces the amount and complexity of database queries. One even talks about denormalization of databases: tables are left unnormalized or changed to a lower normal form so that queries would be faster.
Normaalimuodot
Aiemmassa luvussa todettiin, että normalisoidun relaation rakenne vähentää turhaa toisteisuutta sekä auttaa välttämään ristiriitaisuuksien syntymistä datassa. Normalisointi ei kuitenkaan ole kaksiarvoinen käsite: relaatio ei ole vain joko normalisoimaton tai normalisoitu. Mahdollisia poikkeamia ja toisteisuuksia on erilaisia, ja joskus eri tapauksissa voidaan hyväksyä, että jokin relaation rakenne on enemmän "optimoitu" kuin toinen.
Relaatioiden normalisointi määritellään ja suoritetaan tasoittain. Normaalimuoto on joukko relaation rakenteeseen liittyviä vaatimuksia, joita relaatio voi täyttää. Vaatimukset esitellään yleensä funktionaalisten riippuvuuksien kautta. Relaatio, joka täyttää tietyn normaalimuodon vaatimukset, saa normaalimuodon mukaisia takeita poikkeamien sietokyvystä tai olemassaolosta. Normaalimuotoja on useita; tässä luvussa esitellään seuraavat normaalimuodot niiden vahvuusjärjestyksessä:
- Ensimmäinen normaalimuoto (1NF)
- Toinen normaalimuoto (2NF)
- Kolmas normaalimuoto (3NF)
- Boyce/Codd-normaalimuoto (BCNF)
- Neljäs normaalimuoto (4NF)
Korkeammat normaalimuodot tarjoavat vahvempia takeita poikkeamien puuttumisesta tai sietokyvystä. Ensimmäinen normaalimuoto on perusmuoto, jonka jokaisen relaatiomallin mukaisen tietokannan tulee täyttää. Seuraavat muodot määritellään aina edeltävien muotojen kautta: relaatio, joka täyttää 3NF:n, täyttää myös 2NF:n, ja relaatio, joka täyttää 2NF:n, täyttää myös 1NF:n.
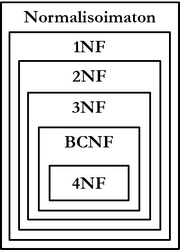
Normalisointi on aina relaatiokohtainen prosessi, eikä kaikkien tietokannan relaatioiden tarvitse olla samassa normaalimuodossa. Normalisointi myös yleensä suoritetaan tasoittain: ensin varmistetaan 1NF:n vaatimukset, sitten 2NF:n, jne. kunnes relaatio on normalisoitu halutulle tasolle. Jos relaatio ei täytä normaalimuodon vaatimuksia, relaatio voidaan korjata esimerkiksi jakamalla se kahdeksi tai useammaksi relaatioksi. Jaot ja muutokset tulee kuitenkin tehdä niin, että kohdealueen dataa ei katoa.
Seuraavaksi esitellään neljän ensimmäisen normaalimuodon vaatimukset sekä ohjeet relaation saattamiseksi niihin. Mainittakoon, että tässä materiaalissa annetut vaatimukset eivät ole formaaleja, vaan ne ovat eri kirjailijoiden muotoilujen ([34], [13], [21]) perusteella tehtyjä yhteenvetoja.
Ennen jokaista muotoa esitellään esimerkkitaulu ja pohditaan, millaisia poikkeamia taulussa voi syntyä.
Huomautus
Luvussa 5.1 esiteltiin päättelysääntöjä, joiden perusteella funktionaalisia riippuvuuksia voi yhdistää. Riippuvuudet, jotka voi päätellä päättelysäännöillä, ovat triviaaleja. Jos riippuvuutta ei voi keksiä päättelysäännöllä, vaan se perustuu tauluun tai kohdealueeseen, se on epätriviaali.
Tässä luvussa esitetyt vaatimukset koskevat aina epätriviaaleja riippuvuuksia, ellei toisin sanota.
Ensimmäinen normaalimuoto
Esimerkki
Webbikauppa.com on erilaisia kodintarvikkeita ja sähkölaitteita myyvä yritys. Yritykselle perustetaan verkkosivu, jonka kautta asiakkaat voivat ostaa tuotteita.
Yritys asetti seuraavat vaatimukset tietokannalle:
- Asiakkaat, jotka haluavat ostaa tavaroita verkkosivulta, tekevät itselleen ensin käyttäjätunnuksen.
- Sen jälkeen asiakkaat voivat lisätä tavaroita ostoskoriin ja ostaa niitä.
- Ostoskori tallennetaan tietokantaan, jotta käyttäjä voi helposti katsella ostoskoriaan eri laitteilla (tietokone, puhelin) ja jotta käyttäjä voisi halutessaan käydä tilaamassa tuotteet suoraan kivijalkaliikkeestä.
Sovellusta ja tietokantaa tekevä koodari päätyi tekemään taulun KÄYTTÄJÄ, joka sisältää käyttäjän tiedot ja hänen ostoskorinsa. Tauluun on saatu seuraavaa mallidataa:
| käyttäjätunnus | ostoskori |
|---|---|
| matti123 | 2 kpl tuote-00000001, 3 kpl tuote-00000002 |
| hilda02 | 12 kpl tuote-00000003 |
| asko_96 | 3 kpl tuote-00000004, 1 kpl tuote-00000002, 8 kpl tuote-00000003, 1 kpl tuote-00000001 |
Taulua luodessa taululle ei asetettu perusavainta. Tuotteet kuvataan tuotteen EAN-viivakoodilla (muotoa tuote-12345678), joiden tiedot löytyvät muualta.
Harjoittele
Katsele yllä olevaa taulua ja mallidataa. Pohdi, millaisia poikkeamia tai mahdollista toisteisuutta voi syntyä. Muista, että poikkeama on tiedon lisäyksestä, muokkauksesta tai poistosta johtuva ristiriita taulun tiedoissa.
Mitä muita mahdollisia ongelmia voi syntyä, kun yllä olevaa taulua yrittää käyttää?
Kun olet pohtinut asiaa, voit lukea selityksen alla:
Tässä ydinongelmana ovat perusavaimen puuttuminen sekä ostoskorin arvojen moniarvoisuus. Tästä voi syntyä kaikenlaisia poikkeamia:
- Tauluun voidaan lisätä rivejä, joilla on sama käyttäjätunnus. Koska perusavainta ei valittu, voidaan esimerkiksi lisätä 5 riviä, joissa
käyttäjätunnuson matti123. SQL-speksin mukaan tämä sallitaan, mutta silloin käyttäjällä matti123 olisi monta ostoskoria. - Jos ostoskorin tyhjentää poistamalla rivi, käyttäjätunnus katoaa kokonaan tietokannasta.
- Tuotteen EAN-koodi saattaa muuttua. Silloin pitäisi käydä käyttäjien kaikki ostoskorit läpi ja korjata EAN-koodi, mikä voi olla virhealtista. Voi vahingossa jättää päivittämättä jonkun ostoskorissa olevan tuotteen EAN-koodia, eikä siitä tule mitään varoitusta.
