English version of the materials are work in progress!
Expect bugs, typos, and other issues. The English version is expected to be completed during spring 2026.
Data Manipulation Language (DML)
Data Manipulation Language (DML) forms a large part of the SQL language. With it, data can be e.g. searched SELECT, inserted INSERT, updated UPDATE and deleted DELETE from the database. In other words, CRUD operations (Create, Read, Update, Delete) can be targeted at the database with DML language.
Next, these four commands are examined.
Example Database
The following sections contain interactive examples. You can try running pre-written SQL statements and you can also modify them. The database management system used in the material is SQLite, which is suitable for maintaining local databases integrated into an application.
Start by testing the functionality of the database with the interactive task below. By pressing the example's Run button, the example database is loaded and the names of all tables in the database are shown as output.
Below is the logical structure (also called schema) of the database used in the interactive examples.
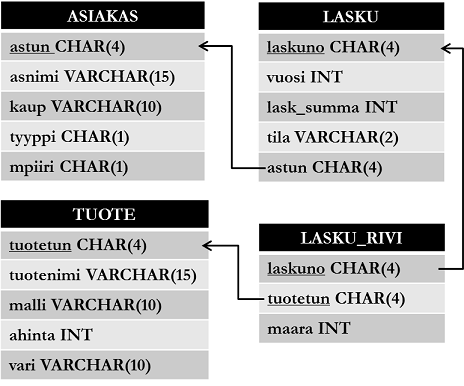
You can view the code used to create the database here: Open example database SQL source code in new tab
There are four tables in the database: asiakas (customer), tuote (product), lasku (invoice) and lasku_rivi (invoice_line). In the schema above, the table name is shown on the first row of the rectangle and the table's column names with their data types on the following ones. Foreign keys are shown with lines. Each table row represents the following information:
- Customer has a unique ID (
astun), name (asnimi), city of residence (kaup), customer type (tyyppi; 'y' = corporate customer, 'h' = private customer) and sales district (mpiiri; 'i' = east, 'l' = west, 'e' = south, 'p' = north, 'k' = central). - Product has an ID (
tuotetun), name (tuotenimi), model (malli), unit price (ahinta) and color (vari). - Invoice has an invoice number (
laskuno), billing year (vuosi), total sum of invoice (lask_summa), status (tila; 'm' = paid, 'l' = billed, 'k' = reminded) and customer who has been billed (astun). - Table
invoice_linedescribes which product (tuotetun) has been billed on which invoice (laskuno) and how many pieces (maara).
Syntax Notations
In this and following chapters, the syntax of the SQL language is introduced as a kind of pseudo-language, where it is marked up which parts of the syntax are mandatory, which are not, and which parts can be repeated multiple times.
Notations used and their meanings:
| notation | meaning | example |
|---|---|---|
SELECT column |
This part must be found in the query. | SELECT astun |
[WHERE condition]? or [WHERE condition] |
Part inside brackets [ ] is not mandatory (i.e. can occur 0..1 times). |
WHERE astun > 0 or it is not found in the query. |
[, column]* |
Part inside brackets [ ] can be repeated 0..n times in succession. |
, asnimi; , kaup, tyyppi |
[ ASC | DESC] |
Either of the parts is allowed. | ASC or DESC |
Query Statements Targeting One Table
Let's first examine query statements targeting one table, the general forms of a query statement, and different conditional expressions.
General Form of a Query Statement
An SQL query statement, i.e., a SELECT statement, consists in its simplest form as follows:
In the SELECT part, the columns whose values are wanted in the query result are listed in a comma-separated list. The first listed column becomes the leftmost column of the result table (i.e., the table obtained as a result of the SQL query), the second listed becomes the second from the left, etc. In the FROM part, the tables from which information is searched are listed in a comma-separated list. The content of the FROM part is also called the table declaration.
In the SELECT part, instead of column names, an asterisk * can be used to describe all columns of the table as in the example below.
Conditional Expressions and Limiting Results
The general form of the query statement SELECT...FROM...; retrieves all rows from the table. When results are wanted to be limited, conditional expressions are used, which are placed in the WHERE part of the statement. The WHERE part is placed after the FROM part:
Comparison Operators
Conditional expressions often consist of comparing column values. Commonly recognized comparison operators in SQL language are:
| operator | explanation | example |
|---|---|---|
= |
Equal to, same as. | vuosi = 2025 |
<, <= |
Less than, less than or equal to. | ahinta < 5 |
>, >= |
Greater than, greater than or equal to. | ahinta >= 5 |
<> or != |
Not equal to, different from. | vuosi != 2025, vuosi <> 2025 |
Note that in SQL language there are two different notations for inequality: <> and !=.
Multiple conditional expressions can be combined with logical operators AND and OR and further with parentheses. If only AND operators are used in the WHERE part, the order of conditional expressions does not matter for the results.
Comparing Strings
Comparison operators or the [NOT] LIKE predicate can be used for comparing strings. The string to be compared is written inside single quotes '. Case sensitivity inside single quotes usually matters, however depending on the product and its settings. In SQLite, case sensitivity does not matter by default.
Huomautus
Unlike in ordinary programming languages, in SQL language strings are written inside single quotes ' and not double quotes ".
It is worth mentioning that the meaning of quotes in SQL language depends somewhat on the database management system. For example, in SQLite strings can be written inside both single quotes ' and double quotes " (though this can cause problems). On the other hand, for example in PostgreSQL, double quotes are used to refer to database objects.
When using the LIKE predicate, the following wildcards can additionally be used:
- Underscore
_corresponds to any single character. - Percent sign
%corresponds to 0..n pieces of any character. That is, percent sign corresponds to any string (also empty).
Harjoittele
Try changing the SQL query above so that it searches for names of all customers starting with K and L, whose name however does not end in string Oy.
Order of Execution of Logical Operators
Like arithmetic operations, some operators in SQL are more privileged than others. For example, where multiplication is calculated before sum, in SQL AND is checked before the OR operator. If OR is desired to be checked before the AND operator, the execution order of the statement can be controlled with parentheses like in mathematics, i.e., things inside parentheses are executed first. Let's examine the following example:
In the statement above, the execution order is controlled with parentheses: first it is checked that the product name is one of the desired ones (OR), and then whether the price is one of the desired ones (OR). Finally, it is checked that both name and price conditions apply (AND).
In summary, the execution order of logical operators follows the following order:
- From left to right (or top to bottom).
- Operators in parentheses first.
ANDOR
If parentheses were not used, the logic of the statement would change in the following ways:
If all parentheses are left out, the SQL query condition would be interpreted in the following order (brackets
[ ]added to highlight execution order):In other words, products whose name starts with letter t are accepted. Also products whose name starts with letter s and whose price is over 200 are accepted. Also products whose price is under 20 are accepted.
If only lower parentheses i.e. parentheses surrounding price checks are left out, the SQL query condition would be interpreted in the following order (brackets
[ ]added to highlight execution order):I.e., products whose name starts with letter t or s and whose price is over 200 are accepted. Also products whose price is under 20 are accepted.
If only upper parentheses i.e. parentheses surrounding product name checks are left out, the SQL query condition would be interpreted in the following order (brackets
[ ]added to highlight execution order):Then products whose name starts with letter t are accepted. Also products whose name starts with letter s and whose price is over 200 or under 20 are accepted.
Null Value and Comparison
Null value NULL describes a value that is not known or does not have meaning for the row (see Chapter 3.1). If one tries to compare a null value with comparison operators, a null value is always returned. Until now, conditional expressions have been examined according to two-valued logic, e.g. conditional expression ahinta > 100 returns either value TRUE or FALSE depending on what value is at the intersection of row and column. Due to the null value, SQL works with three-valued logic according to the following truth table.
cond1 |
cond2 |
cond1 AND cond2 |
cond1 OR cond2 |
|---|---|---|---|
TRUE |
TRUE |
TRUE |
TRUE |
TRUE |
FALSE |
FALSE |
TRUE |
FALSE |
FALSE |
FALSE |
FALSE |
TRUE |
NULL |
NULL |
TRUE |
FALSE |
NULL |
FALSE |
NULL |
In SQL, null value is described with keyword NULL. Occurence of null value is checked with predicate IS [NOT] NULL, never with a comparison operator.
Harjoittele
Try changing the condition ahinta IS NULL to comparison operator ahinta = NULL and examine the result.
All comparison operators and arithmetic operators with NULL always give NULL as output (yes, even a = NULL is NULL). If the result of a WHERE condition for a row is NULL, it is interpreted in the same way as FALSE, i.e., the row is not included in the result table.
Other Ways to Compare
In addition to comparison operators and LIKE predicate, the SQL standard has other, depending on situation more effortless ways to compare.
With [NOT] IN predicate it can be checked if a value belongs to some set. It can be used for example to replace a set of OR operators with one operator. For [NOT] IN predicate, an acceptable value set is given inside parentheses as a comma-separated list. Note that using wildcards is not allowed.
Harjoittele
Try changing the example statement to form: "get all information of customers from Kouvola and Mikkeli". Use the IN predicate.
[NOT] BETWEEN predicate checks if column value is in the desired range. Syntax is column BETWEEN value1 AND value2, where value1 is smaller and value2 larger. Using the predicate, strings and dates can also be compared. Note that boundary values are also accepted in results.
Ordering Results
In examples discussed so far, the order of rows in the result table has been decided by the database management system. The result table can be ordered to one's liking with ORDER BY clause. It is placed after the parts discussed so far:
The result table can be ordered by all its columns or only by some columns. If ORDER BY clause is used, column values are ordered by default in ascending order (ASC). The order can be reversed to descending order with additional clause DESC.
Limiting the Number of Results
Sometimes one wants to limit the number of rows retrieved from the database. For example, if one wants to find out if there is even one row satisfying a condition in the database, it is pointless to fetch all possible rows.
The number of rows coming to the result table can be limited with LIMIT clause. LIMIT clause comes at the very end of the query, after all other parts:
LIMIT clause is often well suited with ORDER BY clause when one wants to answer questions of the form "Get N best/highest/longest...".
Query Statements Targeting Multiple Tables
Query statements discussed so far have targeted one table at a time. However, in databases it is common that usually information is fetched from multiple tables in the same search. On the other hand, it is also common that rows of one table are wanted to be selected based on rows in another table.
Esimerkki
Let's return to the schema of the example database:
Possible queries that might satisfy combining information and searching from multiple tables could be:
- "Which customers (customer name) have reminded invoices?"
- Tables
asiakas(fetching customer name) andlasku(fetching customers' reminded invoices) are needed.
- Tables
- "Get names and prices of products bought by customer named
Kajoin year 2014".- Data must be fetched from table
asiakas(fetching customer),lasku(fetching customer's invoices),lasku_rivi(fetching invoice products) andtuote(fetching product names and prices).
- Data must be fetched from table
- "From which sales districts has product 'kellotin' been ordered?"
- Similarly tables
tuote,lasku_rivi,laskuandasiakas(customer hasmpiiri) are needed.
- Similarly tables
The most important concept related to handling more than one table is join condition. With a join condition, it is checked if the same column value is found in two different tables. Usually join conditions are done with a foreign key between the child table's foreign key and the parent table's referenced column (but this is not mandatory, a join can be done between any two columns of two tables). With a join condition, rows in different tables can be "glued" (i.e. joined) together and returned in the result table.