Ongelmia toisteisuudessa:
- Periaatteessa EAN-koodeja ja kappalemääriä joutuu toistamaan. Toisaalta ilman sitä ei voida esittää ostoskorin tietoja. Toisteisuus voi kuitenkin aiheuttaa yllä mainitun muokkauspoikkeaman.
Muita ongelmia:
- Ostoskorin tietotyyppi ei ole selkeä. Tarkemmin, ei ole selvää, mihin SQL-kielen mukaiseen tietotyyppiin (Luku 4.3) se kuuluisi. Ostoskorissa on nyt kappalemääriä (luku), mutta myös EAN-koodeja (merkkijono tai numero).
- On vaikeaa tarkastella useita eri ostoskoreja. Jos haluttaisiin tietää, ketkä ovat tilanneet tuotetta "tuote-00000003" ja ostoskori olisi esim. merkkijono, joutuisi hakemaan EAN-koodeja merkkijonoista. Tämä voi taas olla virhealtista.
- Ostoskoreja on vaikeaa ylläpitää. Jos ne ovat merkkijonoina, ostoskorit "1 kpl tuote-01, 1 kpl tuote-01" sekä "2 kpl tuote-01" tarkoittaisivat samaa asiaa. Tämä ei sinänsä ole toisteisuutta tai poikkeama, mutta sama tieto kuvataan kahdella eri tavalla, mikä vaikeuttaa tietokannan ylläpitoa.
Ensimmäinen normaalimuoto liittyy siis Luvussa 3.1 esiteltyihin relaatiomallin perusominaisuuksiin. Esimerkin mukaisiin ongelmiin voidaan päästä ainakin SQL-spesifikaation mukaisissa tietokannoissa, sillä spesifikaatio esimerkiksi ei vaadi, että taululla olisi perusavain. Lisäksi monen arvon säilyttäminen yhdessä sarakkeessa johtaa helposti tietokannan käytön ongelmiin.
Ensimmäinen normaalimuoto käytännössä vaatii, että taulu on suunniteltu relaatiomallin sääntöjen mukaisesti.
Määritelmä
Relaatio on 1NF:ssä, jos se täyttää relaation vaatimukset:
- Relaatiolle tulee olla valittuna sopiva perusavain.
- Monikoiden (eli rivien) järjestyksellä ei saa olla merkitystä tiedon kannalta.
- Jokaisella attribuutilla (eli sarakkeella) tulee olla yksi selkeä tietotyyppi. Erityyppisen datan sekoittaminen samassa attribuutissa on kielletty.
- Jokainen attribuutti on atominen, eli ei sisällä montaa arvoa.
Jos relaatio ei täytä 1NF:ää, korjausvaiheet ovat:
- Jaa moniarvoiset attribuutit niin, että jokaiselle arvolle tulee oma rivi.
- Tarvittaessa lisää attribuutteja niin, että jokainen on selkeää tietotyyppiä.
- Valitse sopiva perusavain.
Esimerkki
Nyt selvästi yllä oleva esimerkki ei täytä 1NF:ää.
Korjaukseksi ostoskori tulee jakaa kahteen attribuuttiin: ostoskori_tuote (EAN-koodi) ja tuote_määrä (numero). Lisäksi ostoskorin jokainen tuote tallennetaan omalle rivilleen. Saadaan tulokseksi:
| käyttäjätunnus | ostoskori_tuote | tuote_määrä |
|---|---|---|
| matti123 | tuote-00000001 | 2 |
| matti123 | tuote-00000002 | 3 |
| hilda02 | tuote-00000003 | 12 |
| asko_96 | tuote-00000004 | 3 |
| asko_96 | tuote-00000002 | 1 |
| asko_96 | tuote-00000003 | 8 |
| asko_96 | tuote-00000001 | 1 |
Lisäksi valitaan perusavaimeksi {käyttäjätunnus, ostoskori_tuote}, jolloin jokaisella käyttäjällä voi olla usea tuote ostoskorissa, mutta samalle tuotteelle ei voi vahingossa lisätä toista riviä (vaan pitää päivittää lukumäärä). Lisäksi jos tuotteen tunnuksesta tehtäisiin viiteavain tauluun, joka sisältää kaikkien tuotteiden tiedot, käyttäjille ei voisi edes vahingossa lisätä tuotteita, joita ei ole olemassa. Lisäksi RDBMS hoitaisi silloin automaattisesti mahdolliset EAN-koodien muutokset tai tuotteiden poistot.
Nyt taulu on 1NF:ssä. Huomaa, että 1NF ei ratkaise kaikkia poikkeamia: esimerkiksi jos hilda02:n ostoskori tyhjennetään poistamalla rivi, hilda02 häviää koko tietokannasta.
Toinen normaalimuoto
Esimerkki
Jatketaan yllä olevaa esimerkkiä. Yrityksen Webbikauppa.com verkkosivuja on kehitetty eteenpäin. Yritys haluaisi lisätä verkkosivuille erilaisia asiakastyyppejä, joilla olisi erilaisia bonuksia ja alennuksia. Yritys miettii alkuun kolmea asiakastyyppiä: "Perusasiakas", "Bonusasiakas" sekä "VIP-asiakas".
Sovellusta ja tietokantaa tekevä koodari päätti hetken pohdittuaan yksinkertaisesti laajentaa vaatimuksen perusteella KÄYTTÄJÄ-taulua lisäämällä siihen sarakkeen käyttajatyyppi. Tuloksena syntyi seuraava päivitetty taulu (perusavainsarakkeet alleviivattu):
| käyttäjätunnus | ostoskori_tuote | tuote_määrä | käyttäjätyyppi |
|---|---|---|---|
| matti123 | tuote-00000001 | 2 | Perusasiakas |
| matti123 | tuote-00000002 | 3 | Perusasiakas |
| hilda02 | tuote-00000003 | 12 | VIP-asiakas |
| asko_96 | tuote-00000004 | 3 | Bonusasiakas |
| asko_96 | tuote-00000002 | 1 | Bonusasiakas |
| asko_96 | tuote-00000003 | 8 | Bonusasiakas |
| asko_96 | tuote-00000001 | 1 | Bonusasiakas |
Harjoittele
Katsele yllä olevaa taulua ja mallidataa. Pohdi, millaisia poikkeamia tai mahdollista toisteisuutta voi syntyä. Muista, että poikkeama on tiedon lisäyksestä, muokkauksesta tai poistosta johtuva syntyvä ristiriita taulun tiedoissa.
Mitä muita mahdollisia ongelmia voi syntyä, kun yllä olevaa taulua yrittää käyttää?
Kun olet pohtinut asiaa, voit lukea selityksen alla:
Tässä tapauksessa taulu on kyllä 1NF:ssä, mutta silti vaaroja poikkeamille on suuria.
Mahdolliset poikkeamat:
- Jos hilda02:n ostoskori tyhjennettäisiin poistamalla hänen rivinsä, on kaksi vaaraa: ensiksi, hilda02 katoaa tietokannasta käyttäjänä. Jos haluttaisiin tietää hilda02:n asiakastyyppi, se katoaa ostoskorin poiston yhteydessä. Toiseksi, jos hilda02:n rivi poistuisi ja tietokannalta kysyttäisiin, mitä eri asiakastyyppejä on olemassa, tulisi vastauksena vain kaksi asiakastyyppiä kolmen mahdollisen sijaan.
- Jos matti123:n asiakastyyppi päivittyy (esim. VIP-asiakkaaksi), joudutaan päivittämään kaikki rivit, jotka kuuluvat matti123:lle. Jos vahingossa jonkin matti123:n rivin asiakastyyppiä ei päivitetä, matti123:n asiakastyypistä tulee ristiriitainen.
- Vastaavasti jos matti123 lisää uusia tuotteita ostoskoriin, syntyy uusia rivejä. Tällöin voi vahingossa lisätä rivin, jossa matti123:n asiakastyyppi on eri kuin matti123:n muilla riveillä. Päädytään jälleen ristiriitaan.
Toisteisuuden ongelmia:
- Kuten jo mainittiin, yksittäisen käyttäjän asiakastyyppiä joudutaan toistamaan jokaisen ostoskoriin lisätyn tuotteen yhteydessä.
Muita ongelmia:
- Jos meille tulee uusi asiakas, hänen asiakastyyppiään ei saada tallennettua, ennen kuin asiakas lisää jotain tuotetta ostoskoriin.
Toiseen normaalimuotoon tarvitaankin jo funktionaalisia riippuvuuksia. Tarkemmin, 2NF liittyy siihen, miten relaatiossa olevien funktionaalisten riippuvuuksien määräävä joukko ja relaation perusavain liittyvät toisiinsa.
Määritelmä
Relaatio on 2NF:ssä, jos se täyttää seuraavat vaatimukset:
- Relaatio on 1NF:ssä.
- Mikään relaation perusavaimeen kuulumaton attribuutti ei riipu ainoastaan perusavaimen osasta, vaan koko perusavaimesta.
Toisin sanoen, jos on voimassa funktionaalinen riippuvuus {X} -> {Y}, jossa X:ssä on relaation perusavaimeen kuuluvat attribuutit ja Y ei kuulu perusavaimeen, niin X:stä ei voi ottaa pois perusavaimeen kuuluvia attribuutteja siten, että funktionaalinen riippuvuus säilyisi. Tällaista funktionaalista riippuvuutta kutsutaan täydeksi funktionaaliseksi riippuvuudeksi.
Huomaa, että 2NF:ssä tulee tarkastaa vain ne funktionaaliset riippuvuudet, joiden määräävässä joukossa on mukana kaikki perusavaimeen kuuluvat attribuutit. Sellaiset riippuvuudet, joiden määräävässä joukossa on perusavaimeen kuulumattomia attribuutteja, eivät riko 2NF:ää. Seurauksena, jos relaation perusavaimessa on vain yksi attribuutti, relaatio on aina 2NF:ssä.
Toinen tapa ajatella 2NF:ää on: perusavaimen ja perusavaimeen kuulumattomien attribuuttien välisen funktionaalisen riippuvuuden tulee olla epätriviaali (eli sitä ei voi johtaa päättelysäännöistä). Erityisesti perusavainta ei voida jakaa osiin niin, että jokin perusavaimen ja muiden attribuuttien riippuvuuksista säilyisi.
Jos relaatio ei täytä 2NF:ää, sen saa korjattua tekemällä jokaiselle 2NF:ää rikkovalle funktionaaliselle riippuvuudelle oman relaation, jossa on funktionaalisen riippuvuuden osapuolina olevat attribuutit. Määräävästä joukosta tulee uuden relaation perusavain.
Esimerkki
Jatketaan yllä olevaa esimerkkiä. Mietitään läpi, mitä kaikkia funktionaalisia riippuvuuksia taulusta löytyy ja miten ne täyttävät 2NF:n:
{käyttäjätunnus, ostoskori_tuote} -> {tuote_määrä}- "Jos tiedetään tietyn käyttäjän tunnus ja tuote, tiedetään, kuinka monta kappaletta kyseinen käyttäjä on tilannut kyseistä tuotetta."
- 2NF on OK: määräävä attribuuttijoukko on
{käyttäjätunnus, ostoskori_tuote}, joka on sama kuin relaation perusavain JA jos siitä otettaisiin jompikumpi attribuuteista pois, riippuvuus ei enää voisi päteä.
{käyttäjätunnus} -> {käyttäjätyyppi}- "Jos tiedetään tietyn käyttäjän tunnus, tiedetään tämän käyttäjän käyttäjätyyppi."
- 2NF FAIL: Määräävä attribuuttijoukko on
{käyttäjätunnus}, joka on vain osa relaation perusavainta eikä koko perusavain. Toisin sanoen riippuvuus{käyttäjätunnus, ostoskori_tuote} -> {käyttäjätyyppi}on triviaali.
Jotta 2NF täyttyy, pitää relaatio jakaa. Tehdään kahdelle funktionaaliselle riippuvuudelle omat relaatiot:
KÄYTTÄJÄ_OSTOSKORI(käyttäjätunnus, ostoskori_tuote, tuote_määrä), joka vastaa funktionaalista riippuvuutta {käyttäjätunnus, ostoskori_tuote} -> {tuote_määrä}:
| käyttäjätunnus | ostoskori_tuote | tuote_määrä |
|---|---|---|
| matti123 | tuote-00000001 | 2 |
| matti123 | tuote-00000002 | 3 |
| hilda02 | tuote-00000003 | 12 |
| asko_96 | tuote-00000004 | 3 |
| asko_96 | tuote-00000002 | 1 |
| asko_96 | tuote-00000003 | 8 |
| asko_96 | tuote-00000001 | 1 |
KÄYTTÄJÄ(käyttäjätunnus, käyttäjätyyppi), joka vastaa funktionaalista riippuvuutta {käyttäjätunnus} -> {käyttäjätyyppi}:
| käyttäjätunnus | käyttäjätyyppi |
|---|---|
| matti123 | Perusasiakas |
| hilda02 | VIP-asiakas |
| asko_96 | Bonusasiakas |
Nyt saatiin kaksi taulua, joissa turha toisteisuus on poistettu sekä ratkaistu poikkeamiin liittyviä murheita:
- Käyttäjille on oma taulu, joten nyt käyttäjä ei häviä tietokannasta, vaikka hänellä ei olisi ostoskoria.
- Vastaavasti käyttäjiä voidaan lisätä tietokantaan ilman, että heillä olisi mitään ostoskorissa.
- Jokaisen asiakkaan käyttäjätyyppi ei toistu turhaan, eikä ole mahdollisuutta ristiriitaan.
- Jos vielä määritetään sopivat viiteavaimet (esim.