In SQL language there are four ways to implement a join condition:
- Join using
INpredicate - Join using
EXISTSpredicate - Join using comparison operator
- Join with
JOINclause
Of these, ways 1-3 are so-called implicit joins, where the database management system automatically recognizes that rows in different tables need to be joined together. Way 4 is, on the other hand, explicit join, i.e., in the query it is separately requested to join two or more tables together.
Every way has its benefits and challenges. Next, all four ways to join rows in different tables together are gone through.
Join Using IN Predicate
One way to implement a join is with a so-called subquery, where in the WHERE part of the statement, a new query statement starting with SELECT command is started. The join condition can be implemented using IN predicate. Pay attention to which table is declared in which FROM part:
Let's examine more closely what happens in the statement above. In the database's tuote table, information of all products in the database is listed. In the database's lasku_rivi table, on the other hand, product IDs of such products which contain some invoice, i.e., of which some customer has been billed sometime, are listed. In other words, in tuote table all products are stored, but in lasku_rivi table only IDs of billed products.
From IN predicate we remember that it checks if the value of the compared column belongs to some set (see [NOT] IN comparison). Here, heavily to the right of IN predicate, is not placed a comma-separated list of acceptable values, but another search query (so-called subquery). To the left of IN predicate is the value of tuotetun column of tuote table, on the right side on the other hand the value of tuotetun column of lasku_rivi table.
The query could be read like this: "Get product names of products whose product ID is stored also in lasku_rivi table" or "Get product names of products whose product ID appears at least once in lasku_rivi table" or "Get product names of products which have been billed at least once".
How is the statement then executed? The subquery could be thought of as two nested loops in an imperative programming language:
- Select value
xoftuotetuncolumn from the first row oftuotetable. - Compare
xto valueyoftuotetuncolumn of the first row oflasku_rivitable.- If conditional expression
x = ygets valueTRUE(i.e. values are same), put the value oftuotenimicolumn of the row corresponding toxintuotetable to the result table. Move to point 3. - If conditional expression
x = ygets some other value (FALSEorNULL), check thetuotetunvalue of the next row oflasku_rivitable, and compare it tox. If a value corresponding toxis not found from any row oflasku_rivitable, move to point 3.
- If conditional expression
- Select value
xoftuotetuncolumn from the next row oftuotetable and move to point 2, until even the last row oftuotetable has been checked. - Return result table as the result of the query.
According to the same principle, even more complex queries can be implemented. For example, the search statement presented below in natural language may look complex presented in SQL depending on the database structure:
The statement above could be read open as follows.
"Get names and types of such customers,":
"...whose customer ID is stored also in lasku table,":
"...and the laskuno column value of the corresponding lasku table row is stored also in lasku_rivi table,":
"...and the tuotetun column value of the corresponding lasku_rivi table row is stored also in tuote table,":
"...and in tuote table the product color of the corresponding row is black":
Huomautus
How could one start planning a search statement comprising multiple tables?
- First there is reason to examine the database schema and identify those tables from which information is wanted to the result table (in the example above
asiakastable). - Next, find those tables to whose columns conditional expressions must be targeted (in this case
tuotetable). Such conditional expressions are also called content conditions. - Next, examine what other tables are possibly needed so that tables already classified as essential for the query can be joined with join conditions.
- Finally, before writing the actual statement, one must identify with which columns join conditions can be made. For example, in this case
asiakasandtuotetable cannot even in theory be joined directly to each other, as they do not have a single common column. Usually the join is done using foreign keys; arrows in the schema tell between which two tables a join can usually be done and where multiple joins must be done.
Huomautus
Summary of IN join:
INjoin can be thought in everyday language as follows: "Get rows of a table whose certain column values are found in another table's columns".- In
INjoin, joining multiple tables is usually done with nested queries. This can be clear, but on the other hand hinder readability. INjoin is generally suitable for all situations; the database management system decides itself how the join is actually executed.
Join Using EXISTS Predicate
A join based on a subquery can also be done using EXISTS predicate. Syntax differs slightly from IN predicate, as the actual join condition is done only in the subquery's WHERE part. EXISTS predicate checks if rows satisfying conditions exist. If the subquery produces truth value TRUE for even one row, the value of the desired column of the row corresponding to the main query's table is selected to the result table.
A corresponding query implemented with IN predicate would look like this:
Note especially that the actual join happens in a different place than using IN predicate. Subqueries bring along a new concept: scope. Scope means in SQL language where in the statement a name of some column or table can be used. Tables or their columns declared in a subquery cannot be referred to in a higher-level query, but tables and their columns declared in a higher-level query can be referred to in a subquery.
In the example above, the main query is not aware of lasku_rivi table, but the subquery is aware of lasku_rivi table in addition to tuote table declared in the main query.
Scopes and declaring more than one table bring along a problem: when referring to tuotetun column, the database management system does not know whether tuotetun column of tuote or lasku_rivi table is meant. For this reason, correlation names (tarkennin) must be used. As a correlation name, one can use the table name, as above, or one can introduce it oneself in the FROM part of the statement with syntax:
A self-defined correlation name can be any string following naming rules. A self-defined correlation name acts as an alias on the table; with it one can reduce writing work considerably. For example, the example presented above could be written also using own correlation names:
In the main query SELECT part of the example above, using correlation name t is not necessary because tuotenimi named column is only in product table. Because the join condition is done in the subquery's WHERE part, the content of the SELECT part of the subquery implemented with EXISTS predicate does not matter. Usually an asterisk or one number is used.
The statement above can be thought as follows:
"Get names of such products,"
"...for which there exists in table lasku_rivi at least one row,"
", whose tuotetun column has the same value as table tuote's tuotetun column."
Huomautus
Summary of EXISTS join:
EXISTSjoin can be thought in everyday language as follows: "Get rows of a table for which there exists at least one row satisfying the condition from another table.".- In
EXISTSjoin, the actual join condition is done in the subquery. Usually the join condition is of formtable1.col1 = table2.col2. The only practical difference toINjoin is that the join condition is defined in the subquery'sWHEREpart in the same way as other possible specifying conditions. EXISTSjoin is generally suitable for all situations; the database management system decides itself how the join is actually executed.
Join Using Comparison Operator
Joining two or more tables can also be done without a subquery. One way to do a join without a subquery is using a comparison operator.
As in joins using IN and EXISTS predicates presented earlier, the statement above checks whether tuote table tuotetun column value corresponds to some lasku_rivi table tuotetun column value.
Note that unlike in EXISTS and IN joins, in this case all tables to be joined are mentioned in the main query's FROM part without subqueries. Part FROM tuote t, lasku_rivi lr is easiest to think so that the database management system first fetches and joins all possible row alternatives together:

After that part WHERE t.tuotetun = lr.tuotetun leaves in the result only those row alternatives where table tuote tuotetun column value and table lasku_rivi tuotetun column value are same:

From this result table finally only tuotenimi column is returned.
Note that in this way duplicate values can now occur: because in lasku_rivi table the same tuotetun column value can repeat and in this case repeats, the same product is selected to the result table multiple times. In this case duplicate rows can be removed from the result table with DISTINCT additional clause. DISTINCT additional clause is placed in the SELECT part of the statement immediately after SELECT keyword as above.
As in EXISTS and IN joins, also with comparison operators join can be targeted to multiple tables.
The statement above can be thought as follows:
"Get all rows of tables asiakas, lasku, laskurivi and tuote and combine them together in all possible ways;"
"...select from these combined rows those where asiakas table astun and lasku table astun are same,""
"...and lasku table laskuno and lasku_rivi table laskuno same,"
"...and lasku_rivi table tuotetun and tuote table tuotetun same,"
"...and where tuote table vari is black."
Huomautus
Summary of comparison operator join:
- Join can be perfectly thought in everyday language as follows: "Get all rows of tables, glue rows into row pairs, and select those row pairs that have same values in columns."
- In the join, join condition and other conditions are in the same
WHEREpart. Join of multiple tables does not require multiple subqueries, and the result can be easier to read. - Join with comparison operator is well suitable generally for basic situations; database management system usually can implement the join as an inner join.
- Due to the join way, duplicate values can end up in the result table. They must be filtered with
DISTINCTclause if necessary.
Join Using JOIN Clause
JOIN clause is a way to implement joins added in the third version of SQL standard (SQL-92) and extended later. JOIN join is also called explicit join, as it defines precisely how the database management system should implement the join between tables. In this material one common join type, inner join, is examined. Syntax of inner join is the following:
In previous examples, query implemented with IN and EXISTS predicates and using comparison operator would look like following implemented with explicit join:
Inner join can be interpreted largely in the same way as join using comparison operator:
"Get all product names from tuote table,"
"...to which has been first joined lasku_rivi table rows by joining all possible row pairs of tables and selecting from them those where tuote table tuotetun column and lasku_rivi table tuotetun column are equal."
The newest SQL language standard (SQL:2023) defines in addition to inner join as many as five explicit join types:
- Left and right outer join (
LEFT OUTER JOINandRIGHT OUTER JOIN): Joined rows and rows from left/right side table of the join condition that could not be joined with the join condition are taken into the result table. - Outer join (
FULL OUTER JOIN): Union of left and right outer join. In other words returns all joined rows and rows of both tables that could not be joined with the join condition. - Cross join (
CROSS JOIN): Joins all possible row pairs of both tables. Corresponds to same result asFROM table1, table2. - Natural join (
NATURAL JOIN): Database management system tries to automatically join tables based on same-named and same-typed columns.
Details of these joins are left outside this material for now. Interested ones can familiarize themselves with different JOIN joins from following sources: [29], [15].
Huomautus
Summary of JOIN join:
JOINjoin is an explicit join. Query usingJOINjoin can be thought in everyday language as follows: "Combine another table to the table based on join condition, and then execute query for this combined table."- In
JOINjoin, the join condition is presented inONpredicate. - Inner join is usually suitable for basic situations, and with other
JOINjoins the result of the join can be specified. Database management system executes exactly such join as requested. - Due to the join way, duplicate values can end up in the result table. They must be filtered with
DISTINCTclause if necessary.
Union
With union UNION, result tables of two or more query statements can be joined to each other. Union is not actually a join, but a way to combine results of separate queries into the same result table. When union is used, query statements' result tables must have equal amount of columns.
In the previous example, a new SQL keyword AS has also been introduced. With it, e.g. columns of result table can be renamed. In the example above, the only column of the result table has been given name mallit_ja_tuotenimet. AS predicate is useful especially when there are columns produced by aggregate functions in the result table. Aggregate functions are discussed next.
Aggregate Functions
It is possible to perform simple statistical calculations with SQL language. This is often useful when one wants to create reports from data in the database or otherwise analyze information without fetching it to the application in vain. SQL language offers two features for analytics: aggregate functions and grouping.
Aggregate functions (set or aggregate function) are used to perform calculations. They are usually given one parameter and they return one value. Aggregate functions are placed in SELECT or HAVING part of the query statement. HAVING is introduced later. Next, most common aggregate functions sum, count, minimum, maximum, and average are introduced.