KÄYTTÄJÄ_OSTOSKORI.käyttäjätunnus -> KÄYTTÄJÄ.käyttäjätunnus), saataisiin RDBMS:n takaama viite-eheys ja sen hienoudet: ostoskoreja ei voisi lisätä olemattomille käyttäjille, ja käyttäjän tunnuksen muutos tai poisto saisi RDBMS:n automaattisesti käsittelemään ostoskorin muutokset tai poistot.
Periaatteessa joitain pieniä vaaran paikkoja voi vielä löytyä. Esimerkiksi on mahdollista, että tietokannassa olisi vain perusasiakkaita, jolloin muista käyttäjätyypeistä ei olisi tietoa. Tosin kohdealueesta riippuen tämä ei välttämättä ole kriittinen asia. Jos se on, seuraava normaalimuoto ottaa kantaa tähänkin tapaukseen.
Kolmas normaalimuoto
Esimerkki
Webbikauppa.com-yrityksen verkkosivujen kehitys jatkuu. Yritys haluaisi selkeyttää käyttäjätyyppien ansaitsemista lisäämällä sovellukseen numeerisen bonustason. Bonustaso on numero 1-9, ja bonustaso nousee aina, kun asiakas tilaa tuotteita. Jatkossa käyttäjän käyttäjätyyppi määräytyisi bonustason perusteella seuraavasti:
- Bonustaso 1-3: Peruskäyttäjä
- Bonustaso 4-6: Bonusasiakas
- Bonustaso 7-9: VIP-asiakas
Sovellusta ja tietokantaa tekevä koodari toteaa, että käyttäjän bonustaso on selvästi käyttäjän ominaisuus, kuten käyttäjätyyppi, ja siten se kuuluu KÄYTTÄJÄ-tauluun. Niinpä koodari lisää tauluun sarakkeen bonustaso. Taulu näyttää muutoksen jälkeen seuraavalta:
| käyttäjätunnus | käyttäjätyyppi | bonustaso |
|---|---|---|
| matti123 | Perusasiakas | 3 |
| hilda02 | VIP-asiakas | 8 |
| asko_96 | Bonusasiakas | 5 |
Tällä kertaa koodari on valistunut normalisoinnista. Koodari toteaa, että taulu on selvästi edelleen 1NF:ssä, sillä perusavain ei muuttunut, bonustaso-sarakkeella on selkeä tietotyyppi (numero), eikä uusi sarake sisällä moniarvoisia arvoja.
Koodari miettii vielä läpi funktionaaliset riippuvuudet. Hän toteaa, että perusavaimesta tulee funktionaalinen riippuvuus
{käyttäjätunnus} -> {käyttäjätyyppi, bonustaso}
Tämä ei riko 2NF:ää, sillä määräävä attribuuttijoukko on koko perusavain eikä sitä voi jakaa osiin enempää. Lisäksi koodari toteaa, että nyt bonustason perusteella voidaan päätellä yksikäsitteisesti käyttäjän tyyppi, eli syntyi uusi funktionaalinen riippuvuus:
{bonustaso} -> {käyttäjätyyppi}
Tämäkään ei kuitenkaan riko 2NF:ää, sillä määräävä attribuuttijoukko {bonustaso} ei ole lainkaan perusavaimessa. 2NF:n vaatimukset koskevat vain niitä funktionaalisia riippuvuuksia, joissa määräävässä attribuuttijoukossa on perusavaimeen kuuluvia attribuutteja.
Harjoittele
Katsele yllä olevaa taulua ja mallidataa. Pohdi, millaisia poikkeamia tai mahdollista toisteisuutta voi syntyä. Muista, että poikkeama on tiedon lisäyksestä, muokkauksesta tai poistosta johtuva syntyvä ristiriita taulun tiedoissa.
Mitä muita mahdollisia ongelmia voi syntyä, kun yllä olevaa taulua yrittää käyttää?
Kun olet pohtinut asiaa, voit lukea selityksen alla:
Kuten on todettu, relaatio täyttää 2NF:n vaatimukset. Poikkeamia voi silti syntyä.
Mahdolliset poikkeamat:
- Jos matti123:n bonustasoa kasvatetaan seuraavalle tasolle, hänen käyttäjätyyppinsä pitäisi myös muuttua. Se voi kuitenkin unohtua, jolloin päädytään ristiriitaan, jossa matti123:n bonustaso ei vastaa hänen käyttäjätyyppiään.
- Samaan liittyen, jos joskus käyttäjätyyppejä halutaan muuttaa (esim. määrittää, että VIP-asiakkuuden saa ainoastaan tasolla
9), joudutaan käymään jokaisen käyttäjän tiedot läpi ja päivittämään hänen käyttäjätyyppinsä uusien sääntöjen perusteella. Jos jonkun käyttäjän käyttäjätyyppiä ei päivitetä oikein, joudutaan ristiriitaan uusien sääntöjen kanssa.
Toisteisuuden ongelmia:
- Käyttäjätyyppi toistuu nyt turhaan, sillä käyttäjätyyppi voidaan päätellä suoraan bonustasosta.
Muita ongelmia:
- Vastaavasti kuten aiemminkin, ei ole vielä helppoa tapaa kartoittaa, mitä käyttäjätyyppejä on olemassa ja mitkä ovat niiden vastaavat tasot. Tämä ei sinänsä ole ongelma, mutta käytännössä joko tietokantaa käyttävän sovelluksen tai tietokannan ylläpitäjän pitää itse tietää, miten bonustasot ja käyttäjätyypit määräytyvät. Tämä ei välttämättä ole ongelma, mutta ristiriitojen välttämiseksi olisi parempi, että bonustason ja käyttäjätyypin vastaavuus olisi määritelty suoraan tietokannan rakenteeseen.
Kolmannen normaalimuodon ytimessä ovat ns. transitiiviset funktionaaliset riippuvuudet, eli riippuvuudet, jotka riippuvat perusavaimesta epäsuorasti toisen attribuutin kautta. Yllä olevassa esimerkissä käyttäjätyyppi riippuu bonustasosta ({bonustaso} -> {käyttäjätyyppi}), joka puolestaan riippuu perusavaimesta ({käyttäjätunnus} -> {bonustaso}). Voidaan siis sanoa, että käyttäjätyyppi riippuu transitiivisesti käyttäjätunnuksesta; se voidaan merkitä seuraavasti:
{käyttäjätunnus} -> {bonustaso} -> {käyttäjätyyppi}
Määritelmä
Relaatio on 3NF:ssä, jos kaikki seuraavat vaatimukset pätevät:
- Relaatio on 2NF:ssä.
- Kaikki relaation perusavaimeen kuulumattomat attribuutit riippuvat vain sellaisista attribuuteista, jotka kuuluvat johonkin avainehdokkaaseen.
Toisin sanoen 3NF vaatii, että jokainen perusavaimeen kuulumaton attribuutti riippuu vain avainehdokasattribuuteista. Huomaa, että vaatimus ei tarkoita, että attribuuttien pitäisi riippua avainehdokkaasta kokonaan. Sen sijaan riittää, että jokainen määräävässä joukossa oleva attribuutti kuuluu johonkin taulun avainehdokkaaseen.
3NF siten vaatii, että relaatiosta tunnistetaan kaikki avainehdokkaat (eli attribuuttijoukot, jotka yksilöivät relaation kaikki muut attribuutit). Muista, että perusavain on myös avainehdokas.
Huomaa lisäksi, että vaikka 2NF:n vaatimukset automaattisesti täyttyvät relaatioissa, joissa on vain yhden attribuutin perusavain, 3NF:n vaatimus ei välttämättä päde.
3NF:n vaatimuksen voi halutessaan muotoilla myös transitiivisen riippuvuuden määritelmän kautta: relaatio on 3NF:ssä, jos mikään relaation perusavaimeen kuulumaton attribuutti ei ole transitiivisesti riippuvainen relaation perusavaimesta.
Jos relaatio ei ole 3NF:ssä, se korjataan käytännössä tekemällä rikkoville funktionaalisille riippuvuuksille omat relaatiot. Tässäkin tapauksessa voi käyttää omaa harkintaa sen mukaan, kuinka monta relaatiota tekee.
Esimerkki
Palataan yllä olevaan esimerkkiin ja korjataan se 3NF:ää täyttäväksi.
Kuten todettiin, uudella taululla KÄYTTÄJÄ(käyttäjätunnus, käyttäjätyyppi, bonustaso) on kaksi funktionaalista riippuvuutta:
{käyttäjätunnus} -> {bonustaso}- "Jos tiedetään käyttäjän tunnus, tiedetään hänen bonustaso."
- 3NF OK: Määräävä joukko on
{käyttäjätunnus}jakäyttäjätunnuson perusavaimessa ja siten avainehdokkaassa.
{bonustaso} -> {käyttäjätyyppi}- "Jos tiedetään käyttäjän bonustaso, tiedetään hänen käyttäjätyyppinsä."
- 3NF FAIL: Määräävä joukko on
{bonustaso}. Tarjolla olevien funktionaalisten riippuvuuksien perusteella vain{käyttäjätunnus}on ainoa taulun avainehdokas.bonustasoei kuulu siten mihinkään avainehdokkaaseen, ja siten tänä funktionaalinen riippuvuus rikkoo 3NF.
Tässä perusavaimesta johtuva riippuvuus {käyttäjätunnus} -> {bonustaso, käyttäjätyyppi} on triviaali, sillä sen voi johtaa transitiivisuussäännöstä.
Ratkaisuna siis poistetaan KÄYTTÄJÄ-taulusta sarake käyttäjätyyppi, jolloin lopputulos on:
| käyttäjätunnus | bonustaso |
|---|---|
| matti123 | 3 |
| hilda02 | 8 |
| asko_96 | 5 |
Lisäksi luodaan rikkovalle funktionaaliselle riippuvuudelle {bonustaso} -> {käyttäjätyyppi} oma taulu BONUSTASO_TYYPPI ja syötetään sinne bonustasojen ja käyttäjätyyppien väliset yhteydet:
| bonustaso | käyttäjätyyppi |
|---|---|
| 1 | Perusasiakas |
| 2 | Perusasiakas |
| 3 | Perusasiakas |
| 4 | Bonusasiakas |
| 5 | Bonusasiakas |
| 6 | Bonusasiakas |
| 7 | VIP-asiakas |
| 8 | VIP-asiakas |
| 9 | VIP-asiakas |
Tällä ratkaisulla oikeastaan kaikki murheet korjaantuvat:
- Kun käyttäjän bonustaso nousee, ei tarvitse samalla päivittää käyttäjätyyppiä, sillä sen saa pääteltyä eri taulusta.
- On helppoa muuttaa bonustasojen sääntöjä: on helppoa lisätä uusia bonustasoja tai muuttaa käyttäjätyyppien nimityksiä muokkaamalla vain
BONUSTASO_TYYPPI-taulun rivejä. - Bonustasosta voidaan nyt tehdä viiteavain
KÄYTTÄJÄ.bonustaso -> BONUSTASO_TYYPPI.bonustaso, jolloin saadaan kaikki RDBMS:n tarjoamat viite-eheystarkastukset: käyttäjän bonustasoa ei voisi enää vahingossa asettaa muuksi numeroksi kuin 1-9; bonustason poisto ja muokkaus välittyisivät automaattisesti käyttäjiin, joita muutos koskee. - Plussana on, että tietokantaan on koodattu kaikki mahdolliset käyttäjätyypit. On erittäin helppoa selvittää, mitä eri käyttäjätyyppejä on olemassa.
Boyce/Codd-normaalimuoto
Boyce/Codd-normaalimuoto on vain pieni muunnelma 3NF:stä, joka karsii pois lopullisetkin "puutteelliset" riippuvuudet. Esitellään heti alkuun BCNF:n määritelmä vertailuksi:
Määritelmä
Relaatio on BCNF:ssä, jos seuraavat vaatimukset pätevät:
- Relaatio on 3NF:ssä.
- Kaikki relaation attribuutit riippuvat vain, ainoastaan ja kokonaan jostain avainehdokkaasta eikä mistään muusta attribuutista.
Toisin sanoen, funktionaaliset riippuvuudet, joissa määräävä joukko ei ole relaation jokin avainehdokas, ovat kiellettyjä.
Huomaa vaatimusero 3NF:n ja BCNF:n välillä:
- 3NF: "Kaikki relaation perusavaimeen kuulumattomat attribuutit riippuvat vain sellaisista attribuuteista, jotka kuuluvat johonkin avainehdokkaaseen."
- BCNF: "Kaikki relaation attribuutit riippuvat vain, ainoastaan ja kokonaan jostain avainehdokkaasta eikä mistään muusta attribuutista."
BCNF on siten vahvempi versio 3NF:ssä. Vain muotoa avainehdokas -> muut olevat funktionaaliset riippuvuudet ovat sallittu.
Käytännössä ero BCNF:n ja 3NF:n välillä on hyvin pieni. Hyvin usein 3NF:ssä olevat relaatiot ovat myös BCNF:ssä. Yleensä BCNF menee rikki tapauksissa, joissa relaatiossa on useampi päällekkäinen avainehdokas, eli jotkut attribuutit esiintyvät useassa eri avainehdokkaassa.
Katsotaan kuitenkin eräs esimerkki, jossa 3NF pätee, mutta BCNF ei.
Esimerkki
Eräs tapaus, jossa BCNF ei välttämättä päde, on resurssien tai aikojen samanaikaisuuteen liittyvissä vaatimuksissa.
Webbikauppa.com-yritys haluaa tarjota isoille yritysasiakkaille mahdollisuuden varata aikoja konsultointiin (esim. hintavertailu, isojen ostosten suunnittelu, yms.). Konsultointi pidetään tiettynä päivänä ja kellonaikana kaupan kivijalkaliikkeessä ja sitä varten varataan huone ja myyjä. Myyjä varaa huoneensa koko päiväksi. Eri päivinä samalla myyjällä voi olla eri huone, sillä huoneet voivat olla varattuja. Asiakkaalle varataan vain yksi konsultointi samalle päivälle, jotta kaikille asiakkaille olisi tilaa.