Sum and Count
Aggregate function sum SUM calculates and returns the sum of values appearing in the column. SUM treats null value NULL like zero, i.e. 1 + 0 + 3 = 4 and 1 + NULL + 3 = 4. In the following example, ahinta column of tuote table is given as parameter to the aggregate function, and the only column of the result table is named with AS predicate. If the column is not named with AS predicate, the database management system automatically gives the column some name.
Aggregate function count COUNT calculates and returns the number of values or rows. COUNT does not count null values. If a column name is given as parameter to COUNT function, it counts the number of values in the column. If instead an asterisk * is given as parameter, COUNT counts the number of rows in the result table.
In the following example, the number of rows in asiakas table is calculated using asterisk as parameter of the aggregate function.
Occasionally calculating just the number of occurrences of values does not produce the desired result, because by default COUNT aggregate function counts values regardless of what the value is. If one wants to count the number of different values, DISTINCT additional clause can be used.
The example above calculates in other words the number of different values appearing in kaup column of asiakas table.
Harjoittele
Try running the statement without DISTINCT clause. Why does the result change? What is the result based on?
Minimum, Maximum, and Average
Aggregate function minimum MIN returns the smallest value appearing in the column, aggregate function maximum MAX on the other hand the largest. Values of aggregate functions can also be summed together with ordinary arithmetic operators +, -, / or *. In the following example, the difference of values returned by aggregate functions is calculated.
Aggregate function average AVG calculates the average of column values. Aggregate function AVG calculates sum like SUM aggregate function, count like COUNT aggregate function and returns their quotient.
Grouping
The SQL query of the previous example thus returns the average of all product prices. Often aggregate functions are wanted to be used for more complex calculations, for example calculating product price averages by product color, i.e., average for each color. In this case grouping is needed, which happens with GROUP BY clause:
Columns based on which table rows are grouped are called grouping columns.
According to the example above, the database management system first divides tuote table rows into groups based on vari column values. Each group consists of rows where vari column value is same. For example, rows describing blue products belong to the first group, rows describing red products to the second group etc. Finally, price average is calculated separately for each group and they are returned as result table.
There can be more than one grouping column. Using GROUP BY clause is required if at least one result table column is formed with an aggregate function, and at least one column without an aggregate function. In this case grouping must be done according to every grouping column. GROUP BY clause is placed in SQL query statement immediately after the statement's WHERE part. The general syntax of SQL query statement looks thus far as follows:
Harjoittele
Try changing the SQL query statement so that it retrieves the sum of product unit prices by color and model. Exclude products whose price has not been defined. The results are ordered first by color and then by model in descending alphabetical order.
Limiting Results of Grouping
Occasionally grouped results must be limited. WHERE part is executed before grouping, and therefore aggregate functions must not be used in WHERE part.
When rows are wanted to be limited in groups or based on aggregate functions, HAVING part can be used. HAVING part is placed in the statement after GROUP BY part, but however before possible ORDER BY part:
HAVING part works seemingly slightly in the same way as previously discussed WHERE part: with conditional expressions placed in it, query results can be limited. HAVING part differs however from WHERE part in following respects:
- Aggregate functions can be placed in
HAVINGpart, unlike inWHEREpart. HAVINGpart is executed only after grouping, whereasWHEREpart is executed before grouping.- Related to previous,
HAVINGpart always requiresGROUP BYpart.
Typical Problems and "Tricks"
SQL language is quite powerful in expressive power, but unfortunately not all search queries are easy to form. Let's examine solutions to typical search problems, which seem simple in natural language.
"Does Not Exist" Query
Occasionally table rows to which referring values are not found in some other table are wanted in results. NOT IN or NOT EXISTS predicate can be used for comparison:
NOT IN predicate checks if main query row value appears in value set returned by subquery. If value appears (i.e. in example above customer's astun is found in set of customer IDs who have invoice in year 2011), NOT IN condition is false, and main query row is not accepted to result table. The statement above could be read also like this: "Get customer IDs and names of such customers whose customer ID is not in invoice table in any such row where invoice year is 2011".
Same query can be implemented also with NOT EXISTS predicate. Operation of NOT EXISTS predicate follows two-valued (TRUE, FALSE) logic, and comparing null value always produces truth value false. Syntax of statements differs similarly as IN and EXISTS predicates:
It is worth noting that does not exist case cannot be presented without subquery, so-called single-level.
Below is presented a common mistake of handling does not exist case.
The statement above thus does not correspond to requirement "Get customer IDs and names of such customers who have never been billed in year 2011." but to requirement "Get customer IDs and names of such customers who have been billed at least once in some other year than 2011".
Comparing Subquery Results to Constant
Subquery results can be compared to a constant using comparison operator.
The example above could be read like this: "Get invoice numbers of invoices in lasku_rivi table, for which product ID of concerning product is found also in product table and unit price of this product is under 10 euros."
Harjoittele
Ponder, could the previous query be written without comparison based on subquery results.
In the following example constant 2 is compared to subquery results. Subquery result is a number returned by aggregate function.
Database management system could execute the example statement above in following way.
- Select first row of
asiakastableasiakas1. - Select first row of
laskutablelasku1. - Compare
astuncolumn values oflasku1andasiakas1to each other.- If conditional expression
a.astun = l.astungets value true, increment count calculated by aggregate function by one and move to compareasiakas1'sastuncolumn value toastuncolumn value of next row oflasku1. - If conditional expression gets value false or unknown, move to compare
asiakas1'sastuncolumn value toastuncolumn value of next row oflasku1. - When
astuncolumn value ofasiakas1row has been compared to values ofastuncolumn of alllaskutable rows, move to point 4.
- If conditional expression
- Check conditional expression, on left side of which is constant 2 and on right side integer returned by aggregate function
COUNT.- If conditional expression is true, accept desired columns of
asiakas1row (i.e.asnimi,kaup) to result table. - If conditional expression is false, reject
asiakas1row.
- If conditional expression is true, accept desired columns of
- Select next row of
asiakastable to be examined.- If there are rows unexamined in
asiakastable, move to point 2. - If there are no rows unexamined in
asiakastable, move to point 6.
- If there are rows unexamined in
- Return result table.
Subquery results can also be compared to a column. In the following example subquery results are compared to column ahinta.
Multiple Passes of Same Table
Pass means in this context declaring table in FROM part of search statement. If table is wanted to be checked more often than once, one must use help of either scopes enabled by subqueries or multiple correlation names.
Database management system could execute the search statement above e.g. in following way:
- Execute subquery:
SELECT mpiiri FROM asiakas WHERE asnimi = 'Kajo'. This produces set of those sales districts where 'Kajo' operates. - Go through
asiakastable of main query row by row. - Check two conditions for each row:
- Is the value of row's
asnimicolumn different than 'Kajo'? - Does value of row's
mpiiricolumn belong to set of sales districts obtained as result of subquery in phase 1?
- Is the value of row's
- If both conditions (3a and 3b) are true, select values of
asnimiandmpiiricolumns of said row to result table. - Return result table.
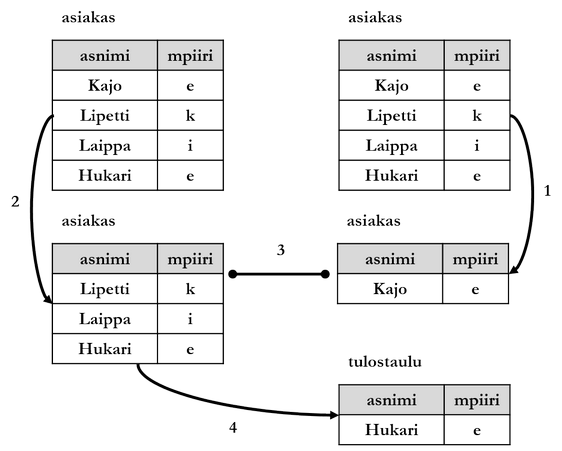
Same can be achieved also with single-level solution using different correlation names for different passes. In example below correlation name a1 corresponds to main query of example above and correlation name a2 to subquery:
"Find X with all Y" Case
Sometimes cases can arise where one wants to identify if value of column forming join condition is found from every row of table on other side of join. General examples of such problems are:
- Get customers who have ordered all diesel-model products.
- Get such invoices where all products have been ordered.
- Get products which all customers have ordered.
Such problem can be solved either with NOT EXISTS predicate or with help of aggregate functions. Below is presented a provenly clearer and performance-wise more stable alternative using aggregate functions [26].
The query above compares by invoice number the number of rows in lasku_rivi table (i.e. number of different product IDs concerning invoice) to number of all products.
Inserting Table Rows
A table row is inserted with INSERT command. Command inserts a row or rows into one table. Syntax of command is:
In the example below a new row is inserted into customer table. Column names of the row are listed in INTO part, and values of the new row's columns are defined in VALUES part. Column names can be listed in any order, but VALUES part list values are set in the order column names are listed in INTO part.
Huomautus
If insertion (or modification or deletion) succeeds, SQLite does not give any result table.
In material examples you can verify row insertion e.g. by executing SELECT query immediately after modification action, for example:
Note that commands are run immediately one after another. In material examples database is initialized after every run.
Columns can be left out from listing of column names. In this case database management system sets null value, default value or some pre-determined value as value of unlisted columns. VALUES part list must have as many values as there are columns listed in INTO part. As an exception to this rule listing of column names can be left out completely, in which case VALUES part list must have as many values as there are columns in the table. Values are listed in this case in the order columns are in the table.
A value can be given to a column also based on subquery results. Subquery must then return only one value, which can also be null value. Insertion statement syntax changes in this case so that in VALUES list instead of value a subquery is given:
In some database management systems (e.g. PostgreSQL) multiple rows can be inserted with one INSERT statement according to following syntax:
Table rows can also be inserted from another table, i.e. new rows can be based on data stored earlier in database. In this case syntax of command is following:
Also in this case it is reason to note that INTO part must list equal amount of columns as are selected from source table in SELECT part. Any complex conditions can be set to search statement: column value checks, subqueries, aggregate functions etc.
Huomautus
How database management system copes with situation where data types between target and source table differ depends on product. In some products insertion is not allowed if data type, character encoding or column size differ, whereas some products try insertion e.g. by cutting strings or making type conversions.
Modifying Table Rows
One table's column values can be changed with command UPDATE. Syntax of command is:
In SET part it is determined values of which columns are modified and how, and in WHERE part it is determined for which rows column values are modified.
Huomautus
Some database management systems do not allow using self-defined correlation names in UPDATE and DELETE statements.
A subquery can also be set into the expression. In the following, price of products whose color has not been defined is set to same as cheapest product price. Any complex conditions can be set in SET part subquery or WHERE part.
Deleting Table Rows
Rows can be deleted from a table with command DELETE. Like INSERT and UPDATE commands, DELETE affects rows of only one table. Syntax of command is:
For example:
Any complex conditions can be set in WHERE part of the statement. If WHERE part is left out, all rows are deleted. DELETE statement does not strictly speaking delete rows, but sets them to be overwritten. Search statement to table does not show rows deleted with DELETE command, but has to read them anyway.
Datan hallintakieli (DML)
Datan hallintakieli (Data Management Language, DML) muodostaa suuren osan SQL-kielestä. Sen avulla tietokannasta voidaan mm. etsiä SELECT, lisätä INSERT, muokata UPDATE ja poistaa DELETE dataa. Toisin sanoin DML-kielellä tietokantaan voi kohdistaa CRUD-operaatioita (Create, Read, Update, Delete).
Seuraavaksi tarkastellaan näitä neljää komentoa.
Esimerkkitietokanta
Seuraavat osiot sisältävät interaktiivisia esimerkkejä. Voit kokeilla ajaa valmiiksi kirjoitettuja SQL-lauseita ja voit myös muokata niitä. Materiaalissa käytettävä tietokannanhallintajärjestelmä on SQLite, joka sopii paikallisten, sovellukseen integroitujen, tietokantojen ylläpitoon.
Kokeile alkuun tietokannan toimivuutta alla olevalla interaktiivisella tehtävällä. Painamalla esimerkin Aja-painiketta esimerkkitietokanta ladataan ja tulosteena näytetään kaikkien tietokannassa olevien taulujen nimet.
Alla on esitetty interaktiivisissa esimerkeissä käytetyn tietokannan looginen rakenne (myös nimeltään kaava tai skeema).
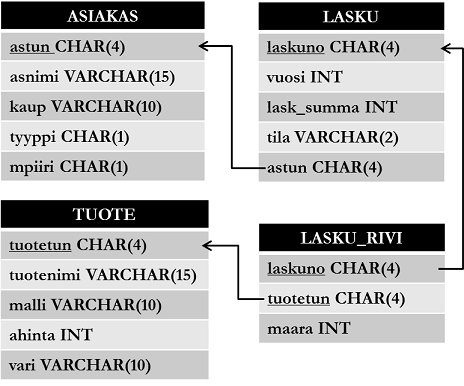
Voit tarkastella tietokannan luomiseksi käytettyä koodia tästä: Avaa esimerkkitietokannan SQL-lähdekoodi uudessa välilehdessä
Tietokannassa on neljä taulua: asiakas, tuote, lasku ja lasku_rivi. Yllä olevassa kaavassa taulujen nimi on esitetty suorakulmion ensimmäisellä rivillä ja taulun sarakkeiden nimet tietotyyppeineen seuraavilla. Viiteavaimet on esitetty viivoilla. Kunkin taulun rivi kuvastaa seuraavaa tietoa:
- Asiakkaalla on yksilöllinen tunnus (
astun), nimi (asnimi), asuinkaupunki (kaup), asiakkuuden tyyppi (tyyppi; 'y' = yritysasiakas, 'h' = henkilöasiakas) ja myyntipiiri (mpiiri; 'i' = itä, 'l' = länsi, 'e' = etelä, 'p' = pohjoinen, 'k' = keski). - Tuotteella on tunnus (
tuotetun), nimi (tuotenimi), malli (malli), yksikköhinta (ahinta) ja väri (vari). - Laskulla on laskunumero (
laskuno), laskutusvuosi (vuosi), laskun yhteissumma (lask_summa), tila (tila; 'm' = maksettu, 'l' = laskutettu, 'k' = karhuttu) sekä asiakas, jota on laskutettu (astun). - Taulu
lasku_rivikuvaa, mitä tuotetta (tuotetun) on laskutettu milläkin laskulla (laskuno) ja kuinka monta kappaletta (maara).
Syntaksimerkinnät
Tässä ja seuraavissa luvuissa SQL-kielen syntaksia esitellään eräänlaisena pseudokielenä, johon on merkitty ylös, mitkä syntaksin osat ovat pakollisia, mitkä eivät ole, ja mitkä osat voidaan toistaa useita kertoja.
Käytettävät merkinnät ja niiden merkitykset:
| merkintä | merkitys | esimerkki |
|---|---|---|
SELECT sarake |
Kyselystä pitää löytyä tämä osa. | SELECT astun |
[WHERE ehto]? tai [WHERE ehto] |
Sulkujen [ ] sisällä oleva osa ei ole pakollinen (eli voi esiintyä 0..1 kertaa). |
WHERE astun > 0 tai sitä ei löydy kyselystä. |
[, sarake]* |
Sulkujen [ ] sisällä oleva osa voi toistua 0..n kertaa peräkkäin. |
, asnimi; , kaup, tyyppi |
[ ASC | DESC] |
Jompikumpi osista on sallittu. | ASC tai DESC |
Yhteen tauluun kohdistuvat hakulauseet
Tarkastellaan ensin yhteen tauluun kohdistuvia hakulauseita, hakulauseen yleisiä muotoja ja erilaisia ehtolausekkeita.
Hakulauseen yleinen muoto
SQL-hakulause eli SELECT-lause muodostuu yksinkertaisimmillaan seuraavasti:
SELECT-osassa luetellaan pilkkulistalla ne sarakkeet, joiden arvoja halutaan kyselyn tulokseen. Tulostauluun (eli tauluun, jonka saadaan SQL-kyselyn tuloksena) ensimmäiseksi luetellusta sarakkeesta tulee tulostaulun vasemmanpuoleisin sarake, toiseksi luetellusta toinen vasemmalta, jne. FROM-osassa luetellaan pilkkulistalla ne taulut, joista tietoa etsitään. FROM-osan sisältöä kutsutaan myös taulujen esittelyksi.
SELECT-osassa voidaan myös sarakkeiden nimien sijaan käyttää tähteä * kuvaamaan taulun kaikkia sarakkeita alla olevan esimerkin mukaisesti.
Ehtolausekkeet ja tulosten rajaus
Hakulauseen yleinen muoto SELECT...FROM...; noutaa taulusta kaikki rivit. Kun tuloksia halutaan rajata, käytetään ehtolausekkeita, jotka sijoitetaan lauseen WHERE-osaan. WHERE-osa sijoittuu FROM-osan jälkeen:
Vertailuoperaattorit
Ehtolausekkeet koostuvat usein sarakkeiden arvojen vertailusta. SQL-kielessä yleisesti tunnistetut vertailuoperaattorit ovat:
| operaattori | selitys | esimerkki |
|---|---|---|
= |
Yhtä suuri kuin, sama kuin. | vuosi = 2025 |
<, <= |
Pienempi kuin, pienempi tai yhtä suuri kuin. | ahinta < 5 |
>, >= |
Suurempi kuin, suurempi tai yhtä suuri kuin. | ahinta >= 5 |
<> tai != |
Erisuuri kuin, eri kuin. | vuosi != 2025, vuosi <> 2025 |
Huomaa, että SQL-kielessä on kaksi eri merkintätapaa erisuuruudelle: <> sekä !=.
Useita ehtolausekkeita voidaan yhdistää toisiinsa loogisilla operaattoreilla AND (ja) ja OR (tai) sekä edelleen sulkeilla. Jos lauseen WHERE-osassa käytetään vain AND-operaattoreita, ehtolausekkeiden järjestyksellä ei ole tulosten kannalta merkitystä.
Merkkijonojen vertailu
Merkkijonojen vertailuun voidaan käyttää vertailuoperaattoreita tai [NOT] LIKE -predikaattia. Vertailtava merkkijono kirjoitetaan heittomerkkien ' sisään. Kirjainkoolla heittomerkkien sisällä on tavallisesti merkitystä, kuitenkin tuotteesta ja sen asetuksista riippuen. SQLite:ssä oletusarvoisesti kirjainkoolla ei ole merkitystä.
Huomautus
Tavallisista ohjelmointikielistä poiketen SQL-kielessä merkkijonot kirjoitetaan heittomerkkien ' eikä lainausmerkkien " sisään.
Mainittakoon, että lainausmerkkien merkitys SQL-kielessä riippuu jonkin verran tietokannanhallintajärjestelmästä. Esimerkiksi SQLite:ssä merkkijonot saa kirjoittaa sekä heittomerkkien ' että lainausmerkkien " sisään (tosin tämä voi aiheuttaa ongelmia). Puolestaan esimerkiksi PostgreSQL:ssä lainausmerkkejä käytetään viittaamaan tietokantaobjekteihin.
LIKE-predikaattia käytettäessä voidaan käyttää lisäksi seuraavia jokerimerkkejä:
- Alaviiva
_vastaa yhtä mitä tahansa merkkiä. - Prosenttimerkki
%vastaa 0..n kappaletta mitä tahansa merkkiä. Ts. prosenttimerkki vastaa mitä tahansa merkkijonoa (myös tyhjää).
Harjoittele
Kokeile muuttaa yllä olevaa SQL-hakulausetta siten, että se hakee kaikkien K:lla ja L:llä alkavien asiakkaiden nimet, joiden nimi ei kuitenkaan lopu merkkijonoon Oy.
Loogisten operaattorien suoritusjärjestys
Kuten aritmeettiset operaatiot, jotkin operaattorit ovat SQL:ssä etuoikeutetumpia kuin toiset. Esimerkiksi siinä missä tulo lasketaan ennen summaa, SQL:ssä AND tarkastetaan ennen OR-operaattoria. Jos halutaan tarkastaa OR ennen AND-operaattoria, lauseen suoritusjärjestystä voidaan ohjata sulkeilla kuten matematiikassa, eli sulkeiden sisällä olevat asiat suoritetaan ensin. Tarkastellaan seuraavaa esimerkkiä:
Yllä olevassa lauseessa suoritusjärjestys on ohjattu sulkeilla: ensin tarkastetaan, että tuotenimi on yksi halutuista (OR), ja sitten onko hinta yksi halutuista (OR). Lopuksi vielä tarkastetaan, että sekä nimen että hinnan ehdot pätevät (AND).
Yhteenvetona, loogisten operaattoreiden suoritusjärjestys seuraa seuraavaa järjestystä:
- Vasemmalta oikealle (tai ylhäältä alas).
- Suluissa olevat operaattorit ensin.
ANDOR
Jos sulkeita ei käytettäisi, muuttuisi lauseen logiikka seuraavilla tavoilla:
Jos jätetään pois kaikki sulkeet, SQL-kyselyn ehto tulkittaisiin seuraavassa järjestyksessä (hakasulkeet
[ ]lisätty korostamaan suoritusjärjestystä):Toisin sanoin hyväksytään sellaiset tuotteet, joiden nimi alkaa t-kirjaimella. Hyväksytään myös sellaiset tuotteet, joiden nimi alkaa s-kirjaimella ja joiden hinta on yli 200. Hyväksytään myös sellaiset tuotteet, joiden hinta on alle 20.
Jos jätetään pois ainoastaan alemmat sulkeet eli hinnan tarkastukset ympäröivät sulkeet, SQL-kyselyn ehto tulkittaisiin seuraavassa järjestyksessä (hakasulkeet
[ ]lisätty korostamaan suoritusjärjestystä):Eli hyväksytään sellaiset tuotteet, joiden nimi alkaa t- tai s-kirjaimella, ja joiden hinta on yli 200. Hyväksytään myös sellaiset tuotteet, joiden hinta on alle 20.
Jos jätetään pois ainoastaan ylemmät sulkeet eli tuotenimen tarkastukset ympäröivät sulkeet, SQL-kyselyn ehto tulkittaisiin seuraavassa järjestyksessä (hakasulkeet
[ ]lisätty korostamaan suoritusjärjestystä):Silloin hyväksytään sellaiset tuotteet, joiden nimi alkaa t-kirjaimella. Hyväksytään myös sellaiset tuotteet, joiden nimi alkaa s-kirjaimella ja joiden hinta on yli 200 tai alle 20.