Konsultointeja varten tietokantaan tulee lisätä taulu, jossa pidetään kirjaa konsultoinnin tiedoista (aika, asiakas, kuka myyjä hoitaa, huone).
Vaatimusten perusteella koodari loi seuraavan taulun:
| käyttäjätunnus | päivä | kellonaika | myyjätunnus | huonenro |
|---|---|---|---|---|
| matti123 | 2025-01-30 | 12:00 | myyjä01 | huone101 |
| matti123 | 2025-02-10 | 12:00 | myyjä02 | huone102 |
| hilda06 | 2025-01-30 | 15:00 | myyjä01 | huone101 |
| asko_96 | 2025-03-01 | 13:00 | myyjä03 | huone100 |
Taulun ja vaatimusten perusteella koodari päätteli seuraavat funktionaaliset riippuvuudet:
{käyttäjätunnus, päivä} -> {kellonaika, myyjätunnus, huonenro}- "Jos tiedetään käyttäjän tunnus ja konsultoinnin päivä, tiedetään konsultoinnin kellonaika, siihen osallistuvan myyjän tunnus ja varattu huone."
- Tämän perusteella
{käyttäjätunnus, päivä}on avainehdokas, se on myös tässä tapauksessa perusavain
{myyjätunnus, päivä, kellonaika} -> {käyttäjätunnus, huonenro}- "Jos tiedetään myyjän tunnus, konsultoinnin päivä ja kellonaika, tiedetään konsultointiin tulevan asiakkaan tunnus ja varattu huone."
- Tämä pätee, sillä myyjä voi olla samaan aikaan vain yhdessä konsultoinnissa
- Huom: tämän perusteella
{myyjätunnus, päivä, kellonaika}on myös avainehdokas
{huonenro, päivä, kellonaika} -> {käyttäjätunnus, myyjätunnus}- "Jos tiedetään konsultoinnin päivä, kellonaika ja huone, tiedetään paikalle tulevan asiakkaan ja myyjän tunnukset."
- Tämä pätee, sillä huoneessa voi olla samaan aikaan vain yksi konsultointi, eli huoneen numerosta, päivästä ja kellonajasta tiedetään, ketkä konsultointiin osallistuvat.
- Huom: tämän perusteella
{huonenro, päivä, kellonaika}on myös avainehdokas
{myyjätunnus, päivä} -> {huonenro}- "Jos tiedetään myyjän tunnus ja päivä, tiedetään, minkä huoneen hän on varannut päiväksi"
- Huom:
{myyjätunnus, päivä}ei ole avainehdokas! Myyjän tunnuksella ja päivällä voidaan vaatimusten perusteella tietää vain myyjän varaaman huoneen numero, muttei sitä, kuka asiakas on tulossa.
Huomaa, että 1NF, 2NF ja 3NF pätevät:
- 1NF on OK, sillä perusavain on valittu, attribuuteilla on selkeä tietotyyppi eikä moniarvoisia attribuutteja ole.
- 2NF on OK, sillä riippuvuus
{käyttäjätunnus, päivä} -> {kellonaika, myyjätunnus, huonenro}on täysi.kellonaikariippuu täysin perusavaimesta{käyttäjätunnus, päivä}eikä vain sen osasta; ilman käyttäjätunnusta tai päivää ei tiedetä yksikäsitteisesti, mihin aikaan konsultointi voisi ollamyyjätunnusriippuu täysin perusavaimesta{käyttäjätunnus, päivä}eikä vain sen osasta; ilman käyttäjätunnusta tai päivää ei tiedetä, mikä myyjä osallistuu konsultointiinhuonenroriippuu täysin perusavaimesta{käyttäjätunnus, päivä}eikä vain sen osasta; ilman käyttäjätunnusta tai päivää ei tiedetä, missä huoneessa konsultointi on
- 3NF on OK, koska taulun jokainen attribuutti kuuluu johonkin taulun avainehdokkaaseen. Siispä kaikkien yllä olevien funktionaalisten riippuvuuksien määräävät joukot sisältävät vain avainehdokasattribuutteja. Erityisesti
{myyjätunnus, päivä} -> {huonenro}on OK, sillämyyjätunnusjapäiväkuuluvat avainehdokkaaseen{myyjätunnus, päivä, kellonaika}.
Nyt kuitenkin BCNF vaatii, että jokaisen attribuutin tulee riippua vain ja ainoastaan relaation kokonaisista avainehdokkaista eikä vain avainehdokkaiden osista. Funktionaaliselle riippuvuudelle {myyjätunnus, päivä} -> {huonenro} näin ei päde, sillä {myyjätunnus, päivä} ei ole avainehdokas.
Ratkaisuna on siirtää rikkova funktionaalinen riippuvuus omaksi taulukseen. Lopuksi siis päädytään tauluun KONSULTOINTI_VARAUS, joka kertoo varatun konsultoinnin ajan ja myyjän:
| käyttäjätunnus | päivä | kellonaika | myyjätunnus |
|---|---|---|---|
| matti123 | 2025-01-30 | 12:00 | myyjä01 |
| matti123 | 2025-02-10 | 12:00 | myyjä01 |
| hilda06 | 2025-01-30 | 15:00 | myyjä02 |
| asko_96 | 2025-03-01 | 13:00 | myyjä03 |
Lisäksi funktionaaliselle riippuvuudelle {myyjätunnus, päivä} -> {huonenro} tehdään taulu HUONE_VARAUS, joka kertoo, minkä huoneen myyjä varasi itselleen päiväksi:
| myyjätunnus | päivä | huonenro |
|---|---|---|
| myyjä01 | 2025-01-30 | huone101 |
| myyjä01 | 2025-02-10 | huone102 |
| myyjä02 | 2025-01-30 | huone101 |
| myyjä03 | 2025-03-01 | huone100 |
Neljäs normaalimuoto
Yleensä BCNF riittää hyvin normalisointiin. Tietyille tauluille, jotka mallintavat moniarvoista dataa, funktionaalisen riippuvuuden määritelmä ei riitä tunnistamaan poikkeamia.
Esimerkki
Katsotaan viimeistä kertaa Webbikauppa.com-yrityksen tietokantaa.
Webbikauppa.com haluaa alkaa myydä omia valmiiksi rakennettuja pöytätietokoneita. Pöytätietokoneista tarjotaan erilaisia malleja, ja jokaisella mallilla on joukko muokattavia ominaisuuksia, kuten keskusmuistin määrä, prosessorin malli ja näytönohjaimen malli. Tietokantaan haluttaisiin mallintaa, mitä ominaisuuksia on tarjolla eri malleille.