Tyhjäarvo ja vertailu
Tyhjäarvo NULL kuvastaa arvoa, jota ei tunneta tai jolla ei ole rivin kannalta merkitystä (ks. Luku 3.1). Jos tyhjäarvoa yritetään vertailla vertailuoperaattoreilla, palautetaan aina tyhjäarvo. Tähän asti ehtolausekkeita on tarkasteltu kaksiarvoisen logiikan mukaisesti, esim. ehtolauseke ahinta > 100 palauttaa joko arvon TRUE (tosi) tai FALSE (epätosi) riippuen siitä, mikä arvo rivin ja sarakkeen leikkauskohdassa on. Tyhjäarvon johdosta SQL toimii kolmiarvoisella logiikalla seuraavan totuustaulun mukaisesti.
ehto1 |
ehto2 |
ehto1 AND ehto2 |
ehto1 OR ehto2 |
|---|---|---|---|
TRUE |
TRUE |
TRUE |
TRUE |
TRUE |
FALSE |
FALSE |
TRUE |
FALSE |
FALSE |
FALSE |
FALSE |
TRUE |
NULL |
NULL |
TRUE |
FALSE |
NULL |
FALSE |
NULL |
SQL:ssä tyhjäarvoa kuvataan avainsanalla NULL. Tyhjäarvon esiintymistä tarkastetaan predikaatilla IS [NOT] NULL, ei koskaan vertailuoperaattorilla.
Harjoittele
Kokeile vaihtaa ehto ahinta IS NULL vertailuoperaattoriin ahinta = NULL ja tutki tulosta.
Kaikki vertailuoperaattorit ja laskuoperaattorit NULL:n kanssa antavat tulosteeksi aina NULL (kyllä, jopa a = NULL on NULL). Jos WHERE-ehdon tulos riville on NULL, se tulkitaan samalla tavalla kuin FALSE, eli riviä ei oteta mukaan tulostauluun.
Muita tapoja vertailuun
Vertailuoperaattoreiden ja LIKE-predikaatin lisäksi SQL-standardissa on muita, tilanteesta riippuen vaivattomampia tapoja vertailuun.
[NOT] IN -predikaatilla voidaan tarkastaa, kuuluuko arvo johonkin joukkoon. Sitä voidaan käyttää esimerkiksi korvaamaan joukon OR-operaattoreita yhdellä operaattorilla. [NOT] IN -predikaatille annetaan hyväksyttävä arvojoukko sulkeiden sisällä pilkkulistana. Huomaa, että jokerimerkkien käyttö ei ole sallittua.
Harjoittele
Kokeile muuttaa esimerkkilausetta muotoon: "hae kouvolalaisten ja mikkeliläisten asiakkaiden kaikki tiedot". Käytä IN-predikaattia.
[NOT] BETWEEN -predikaatti tarkastaa, onko sarakkeen arvo halutulla välillä. Syntaksi on sarake BETWEEN arvo1 AND arvo2, jossa arvo1 on pienempi ja arvo2 suurempi. Predikaatilla voidaan vertailla myös merkkijonoja ja päivämääriä. Huomaa, että myös raja-arvot hyväksytään tuloksiin.
Tulosten järjestäminen
Tähän asti käsitellyissä esimerkeissä tulostaulun rivien järjestys on ollut tietokannanhallintajärjestelmän päättämä. Tulostaulun voi järjestää mieleisekseen ORDER BY -määreellä. Se sijoittuu tähän mennessä käsiteltyjen osien jälkeen:
Tulostaulu voidaan järjestää sen kaikkien sarakkeiden mukaan tai vain joidenkin sarakkeiden mukaan. Jos ORDER BY -määrettä käytetään, sarakkeen arvot järjestetään oletusarvoisesti nousevaan järjestykseen (ASC eli ascending). Järjestys voidaan kääntää laskevaan järjestykseen lisämääreellä DESC (descending).
Tulosten määrän rajaaminen
Joskus tietokannasta haettavien rivien määrää halutaan rajata. Esimerkiksi jos halutaan selvittää, löytyykö tietokannasta edes yhtä ehtoa täyttävää riviä, on turhaa hakea kaikkia mahdollisia rivejä.
Tulostauluun tulevien rivien lukumäärä voidaan rajata LIMIT-määreellä. LIMIT-määre tulee aivan kyselyn loppuun, kaikkien muiden osien jälkeen:
LIMIT-määre soveltuu monesti hyvin ORDER BY -määreen kanssa silloin, kun halutaan vastata kysymyksiin mallia "Hae N parasta/korkeinta/pisintä...".
Useaan tauluun kohdistuvat hakulauseet
Tähän mennessä käsitellyt hakulauseet ovat kohdistuneet yhteen tauluun kerrallaan. Tietokannoissa on kuitenkin tavallista, että samassa haussa haetaan tietoa useasta taulusta. Toisaalta on myös yleistä, että yhden taulun rivejä halutaan valita toisessa taulussa olevien rivien perusteella.
Esimerkki
Palataan esimerkkitietokannan skeemaan:
Mahdollisia kyselyjä, jotka saattavat vaatia tietojen yhdistämistä ja hakemista useasta taulusta voisivat olla:
- "Kenellä asiakkailla (asiakkaan nimi) on karhuttuja laskuja?"
- Tarvitaan taulut
asiakas(asiakkaiden nimen hakeminen) jalasku(asiakkaiden karhuttujen laskujen hakeminen).
- Tarvitaan taulut
- "Hae asiakkaan, jonka nimi on
Kajo, vuonna 2014 ostettujen tuotteiden nimet ja hinnat".- Tulee hakea tietoja taulusta
asiakas(asiakkaan hakeminen),lasku(asiakkaan laskujen hakeminen),lasku_rivi(laskun tuotteiden hakeminen) jatuote(tuotteiden nimen ja hinnan hakeminen).
- Tulee hakea tietoja taulusta
- "Mistä myyntipiireistä on tilattu tuotetta 'kellotin'?"
- Vastaavasti tarvitaan taulut
tuote,lasku_rivi,laskujaasiakas(asiakkaalla onmpiiri).
- Vastaavasti tarvitaan taulut
Tärkein useamman kuin yhden taulun käsittelyyn liittyvä käsite on liitosehto. Liitosehdon avulla tarkastetaan, löytyykö kahdesta eri taulusta sama sarakkeen arvo. Yleensä liitosehdot tehdään viiteavaimella renkitaulun viiteavaimen sekä isäntätaulun viitatun sarakkeen välille (mutta tämä ei ole pakollista, vaan liitos voidaan tehdä minkä tahansa kahden taulun sarakkeen välille). Liitosehdon avulla eri tauluissa olevat rivit voidaan "liimata" (eli liittää) yhteen ja ne palauttaa tulostaulussa.
SQL-kielessä on neljä tapaa toteuttaa liitosehto:
- Liitos
IN-predikaattia käyttäen - Liitos
EXISTS-predikaattia käyttäen - Liitos vertailuoperaattoria käyttäen
- Liitos
JOIN-määreellä
Näistä tavat 1-3. ovat ns. implisiittiset liitokset, joissa tietokannanhallintajärjestelmä automaattisesti tunnistaa, että eri tauluissa olevia rivejä tulee liittää yhteen. Tapa 4. on puolestaan eksplisiittinen liitos, eli kyselyssä pyydetään erikseen liittämään kahta tai useampaa taulua yhteen.
Jokaisella tavalla on hyötynsä ja haasteensa. Seuraavaksi käydään läpi kaikki neljä tapaa liittää eri tauluissa olevia rivejä yhteen.
Liitos IN-predikaattia käyttäen
Yksi tapa toteuttaa liitos on ns. alikyselyllä, jolloin lauseen WHERE-osassa aloitetaan uusi, SELECT-käskyllä alkava hakulause. Liitosehto voidaan toteuttaa IN-predikaattia käyttäen. Kiinnitä huomiota siihen, mikä taulu esitellään missäkin FROM-osassa:
Tarkastellaan tarkemmin, mitä yllä olevassa lauseessa tapahtuu. Tietokannan tuote-taulussa on listattuna kaikkien tietokannassa olevien tuotteiden tiedot. Tietokannan lasku_rivi-taulussa on puolestaan listattuna sellaisten tuotteiden tuotetunnukset, joita koskee jokin lasku, eli joista on joskus laskutettu jotakuta asiakasta. Toisin sanoen, tuote-taulussa on tallennettuna kaikki tuotteet, mutta lasku_rivi-taulussa vain laskutettujen tuotteiden tunnuksia.
IN-predikaatista muistamme, että sillä tarkastetaan, kuuluuko vertailtavan sarakkeen arvo johonkin joukkoon (ks. [NOT] IN-vertailu). Tässä IN-predikaatin oikealle puolelle ei olekaan asetettu pilkkulistaa hyväksyttävistä arvoista, vaan toinen hakukysely (ns. alikysely). IN-predikaatin vasemmalla puolella on tuote-taulun tuotetun-sarakkeen arvo, oikealla puolella puolestaan lasku_rivi-taulun tuotetun-sarakkeen arvo.
Kyselyn voisi lukea näin: "Hae sellaisten tuotteiden tuotenimet, joiden tuotetunnus on tallennettu myös lasku_rivi-tauluun" tai "Hae sellaisten tuotteiden tuotenimet, joiden tuotetunnus esiintyy ainakin kerran lasku_rivi-taulussa" tai "Hae sellaisten tuotteiden tuotenimet, joista on laskutettu ainakin kerran".
Miten lause sitten suoritetaan? Alikyselyä voisi ajatella kahtena sisäkkäisenä silmukkana imperatiivisessa ohjelmointikielessä:
- Valitaan
tuote-taulun ensimmäiseltä riviltätuotetun-sarakkeen arvox. - Verrataan
x:äälasku_rivi-taulun ensimmäisen rivintuotetun-sarakkeen arvoony.- Jos ehtolauseke
x = ysaa arvokseenTRUE(ts. arvot ovat samat), sijoitetaantuote-taulunx:ää vastaavan rivintuotenimi-sarakkeen arvo tulostauluun. Siirrytään kohtaan 3. - Jos ehtolauseke
x = ysaa arvokseen jotakin muuta (FALSEtaiNULL), tarkastetaanlasku_rivi-taulun seuraavan rivin sarakkeentuotetun-arvo, ja verrataan sitäx:ään. Joslasku_rivi-taulun miltään riviltä ei löydyx:ää vastaavaa arvoa, siirrytään kohtaan 3.
- Jos ehtolauseke
- Valitaan
tuote-taulun seuraavalta riviltätuotetun-sarakkeen arvoxja siirrytään kohtaan 2., kunnestuote-taulun viimeinenkin rivi on tarkastettu. - Palautetaan tulostaulu kyselyn tuloksena.
Saman periaatteen mukaan voidaan toteuttaa monimutkaisempiakin kyselyitä. Esimerkiksi alla oleva, luonnollisella kielellä esitetty hakulause voi tietokannan rakenteesta riippuen näyttää SQL:llä esitettynä monimutkaiselta:
Yllä olevan lauseen voisi lukea auki seuraavasti.
"Hae sellaisten asiakkaiden nimet ja tyypit,":
"...joiden asiakastunnus on tallennettu myös lasku-tauluun,":
"...ja vastaavan lasku-taulun rivin laskuno-sarakkeen arvo on tallennettu myös lasku_rivi-tauluun,":
"...ja vastaavan lasku_rivi-taulun rivin tuotetun-sarakkeen arvo on tallennettu myös tuote-tauluun,":
"...ja tuote-taulussa vastaavan rivin tuotteen väri on musta":
Huomautus
Miten useaa taulua käsittävää hakulausetta voisi lähteä suunnittelemaan?
- Ensin on syytä tarkastella tietokannan kaavaa ja tunnistaa ne taulut, joista tietoa halutaan tulostauluun (yllä olevassa esimerkissä
asiakas-taulu). - Seuraavaksi etsitään ne taulut, joiden sarakkeisiin täytyy kohdistaa ehtolausekkeita (tässä tapauksessa
tuote-taulu). Tällaisia ehtolausekkeita kutsutaan myös sisällöllisiksi ehdoiksi. - Seuraavaksi tarkastellaan, mitä muita tauluja mahdollisesti tarvitaan, jotta jo kyselyn kannalta olennaisiksi luokitellut taulut voidaan liittää liitosehdoilla.
- Lopuksi ennen varsinaisen lauseen kirjoittamista täytyy tunnistaa, millä sarakkeilla liitosehdot voidaan tehdä. Esimerkiksi tässä tapauksessa
asiakas- jatuote-taulua ei voida edes teoriassa liittää suoraan toisiinsa, sillä niissä ei ole yhtäkään yhteistä saraketta. Yleensä liitos tehdään viiteavainten avulla; skeemassa olevat nuolet kertovat, minkä kahden taulun välillä liitos voidaan yleensä tehdä ja missä tulee tulee tehdä useampi liitos.
Huomautus
Yhteenvetona IN-liitoksesta:
IN-liitos voidaan ajatella arkikielessä seuraavasti: "Hae taulun rivit, jonka tietyn sarakkeen arvot löytyvät toisen taulun sarakkeista".IN-liitoksessa usean taulun liitos yleensä tehdään sisäkkäisillä kyselyillä. Tämä voi olla selkeää, mutta toisaalta haitata luettavuutta.IN-liitos soveltuu yleisesti kaikkiin tilanteisiin; tietokannanhallintajärjestelmä päättää itse, miten liitos varsinaisesti suoritetaan.
Liitos EXISTS-predikaattia käyttäen
Alikyselyyn perustuva liitos voidaan tehdä myös käyttämällä EXISTS-predikaattia. Syntaksi eroaa hieman IN-predikaatista, sillä varsinainen liitosehto tehdään vasta alikyselyn WHERE-osassa. EXISTS-predikaatilla tarkastetaan, onko ehdot täyttäviä rivejä olemassa. Jos alikysely tuottaa totuusarvon TRUE edes yhdelle riville, valitaan pääkyselyn taulusta vastaavan rivin halutun sarakkeen arvo tulostauluun.
Vastaava kysely näyttäisi IN-predikaatilla toteutettuna tältä:
Huomaa erityisesti, että varsinainen liitos tapahtuu eri kohdassa kuin IN-predikaattia käyttäen. Alikyselyt tuovat mukanaan uuden käsitteen: näkyvyysalueen. Näkyvyysalueella tarkoitetaan SQL-kielessä sitä, missä kohdassa lausetta jonkin sarakkeen tai taulun nimeä voidaan käyttää. Alikyselyssä esiteltyihin tauluihin tai niiden sarakkeisiin ei voida viitata ylemmän tason kyselyssä, mutta ylemmän tason kyselyssä esiteltyihin tauluihin ja niiden sarakkeisiin voidaan viitata alikyselyssä.
Yllä olevassa esimerkissä pääkysely ei ole tietoinen lasku_rivi-taulusta, mutta alikysely on tietoinen lasku_rivi-taulun lisäksi pääkyselyssä esitellystä tuote-taulusta.
Näkyvyysalueet ja useamman kuin yhden taulun esittely tuovat mukanaan ongelman: viitattaessa tuotetun-sarakkeeseen tietokannanhallintajärjestelmä ei tiedä, tarkoitetaanko lauseessa tuote- vai lasku_rivi-taulun tuotetun-saraketta. Tästä syystä on käytettävä tarkentimia (correlation name). Tarkentimena voi käyttää taulun nimeä, kuten yllä, tai sen voi esitellä itse lauseen FROM-osassa syntaksilla:
Itse määritelty tarkennin voi olla mikä tahansa nimeämissääntöjä noudattava merkkijono. Itse määritelty tarkennin toimii aliaksena taululla; sillä voi vähentää kirjoitustyötä huomattavasti. Esimerkiksi yllä esitetty esimerkki voitaisiin kirjoittaa myös omia tarkentimia käyttäen:
Yllä olevan esimerkin pääkyselyn SELECT-osassa tarkentimen t käyttö ei ole välttämätöntä, koska tuotenimi-niminen sarake on vain tuote-taulussa. Koska liitosehto tehdään alikyselyn WHERE-osassa, EXISTS-predikaatilla toteutetun alikyselyn SELECT-osan sisällöllä ei ole merkitystä. Tavallisesti käytetään tähtimerkkiä tai yhtä numeroa.
Yllä olevan lauseen voidaan ajatella seuraavasti:
"Hae sellaisten tuotteiden nimet,"
"...joille on olemassa taulussa lasku_rivi ainakin yksi rivi,"
", jonka tuotetun-sarakkeessa on sama arvo kuin taulun tuote tuotetun-sarakkeessa."
Huomautus
Yhteenvetona EXISTS-liitoksesta:
EXISTS-liitosta voi ajatella arkikielessä seuraavasti: "Hae taulun rivit, joille on olemassa ainakin yksi ehtoa täyttävä rivi toisesta taulusta.".EXISTS-liitoksessa varsinainen liitosehto tehdään alikyselyssä. Yleensä liitosehto on muotoataulu1.sarake1 = taulu2.sarake2. Ainoa käytännön eroIN-liitokseen on, että liitosehto määritellään alikyselynWHERE-osaan samalla tavalla kuin muut mahdolliset tarkentavat ehdot.EXISTS-liitos soveltuu yleisesti kaikkiin tilanteisiin; tietokannanhallintajärjestelmä päättää itse, miten liitos varsinaisesti suoritetaan.
Liitos vertailuoperaattoria käyttäen
Kahden tai useamman taulun liitos voidaan tehdä myös ilman alikyselyä. Yksi tapa liitoksen tekemiseen ilman alikyselyä on vertailuoperaattorin käyttäminen.
Kuten aikaisemmin esitellyissä liitoksissa IN- ja EXISTS-predikaatteja käyttäen, yllä olevassa lauseessa tarkastetaan, vastaako tuote-taulun tuotetun-sarakkeen arvo jotakin lasku_rivi-taulun tuotetun-sarakkeen arvoa.
Huomaa, että toisin kuin EXISTS- ja IN-liitoksissa, tässä tapauksessa kaikki liitettävät taulut mainitaan pääkyselyn FROM-osassa ilman alikyselyjä. Osaa FROM tuote t, lasku_rivi lr on helpointa ajatella siten, että tietokannanhallintajärjestelmä ensin hakee ja liittää kaikki mahdolliset rivivaihtoehdot yhteen:

Sen jälkeen osa WHERE t.tuotetun = lr.tuotetun jättää tulokseen vain ne rivivaihtoehdot, jossa taulun tuote tuotetun-sarakkeen arvo ja taulun lasku_rivi tuotetun-sarakkeen arvo ovat samat:

Tästä tulostaulusta lopuksi palautetaan vain tuotenimi-sarake.
Huomaa, että tässä tavassa nyt voi esiintyä toisteisia arvoja: koska lasku_rivi-taulussa sama tuotetun-sarakkeen arvo voi kertautua ja tässä tapauksessa kertautuu, tulostauluun valitaan samaa tuotetta useaan kertaan. Tässä tapauksessa toisteiset rivit voi poistaa tulostaulusta DISTINCT-lisämääreellä. DISTINCT-lisämääre sijoitetaan lauseen SELECT-osaan heti SELECT-avainsanan jälkeen kuten yllä.
Kuten EXISTS- ja IN-liitoksissa, myös vertailuoperaattoreiden kanssa voidaan kohdistaa liitos useaan tauluun.
Yllä olevan lauseen voidaan ajatella seuraavasti:
"Hae taulujen asiakas, lasku, laskurivi ja tuote kaikki rivit ja yhdistä ne yhteen kaikilla mahdollisilla tavoilla;"
"...valitse näistä yhdistetyistä riveistä ne, joilla asiakas-taulun astun ja lasku-taulun astun ovat samat,""
"...ja lasku-taulun laskuno ja lasku_rivi-taulun laskuno samat,"
"...ja lasku_rivi-taulun tuotetun ja tuote-taulun tuotetun samat,"
"...ja joilla tuote-taulun vari on musta."
Huomautus
Yhteenvetona vertailuoperaattoriliitoksesta:
- Liitosta voi ajatella arkikielenä seuraavasti: "Hae taulujen kaikki rivit, liimaa rivit rivipareiksi, ja valitse ne riviparit, joilla on sarakkeissa samat arvot."
- Liitoksessa liitosehto ja muut ehdot ovat samassa
WHERE-osassa. Usean taulun liitos ei vaadi useita alikyselyjä, ja lopputulos voi olla helpompi luettavissa. - Liitos vertailuoperaattorilla soveltuu yleisesti perustilanteisiin; tietokannanhallintajärjestelmä yleensä voi toteuttaa liitoksen sisäliitoksena.
- Liitostavasta johtuen tulostauluun voi joutua toisteisia arvoja. Ne tulee tarvittaessa suodattaa
DISTINCT-määreellä.
Liitos JOIN-määrettä käyttäen
JOIN-määre on SQL-standardin kolmannessa versiossa (SQL-92) lisätty ja myöhemmin laajennettu tapa toteuttaa liitoksia. JOIN-liitosta kutsutaan myös eksplisiittiseksi liitokseksi, sillä se määrittää tarkasti, miten tietokannanhallintajärjestelmän tulee toteuttaa liitos taulujen välille. Tässä materiaalissa tarkastellaan yhtä yleistä liitostyyppiä, sisäliitos (inner join). Sisäliitoksen syntaksi on seuraava:
Aikaisemmissa esimerkeissä IN- ja EXISTS-predikaateilla sekä vertailuoperaattoria käyttämällä toteutettu kysely näyttäisi eksplisiittisellä liitoksella toteutettuna seuraavalta:
Sisäliitoksen voi tulkita pitkälti samalla tavalla kuin liitos vertailuoperaattoria käyttäen:
"Hae kaikki tuotteiden nimet tuote-taulusta,"
"...johon on ensin liitetty lasku_rivi-taulun rivit liittämällä taulujen kaikki mahdolliset riviparit ja valitsemalla niistä ne, joilla on tuote-taulun tuotetun-sarake ja lasku_rivi-taulun tuotetun-sarake ovat samanarvoiset."