Vaatimuksen perusteella tehtiin taulu PC_MALLI_VERSIOT:
| malli | keskusmuisti | prosessorimalli | näytönohjainmalli |
|---|---|---|---|
| Palikka | 4 GB | AMD Ryzen 3 | NVIDIA GeForce GTX 1080 |
| Palikka | 8 GB | AMD Ryzen 3 | NVIDIA GeForce GTX 1080 |
| Palikka | 4 GB | AMD Ryzen 5 | NVIDIA GeForce GTX 1080 |
| Palikka | 8 GB | AMD Ryzen 5 | NVIDIA GeForce GTX 1080 |
| Palikka | 4 GB | AMD Ryzen 3 | NVIDIA GeForce RTX 2060 |
| Palikka | 8 GB | AMD Ryzen 3 | NVIDIA GeForce RTX 2060 |
| Palikka | 4 GB | AMD Ryzen 5 | NVIDIA GeForce RTX 2060 |
| Palikka | 8 GB | AMD Ryzen 5 | NVIDIA GeForce RTX 2060 |
| Möykky | 32 GB | Intel Core i7 | NVIDIA GeForce GTX 1080 |
| Möykky | 64 GB | Intel Core i7 | NVIDIA GeForce GTX 1080 |
| Möykky | 32 GB | Intel Core i9 | NVIDIA GeForce GTX 1080 |
| Möykky | 64 GB | Intel Core i9 | NVIDIA GeForce GTX 1080 |
| Möykky | 32 GB | Intel Core i7 | NVIDIA GeForce RTX 2060 |
| Möykky | 64 GB | Intel Core i7 | NVIDIA GeForce RTX 2060 |
| Möykky | 32 GB | Intel Core i9 | NVIDIA GeForce RTX 2060 |
| Möykky | 64 GB | Intel Core i9 | NVIDIA GeForce RTX 2060 |
Taulun perusteella tarjolla on kaksi PC-mallia: Palikka ja Möykky. Jokaisella mallilla on kaksi eri keskusmuisti-, prosessori- ja näytönohjainvaihtoehtoa.
Huomaa, että perusavaimessa on kaikki sarakkeet {malli, keskusmuisti, prosessorimalli, näytönohjainmalli}. Funktionaalisia riippuvuuksia ei tässä ole, sillä mikään sarake ei yksilöi mitään toista saraketta: mallilla voi olla monta eri ominaisuusvaihtoehtoa, ja yksittäinen ominaisuus (esim. prosessorin malli) voi olla käytössä eri malleilla.
Funktionaalisia riippuvuuksia ei ole, eikä siis ole mitään, mikä rikkoisi BCNF:n vaatimuksia.
Harjoittele
Katsele yllä olevaa taulua ja mallidataa. Pohdi, millaisia poikkeamia tai mahdollista toisteisuutta voi syntyä. Muista, että poikkeama on tiedon lisäyksestä, muokkauksesta tai poistosta johtuva syntyvä ristiriita taulun tiedoissa.
Mitä muita mahdollisia ongelmia voi syntyä, kun yllä olevaa taulua yrittää käyttää?
Kun olet pohtinut asiaa, voit lukea selityksen alla:
Taulussa on toisteisuutta, mutta perusavaimen valinnan takia sitä ei voida välttää. Kuten todettiin, funktionaalisia riippuvuuksia ei ole, mutta taulu on silti mahdollista pilata huolimattomuudella:
Mahdollisia poikkeamia:
- Jos nyt Palikka-mallille haluttaisiin lisätä suuremman keskusmuistivaihtoehdon (esim. 16 GB), pitäisi lisätä peräti 8 riviä jokaiselle prosessori- ja näytönohjainvaihtoehdolle, jotka ovat nyt tarjolla Palikka-mallille. Jos yhden vaihtoehdon unohtaa lisätä, jäädään ristiriitaiseen tilaan, jossa 16 GB:n mallille ei ole tarjolla kaikkia prosessori- ja näytönohjainvaihtoehtoja.
Muuta:
- Toisteisuus on erittäin suuri! Jokaiselle uudelle ominaisuudelle pitäisi lisätä niin monta riviä, että kaikki mahdolliset yhdistelmät saa lueteltua.
Yllä olevassa esimerkissä sarakkeilla ei ole funktionaalisia riippuvuuksia. Voidaanko silti jotain sanoa siitä, miten sarakkeet liittyvät toisiinsa? Esimerkkitaulusta voidaan todeta, että:
- Palikka-mallilla on vain tasan kaksi keskusmuistivaihtoehtoa: 4 GB tai 8 GB. Keskusmuistivaihtoehdot eivät riipu prosessorimallista tai näytönohjainmallista.
- Samoin Möykky-mallilla on tasan kaksi keskusmuistivaihtoehtoa: 32 GB tai 64 GB, eikä sekään riipu prosessorista tai näytönohjaimesta.
- Vastaavasti malleilla on tasan kaksi vaihtoehtoa
prosessorimalli-sarakkeen arvolle, samoinnäytönohjainmalli-sarakkeelle, eivätkä niiden arvot riipu suoraan toisistaan.
Funktionaalisessa riippuvuudessa attribuutti voi yksilöidä jonkun toisen attribuutin yksittäisiä arvoja. Tässä esimerkissä ei ole niin, mutta ollaan lähellä: attribuutti malli yksilöi attribuutin keskusmuisti arvojoukon. Toisin sanoen, jos tiedetään malli, voidaan tietää, mitä keskusmuistin vaihtoehtoja sillä on. Yleistetään tämä huomio määritelmään:
Määritelmä
Jos joukko relaation R attribuutteja X yksilöi jonkun toisen joukon saman relaation attribuuttien Y arvojoukon riippumatta relaation muista attribuuteista, sanotaan, että relaatiossa pätee moniarvoinen riippuvuus {X} ->> {Y}.
Toisin sanoen, jos relaatio sisältää attribuuttijoukot X, Y ja Z, niin jokaisella monikolla, jolla attribuuttijoukon X arvo on a, on attribuuttijoukon Y arvojen joukko aina b riippumatta attribuuttijoukon Z arvoista.
Lisäksi, jos määräävä ja riippuva attribuuttijoukko yhdessä {X, Y} sisältävät relaation kaikki attribuutit, sanotaan, että riippuvuus {X} ->> {Y} on triviaali. Muussa tapauksessa riippuvuus on epätriviaali.
Yllä olevan esimerkin perusteella voidaan siis todeta, että {malli} ->> {keskusmuisti}, {malli} ->> {prosessorimalli} ja {malli} ->> {näytönohjainmalli}. Toisin sanoen, keskusmuistin (tai prosessorimallin tai näytönohjaimen) mahdolliset arvovaihtoehdot riippuvat vain mallista eivätkä mistään muusta attribuutista.
Tämän määritelmän pohjalta voidaan esittää neljännen normaalimuodon vaatimukset:
Määritelmä
Relaatio on 4NF:ssä, jos kaikki seuraavat vaatimukset täyttyvät:
- Relaatio on BCNF:ssä.