Uusin SQL-kielen standardi (SQL:2023) määrittää sisäliitoksen lisäksi peräti viisi eksplisiittistä liitostyyppiä:
- Vasen ja oikea ulkoliitos (
LEFT OUTER JOINjaRIGHT OUTER JOIN): Tulostauluun otetaan liitetyt rivit sekä liitosehdon vasemmalta/oikealta puoleiselta taulusta rivejä, joita ei voitu liittää liitosehdolla. - Ulkoliitos (
FULL OUTER JOIN): Vasemman ja oikean ulkoliitoksen yhdiste. Toisin sanoen palauttaa kaikki liitetyt rivit sekä kummankin taulun rivit, joita ei voitu liittää liitosehdolla. - Ristiliitos (
CROSS JOIN): Liittää kummankin taulun kaikki mahdolliset riviparit. Vastaa samaa tulosta kuinFROM taulu1, taulu2. - Luonnollinen liitos (
NATURAL JOIN): Tietokannanhallintajärjestelmä yrittää automaattisesti liittää taulut samannimisten ja -tyyppisten sarakkeiden perusteella.
Näiden liitosten yksityiskohdat jätetään toistaiseksi tämän materiaalin ulkopuolelle. Kiinnostuneet voivat tutustua erilaisiin JOIN-liitoksiin seuraavista lähteistä: [29], [15].
Huomautus
Yhteenvetona JOIN-liitoksesta:
JOIN-liitos on eksplisiittinen liitos.JOIN-liitosta käyttävää kyselyä voi ajatella arkikielessä seuraavasti: "Yhdistä tauluun toinen taulu liitosehdon perusteella, ja sitten suorita kysely tälle yhdistetylle taulle."JOIN-liitoksessa liitosehto esitetäänON-predikaattissa.- Sisäliitos soveltuu yleensä perustilanteisiin, ja muilla
JOIN-liitoksilla saadaan tarkennettua liitoksen tulosta. Tietokannanhallintajärjestelmä suorittaa juuri sellaisen liitoksen, kuin on pyydetty. - Liitostavasta johtuen tulostauluun voi joutua toisteisia arvoja. Ne tulee tarvittaessa suodattaa
DISTINCT-määreellä.
Yhdiste
Yhdisteen UNION avulla voidaan liittää kahden tai useamman hakulauseen tulostaulut toisiinsa. Yhdiste ei ole varsinaisesti liitos, vaan tapa yhdistää erillisten kyselyiden tulokset samaan tulostauluun. Kun yhdistettä käytetään, hakulauseiden tulostauluissa tulee olla yhtä monta saraketta.
Edellisessä esimerkissä on myös esitelty uusi SQL-avainsana AS. Sen avulla voidaan mm. nimetä uudelleen tulostaulun sarakkeita. Yllä olevassa esimerkissä tulostaulun ainoalle sarakkeelle on annettu nimi mallit_ja_tuotenimet. AS-predikaatti on käyttökelpoinen erityisesti, kun tulostaulussa on koostefunktioiden tuottamia sarakkeita. Koostefunktioita käsitellään seuraavaksi.
Koostefunktiot
SQL-kielellä on mahdollista suorittaa yksinkertaisia tilastollisia laskuja. Tämä on usein hyödyllistä, kun tietokannassa olevasta datasta halutaan luoda raportteja tai muuten analysoida tietoa hakematta sitä turhaan sovellukseen. SQL-kieli tarjoaa kaksi ominaisuutta analytiikalle: koostefunktiot ja ryhmittely.
Koostefunktioita (set tai aggregate function) käytetään laskutoimitusten suorittamiseen. Niille annetaan tavallisesti yksi parametri ja ne palauttavat yhden arvon. Koostefunktiot sijoitetaan hakulauseen SELECT- tai HAVING-osaan. HAVING esitellään myöhemmin. Seuraavaksi esitellään tavallisimmat koostefunktiot summa, lukumäärä, minimi, maksimi ja keskiarvo.
Summa ja lukumäärä
Koostefunktio summa SUM laskee ja palauttaa sarakkeessa esiintyvien arvojen summan. SUM käsittelee tyhjäarvoa NULL kuten nollaa, ts. 1 + 0 + 3 = 4 ja 1 + NULL + 3 = 4. Seuraavassa esimerkissä koostefunktiolle on annettu parametriksi tuote-taulun ahinta-sarake, ja tulostaulun ainoa sarake on nimetty AS-predikaatilla. Jos saraketta ei nimetä AS-predikaatilla, tietokannanhallintajärjestelmä antaa sarakkeelle automaattisesti jonkun nimen.
Koostefunktio lukumäärä COUNT laskee ja palauttaa arvojen tai rivien lukumäärän. COUNT ei laske tyhjäarvoja. Jos COUNT-funktion parametriksi annetaan sarakkeen nimi, laskee se sarakkeessa olevien arvojen lukumäärän. Jos sen sijaan parametriksi annetaan tähti *, COUNT laskee tulostaulussa olevien rivien lukumäärän.
Seuraavassa esimerkissä on laskettu asiakas-taulun rivien lukumäärä käyttämällä koostefunktion parametrina tähteä.
Silloin tällöin pelkkä arvojen esiintymien lukumäärän laskeminen ei tuota haluttua tulosta, sillä oletusarvoisesti COUNT-koostefunktio laskee arvot riippumatta siitä, mikä arvo on. Jos halutaan laskea erilaisten arvojen määrä, voidaan käyttää DISTINCT-lisämäärettä.
Yllä oleva esimerkki laskee toisin sanoen asiakas-taulun kaup-sarakkeessa esiintyvien erilaisten arvojen lukumäärän.
Harjoittele
Kokeile ajaa lause ilman DISTINCT-lisämäärettä. Miksi tulos muuttuu? Mihin tulos perustuu?
Minimi, maksimi ja keskiarvo
Koostefunktio minimi MIN palauttaa sarakkeessa esiintyvän pienimmän arvon, koostefunktio maksimi MAX puolestaan suurimman. Koostefunktioiden arvoja voi myös laskea yhteen tavallisilla laskuoperaattoreilla +, -, / tai *. Seuraavassa esimerkissä on laskettu koostefunktioiden palauttamien arvojen erotus.
Koostefunktio keskiarvo AVG laskee sarakkeen arvojen keskiarvon. Koostefunktio AVG laskee summan kuten SUM-koostefunktio, lukumäärän kuten COUNT-koostefunktio ja palauttaa näiden osamäärän.
Ryhmittely
Edellisen esimerkin SQL-kysely siis palauttaa kaikkien tuotteiden hintojen keskiarvon. Usein koostefunktioita halutaan kuitenkin käyttää monimutkaisempiin laskutoimituksiin, esimerkiksi tuotteiden hintakeskiarvojen laskemiseen tuoteväreittäin, eli keskiarvo jokaista väriä kohden. Tällöin tarvitaan ryhmittelyä, joka tapahtuu GROUP BY -määreellä:
Sarakkeita, joiden perusteella taulun rivit ryhmitellään, kutsutaan ryhmitteleviksi sarakkeiksi.
Yllä olevan esimerkin mukaisesti tietokannanhallintajärjestelmä jakaa ensin tuote-taulun rivit ryhmiksi vari-sarakkeen arvojen perusteella. Kukin ryhmä koostuu riveistä, joiden vari-sarakkeen arvo on sama. Esimerkiksi ensimmäiseen ryhmään kuuluvat rivit, jotka kuvaavat sinisiä tuotteita, toiseen ryhmään rivit, jotka kuvaavat punaisia tuotteita jne. Lopuksi lasketaan hintakeskiarvo erikseen jokaiselle ryhmälle ja palautetaan ne tulostauluna.
Ryhmitteleviä sarakkeita voi olla useampikin kuin yksi. GROUP BY -määreen käyttö vaaditaan, jos ainakin yksi tulostaulun sarake muodostetaan koostefunktiolla, ja ainakin yksi sarake ilman koostefunktiota. Tässä tapauksessa ryhmittely tulee tehdä jokaisen ryhmittelevän sarakkeen mukaisesti. GROUP BY -määre sijoittuu SQL-hakulauseessa heti lauseen WHERE-osan jälkeen. SQL-hakulauseen yleinen syntaksi näyttää siis tähän mennessä seuraavalta:
Harjoittele
Kokeile muuttaa SQL-hakulausetta siten, että se hakeekin tuotteiden yksikköhintojen summan väreittäin ja malleittain. Rajaa pois tuotteista sellaiset, joiden hintaa ei ole määritetty. Tulokset järjestetään ensin värin ja sitten mallin mukaan laskevaan aakkosjärjestykseen.
Ryhmittelyn tulosten rajaaminen
Silloin tällöin ryhmiteltyjä tuloksia täytyy rajata. WHERE-osa suoritetaan ennen ryhmittelyä, eikä WHERE-osassa siksi saa käyttää koostefunktioita.
Silloin kun rivit halutaan rajoittaa ryhmissä tai koostefunktioiden perusteella, voidaan käyttää HAVING-osaa. HAVING-osa sijoittuu lauseessa GROUP BY -osan jälkeen, mutta kuitenkin ennen mahdollista ORDER BY -osaa:
HAVING-osa toimii näennäisesti hieman samalla tavalla kuin aikaisemmin käsitelty WHERE-osa: siihen sijoitettujen ehtolausekkeiden avulla voidaan rajata kyselyn tuloksia. HAVING-osa eroaa kuitenkin WHERE-osasta seuraavilta osin:
HAVING-osaan voidaan sijoittaa koostefunktioita, toisin kuinWHERE-osaan.HAVING-osa suoritetaan vasta ryhmittelyn jälkeen, kun taasWHERE-osa suoritetaan ennen ryhmittelyä.- Edelliseen liittyen,
HAVING-osa vaatii ainaGROUP BY-osan.
Tyypillisiä ongelmia ja "kikkoja"
SQL-kieli on ilmaisuvoimaltaan varsin tehokas, mutta valitettavasti kaikkia hakukyselyjä ei ole helppoa muodostaa. Tarkastellaan siis ratkaisuja tyypillisiin hakuongelmiin, jotka vaikuttavat luonnollisella kielellä yksinkertaisilta.
"Ei ole olemassa" -kysely
Silloin tällöin tuloksiin halutaan taulun sellaiset rivit, joihin viittaavia arvoja ei löydy jostakin muusta taulusta. Vertailuun voidaan käyttää NOT IN- tai NOT EXISTS -predikaattia:
NOT IN-predikaatti tarkastaa, esiintyykö pääkyselyn rivin arvo alikyselyn palauttamassa arvojoukossa. Jos arvo esiintyy (eli yllä olevassa esimerkissä asiakkaan astun löytyy niiden asiakastunnusten joukosta, joilla on lasku vuonna 2011), NOT IN -ehto on epätosi, eikä pääkyselyn riviä hyväksytä tulostauluun. Yllä oleva lause voitaisiin lukea myös näin: "Hae sellaisten asiakkaiden asiakastunnukset ja nimet, joiden asiakastunnus ei ole lasku-taulussa yhdelläkään sellaisella rivillä, jossa laskun vuosi on 2011".
Sama kysely voidaan toteuttaa myös NOT EXISTS-predikaatilla. NOT EXISTS-predikaatin toiminta noudattaa kaksiarvoista (TRUE, FALSE) logiikkaa, ja tyhjäarvon vertailu tuottaa aina totuusarvon epätosi. Lauseiden syntaksi eroaa samoin kuin IN- ja EXISTS-predikaattien:
On syytä huomata, että ei ole olemassa -tapausta ei voida esittää ilman alikyselyä, ns. yksitasoisesti.
Alla on esitetty yleinen virhe ei ole olemassa -tapauksen käsittelystä.
Yllä oleva lause ei siis vastaa vaatimukseen "Hae sellaisten asiakkaiden asiakastunnukset ja nimet, joita ei ole koskaan laskutettu vuonna 2011." vaan vaatimukseen "Hae sellaisten asiakkaiden asiakastunnukset ja nimet, joita on laskutettu ainakin kerran jonakin muuna vuonna kuin 2011".
Alikyselyn tulosten vertailu vakioon
Alikyselyn tuloksia voidaan vertailla vakioon vertailuoperaattoria käyttämällä.
Yllä olevan esimerkin voisi lukea näin: "Hae niiden lasku_rivi-taulun laskujen numerot, joita koskevan tuotteen tuotetunnus löytyy myös tuote-taulusta ja tämän tuotteen yksikköhinta on alle 10 euroa."
Harjoittele
Pohdi, voisiko edellisen kyselyn kirjoittaa ilman alikyselyn tuloksiin perustuvaa vertailua.
Seuraavassa esimerkissä vakiota 2 verrataan alikyselyn tuloksiin. Alikyselyn tulos on koostefunktion palauttama luku.
Tietokannanhallintajärjestelmä voisi suorittaa yllä olevan esimerkkilauseen seuraavalla tavalla.
- Valitaan
asiakas-taulun ensimmäinen riviasiakas1. - Valitaan
lasku-taulun ensimmäinen rivilasku1. - Verrataan
lasku1:n jaasiakas1:nastun-sarakkeen arvoja toisiinsa.- Jos ehtolauseke
a.astun = l.astunsaa arvokseen tosi, kasvatetaan koostefunktion laskemaa lukumäärää yhdellä ja siirrytään vertailemaanasiakas1:nastun-sarakkeen arvoalasku1:n seuraavan rivinastun-sarakkeen arvoon. - Jos ehtolauseke saa arvokseen epätosi tai tuntematon, siirrytään vertailemaan
asiakas1:nastun-sarakkeen arvoalasku1:n seuraavan rivinastun-sarakkeen arvoon. - Kun
asiakas1-rivinastun-sarakkeen arvo on verrattu kaikkiinlasku-taulunastun-sarakkeen arvoihin, siirrytään kohtaan 4.
- Jos ehtolauseke
- Tarkastetaan ehtolauseke, jonka vasemmalla puolella on vakio 2 ja oikealla puolella koostefunktion
COUNTpalauttama kokonaisluku.- Jos ehtolauseke on tosi, hyväksytään
asiakas1-rivin halutut sarakkeet (eliasnimi,kaup) tulostauluun. - Jos ehtolauseke on epätosi, hylätään
asiakas1-rivi.
- Jos ehtolauseke on tosi, hyväksytään
- Valitaan
asiakas-taulun seuraava rivi tarkasteltavaksi.- Jos
asiakas-taulussa on rivejä tarkastelematta, siirrytään kohtaan 2. - Jos
asiakas-taulussa ei ole rivejä tarkastelematta, siirrytään kohtaan 6.
- Jos
- Palautetaan tulostaulu.
Alikyselyn tuloksia voidaan verrata myös sarakkeeseen. Seuraavassa esimerkissä alikyselyn tuloksia verrataan sarakkeeseen ahinta.
Saman taulun usea läpikäynti
Läpikäynnillä tarkoitetaan tässä yhteydessä taulun esittelyä hakulauseen FROM-osassa. Jos taulu halutaan tarkastaa useammin kuin kerran, on käytettävä apuna joko alikyselyiden mahdollistamia näkyvyysalueita tai useita tarkentimia.
Tietokannanhallintajärjestelmä voisi suorittaa yllä olevan hakulauseen esim. seuraavalla tavalla:
- Suoritetaan alikysely:
SELECT mpiiri FROM asiakas WHERE asnimi = 'Kajo'. Tämä tuottaa joukon niitä myyntipiirejä, joissa 'Kajo' toimii. - Käydään läpi pääkyselyn
asiakas-taulu rivi riviltä. - Jokaiselle riville tarkistetaan kaksi ehtoa:
- Onko rivin
asnimi-sarakkeen arvo eri kuin 'Kajo'? - Kuuluuko rivin
mpiiri-sarakkeen arvo vaiheessa 1 alikyselyn tuloksena saatuun myyntipiirien joukkoon?
- Onko rivin
- Jos molemmat ehdot (3a ja 3b) ovat tosia, valitaan kyseisen rivin
asnimi- jampiiri-sarakkeiden arvot tulostauluun. - Palautetaan tulostaulu.
Sama voidaan saavuttaa myös yksitasoisella ratkaisulla käyttämällä eri läpikäynneille eri tarkentimia. Alla olevassa esimerkissä tarkennin a1 vastaa yllä olevan esimerkin pääkyselyä ja tarkennin a2 alikyselyä:
"Etsi X, jolla on kaikki Y" -tapaus
Toisinaan voi tulla tapauksia, joissa halutaan tunnistaa, löytyykö liitosehdon muodostavan sarakkeen arvo liitoksen toisen puolen taulun jokaiselta riviltä. Yleiset esimerkit tällaisista ongelmista ovat:
- Hae asiakkaat, jotka ovat tilanneet kaikki diesel-malliset tuotteet.
- Hae sellaiset laskut, joissa on tilattu kaikkia tuotteita.
- Hae tuotteet, joita kaikki asiakkaat ovat tilanneet.
Tällaista ongelmaa voi ratkaista joko NOT EXISTS-predikaatilla tai koostefunktioiden avulla. Alla esitellään tutkitusti selkeämpi ja suorituskyvyltään tasaisempi vaihtoehto koostefunktioiden avulla [26].
Yllä oleva kysely vertaa laskunumeroittain lasku_rivi-taulun rivien määrää (ts. laskua koskevien erilaisten tuotetunnusten määrää) kaikkien tuotteiden lukumäärään.
Taulurivien lisääminen
Taulurivi lisätään komennolla INSERT. Komento lisää rivin tai rivejä yhteen tauluun. Komennon syntaksi on:
Alla olevassa esimerkissä lisätään tauluun asiakas uusi rivi. Rivin sarakkeiden nimet luetellaan INTO-osassa, ja VALUES-osassa määritetään uudelle riville sen sarakkeiden arvot. Sarakkeiden nimet voidaan luetella missä järjestyksessä tahansa, mutta VALUES-osan listan arvot asetetaan siinä järjestyksessä, kuin sarakkeiden nimet on INTO-osassa lueteltu.
Huomautus
Jos lisäys (tai muokkaus tai poisto) onnistuu, SQLite ei anna mitään tulostaulua.
Materiaalin esimerkeissä voit tarkistaa rivin lisäyksen esimerkiksi suorittamalla SELECT-haku heti muokkaustoiminnon jälkeen, esimerkiksi:
Huomaa, että komennot ajetaan heti peräkkäin. Materiaalin esimerkeissä tietokanta alustetaan jokaisen ajon jälkeen.
Sarakkeiden nimien listauksesta voidaan jättää sarakkeita pois. Tällöin tietokannanhallintajärjestelmä asettaa luettelemattomien sarakkeiden arvoksi tyhjäarvon, oletusarvon tai jonkin ennalta määrätyn arvon. VALUES-osan listassa täytyy olla yhtä monta arvoa kuin INTO-osassa on luetteltuna sarakkeita. Poikkeuksena tähän sääntöön sarakkeiden nimien listaus voidaan jättää kokonaan pois, jolloin VALUES-osan listassa täytyy olla yhtä monta arvoa kuin taulussa on sarakkeita. Arvot listataan tässä tapauksessa siinä järjestyksessä kuin sarakkeet ovat taulussa.
Sarakkeelle voidaan antaa arvo myös alikyselyn tuloksiin perustuen. Alikyselyn täytyy tällöin palauttaa ainoastaan yksi arvo, joka voi olla myös tyhjäarvo. Lisäyslauseen syntaksi muuttuu tässä tapauksessa niin, että VALUES-listassa arvon sijaan annetaan alikysely:
Joissakin tietokannanhallintajärjestelmissä (esim. PostgreSQL) voidaan yhdellä INSERT-lauseella lisätä useita rivejä seuraavan syntaksin mukaisesti:
Taulurivejä voidaan myös lisätä toisesta taulusta, ts. uudet rivit voivat perustua aiemmin tietokantaan tallennettuun dataan. Tällöin komennon syntaksi on seuraava:
Myös tässä tapauksessa on syytä huomata, että INTO-osassa täytyy olla lueteltuna yhtä monta saraketta kuin lähdetaulusta valitaan SELECT-osassa. Hakulauseeseen voidaan asettaa miten monimutkaisia ehtoja tahansa: sarakkeiden arvojen tarkistuksia, alikyselyitä, koostefunktioita jne.
Huomautus
Se, miten tietokannanhallintajärjestelmä suoriutuu tilanteesta, jossa tietotyypit kohde- ja lähdetaulun välillä eroavat, riippuu tuotteesta. Joissakin tuotteissa lisäystä ei sallita, jos tietotyyppi, merkistökoodaus tai sarakkeen koko eroavat, kun taas jotkin tuotteet yrittävät lisäystä esim. katkaisemalla merkkijonoja tai tekemällä tyyppimuunnoksia.
Taulurivien muokkaaminen
Yhden taulun sarakkeiden arvoja voidaan muuttaa komennolla UPDATE. Komennon syntaksi on:
SET-osassa määrätään, minkä sarakkeiden arvoja muokataan ja miten, ja WHERE-osassa määrätään, minkä rivien osalta sarakkeiden arvoja muokataan.
Huomautus
Jotkin tietokannanhallintajärjestelmät eivät salli itse määriteltyjen tarkentimien käyttöä UPDATE- ja DELETE-lauseissa.
Myös lausekkeeseen voidaan asettaa alikysely. Seuraavassa asetetaan sellaisten tuotteiden, joiden väriä ei ole määritelty, hinta samaksi kuin halvimman tuotteen hinta. SET-osan alikyselyssä tai WHERE-osassa voidaan asettaa miten monimutkaisia ehtoja tahansa.
Taulurivien poistaminen
Taulusta voidaan poistaa rivejä komennolla DELETE. Kuten INSERT- ja UPDATE-komennot, DELETE vaikuttaa vain yhden taulun riveihin. Komennon syntaksi on:
Esimerkiksi:
Lauseen WHERE-osassa voidaan asettaa miten monimutkaisia ehtoja tahansa. Jos WHERE-osa jätetään pois, poistetaan kaikki rivit. DELETE-lause ei varsinaisesti poista rivejä, vaan asettaa ne ylikirjoitettaviksi. Hakulause tauluun ei näytä DELETE-käskyllä poistettuja rivejä, mutta joutuu kuitenkin lukemaan ne.
These are the current permissions for this document; please modify if needed. You can always modify these permissions from the manage page.