- Relaation kaikkien epätriviaalien moniarvoisten riippuvuuksien määräävä attribuuttijoukko tulee olla relaation avainehdokas.
Toisin sanoen, jos relaatiossa on moniarvoinen riippuvuus {X} ->> {Y}, niin attribuuttijoukon X tulee olla relaation avainehdokas.
Huomaa, että 4NF koskee vain epätriviaaleja riippuvuuksia. Tämän johdosta 4NF soveltuu käytännössä vain tauluihin, joissa on enemmän kuin kaksi saraketta. Rajoituksen takia myös binäärisiä N:M-suhteita mallintavat taulut täyttävät 4NF:n.
Käytännössä 4NF voi mennä rikki vain, jos tietokannan suunnitteluvaiheessa samalla taululla yritetään mallintaa montaa N:M-suhdetta samanaikaisesti. Jos transformoinnin suorittaa oikein ja sääntöjen mukaan, taulussa ei pitäisi esiintyä epätriviaaleja moniarvoisia riippuvuuksia lainkaan.
Esimerkki
Normalisoidaan vielä lopuksi esimerkkitaulu. Kuten todettiin, löydettiin seuraavat moniarvoiset riippuvuudet:
{malli} ->> {keskusmuisti}- "Jos tiedetään malli, tiedetään yksikäsitteisesti kaikki keskusmuistivaihtoehdot"
{malli} ->> {prosessorimalli}- "Jos tiedetään malli, tiedetään yksikäsitteisesti kaikki prosessorimallivaihtoehdot"
{malli} ->> {näytönohjainmalli}- "Jos tiedetään malli, tiedetään yksikäsitteisesti kaikki näytönohjainvaihtoehdot"
Kaikki kolme riippuvuutta ovat epätriviaaleja: määräävän ja riippuvan joukon yhdiste ei ole koko taulu.
Lisäksi {malli} ei ole taulun perusavain {malli, keskusmuisti, prosessorimalli, näytönohjainmalli}, joten 4NF ei päde. Ratkaisuna tehdään kullekin riippuvuudelle oma taulu:
MALLI_KESKUSMUISTIT:
| malli | keskusmuisti |
|---|---|
| Palikka | 4 GB |
| Palikka | 8 GB |
| Möykky | 32 GB |
| Möykky | 64 GB |
MALLI_PROSESSORIMALLIT:
| malli | prosessorimalli |
|---|---|
| Palikka | AMD Ryzen 3 |
| Palikka | AMD Ryzen 5 |
| Möykky | Intel Core i7 |
| Möykky | Intel Core i9 |
MALLI_NÄYTÖNOHJAINMALLIT:
| malli | näytönohjainmalli |
|---|---|
| Palikka | NVIDIA GeForce GTX 1080 |
| Palikka | NVIDIA GeForce RTX 2060 |
| Möykky | NVIDIA GeForce GTX 1080 |
| Möykky | NVIDIA GeForce RTX 2060 |
Huomaa erityisesti, että rivien määrä on saatu vähennettyä: alkuperäisestä 16 rivistä on saatu 12 riviä. Lisäksi nyt malleille on nyt helpompaa lisätä uusia ominaisuuksia: uuden näytönohjainvaihtoehdon lisäys tarkoittaa vain parin rivin lisäämistä tauluun.
Loppusanat normalisoinnista
Tätä materiaalia varmasti lukee kolme eri selkeää joukkoa: tulevat ohjelmoijat sekä tietokantojen ylläpitäjät, tulevat tutkijat sekä tietokantojen suunnittelijat ja ne, jotka mahdollisesti pysyttelevät kaukana tietokannoista tämän materiaalin jälkeen (toivottavasti ei kuitenkaan tämän materiaalin johdosta).
Ohjelmoijat ja ylläpitäjät: Normalisoinnin tarkastelu voi olla hankalaa, ja se vaatii kohdealueen hyvää ymmärtämistä. Normalisoinnin voisi oikeastaan tiivistää pitkälti kahteen pääsääntöön, joiden perusteella tauluja kannattaa suunnitella:
- Tauluun tulee tallentaa vain kohteeseen välittömästi liittyviä tietoja.
- Esimerkiksi opiskelijan postitoimipaikka on postinumeroon liittyvä tieto, ei opiskelijan. Jos taulu tallentaa eri kohteiden tietoja, se viestii tarpeesta luoda oma taulu.
- Kunkin tiedon päivityksen tulee tapahtua vain yhteen paikkaan.
- Esimerkiksi jos opiskelijalle vaihtuu postinumero ja sen takia pitää päivittää sekä postinumero että postitoimipaikka kahdesta eri sarakkeesta, se viestii tarpeesta luoda oma taulu.
Seuraamalla näitä kahta sääntöä pääsee hyvin pitkälle tietokannan suunnittelussa.
Tutkijat ja suunnittelijat: Käsitteellinen mallintaminen on erittäin kannattavaa. Jos ER-kaavio on tehty kohdealueen tarpeita huomioiden ja transformointi suoritettu oikeaoppisesti, tuloksena on usein 3NF tai jopa BCNF toteuttavia relaatioita.
Mainittakoon, että normaalimuotoja on todellisuudessa muitakin. Jotkin niistä ovat vaativuudeltaan käsiteltyjen normaalimuotojen välissä, mutta useimmat ovat käsiteltyjä normaalimuotoja vahvempia. Erityisesti viides normaalimuoto vaatisi formaalimpaa tarkastelua.
Normalisointi on pyritty tässä luvussa esittämään mahdollisimman yksinkertaisesti menemättä liian formaaleihin määritelmiin. Tässä luvussa esitellyt määritelmät eivät ole suinkaan virallisia; tarkoista määritelmistä kiinnostuneet voivat jatkaa aiheeseen tutustumista esimerkiksi Elmasrin ja Navathen kirjassa [15].
Muut lukijat: Toivottavasti tämä ei ollut liian raskas luku 😅. Olennaisin asia, joka pitäisi jäädä mieleen, on, että taulujen rakenteella voidaan vaikuttaa tietokannan helppokäyttöisyyteen sekä "idioottivarmuuteen". Toisaalta, mitä enemmän tietoja jaetaan eri tauluihin, sitä hitaampia tietokantakyselyt ovat. Lisäksi nykyisissä tietokannanhallintajärjestelmissä normalisointi 2NF:n yli voi jopa lisätä levytilan käyttöä [36]. Niinpä voidaan todeta, että oikeastaan normalisointi ei ole aina edes kannattavaa. Nykyään tallennustila on varsin halpaa, ja käyttäjät haluavat yhä nopeampia sovelluksia. Siinä mielessä voi olla perusteltua lisätä hieman toisteisuutta dataan, jos se vähentää tietokantakyselyiden määrää ja monimutkaisuutta. Puhutaankin jopa tietokantojen denormalisoinnista: tauluja jätetään normalisoimatta tai muutetaan alempaan normaalimuotoon, jotta kyselyt olisivat nopeampia.
These are the current permissions for this document; please modify if needed. You can always modify these permissions from the manage page.