English version of the materials are work in progress!
Expect bugs, typos, and other issues. The English version is expected to be completed during spring 2026.
Conceptual Modelling
The first stages of designing a database system include conceptual modelling. Conceptual modelling can be perceived as belonging to the analysis and design phases of the information system lifecycle. At this stage, based on the requirements specification of the domain, it is modelled what data is stored in the database and how different data relate to each other. Conceptual modelling is data model independent, meaning at this stage it is not yet considered which DBMS or data model the final database system will use.
In this subchapter, we examine conceptual modelling using the ER model (Entity-Relationship model). The ER notation is a popular tool for preliminary database design. The chapter assumes that the reader knows the basic principles of the UML class diagram (Unified Modeling Language) from the analysis phase and knows how to create one.
There is no official standard for ER model notation. Despite this, almost all notations for conceptual modelling are based on the notation presented by Chen [5]. This course introduces and uses the notation presented by Jukić et al. [22], which is a slightly combined and clarified version of the notation by Chen [5], Elmasri and Navathe [15], and Hoffer, Prescott, and McFadden [19].
Huomautus
The core goal of conceptual modelling is to distinguish which data is essential for the database and which is not.
Conceptual modelling is thus somewhat individual; different designers may produce slightly different conceptual models for the same requirements specification.
Entity Sets and Attributes
The ER model consists of entity sets, relationship sets, and attributes. Entity sets resemble classes in a class diagram: they describe some independent, real-world concrete or conceptual thing, i.e., an entity, for example, a student, a course, or a study credit. An entity set is interesting from the domain's perspective, meaning we want to store information about it in the database. An entity set is not just one real-world thing, like "Matti" or "Bank Account #123", but describes an abstracted set of things, like "Person" or "Bank Account", with their properties like a class in a class diagram.
Entity sets can have attributes, which are interesting properties of entities from the domain's perspective. For example, a student can have a student ID, name, and date of birth. The value of an attribute is a characteristic of a single entity or relationship.
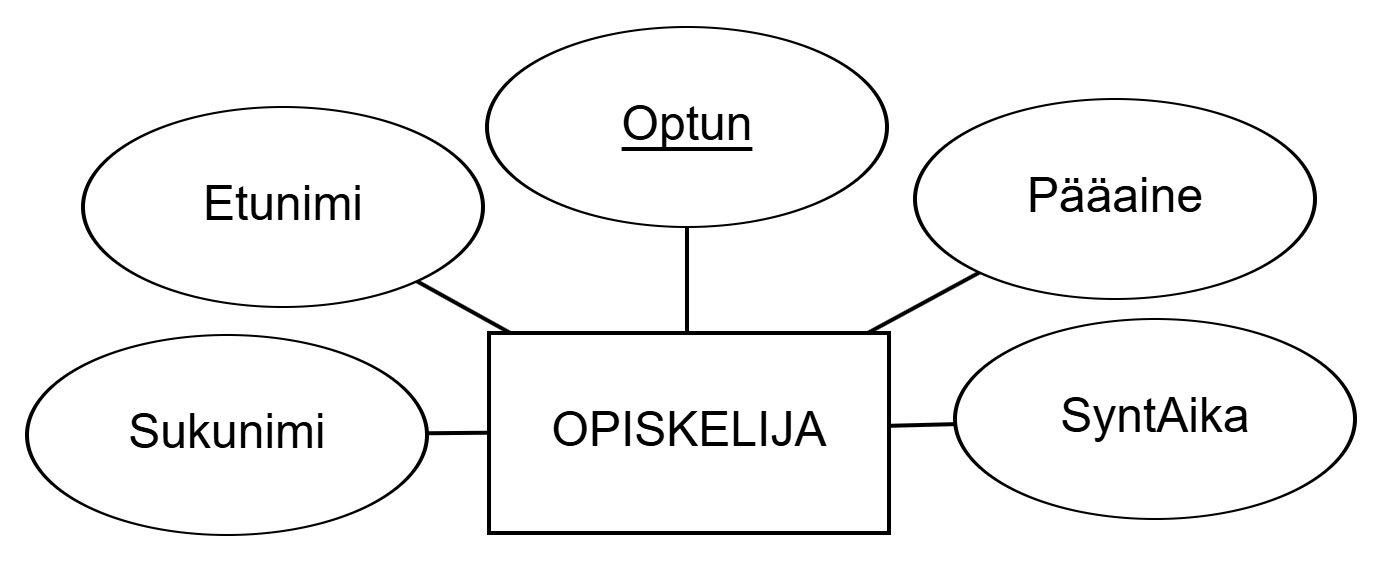
STUDENT with attributes. This entity set student thus describes the set of all students to be stored in the database with their properties.An entity set is marked with a rectangle with the entity set's name inside. Attributes of an entity set are marked with an oval with the attribute's name inside. The spelling of entity set or attribute names does not matter. For clarity, in this material, entity sets are written in uppercase (e.g. STUDENT) and attributes with an initial capital letter without spaces (so-called PascalCase; e.g. FirstName, DateOfBirth). There may be small differences in images and videos; spelling ultimately does not matter for database design or operation.
Key Attribute
Every entity described by an entity set must be unequivocally identifiable from others. Identification is usually done based on some attribute whose value is unique for every entity.
Esimerkki
For example, in a university student register (cf. Sisu) in the STUDENT entity set modelling students, the student's name is not unique enough to identify a single individual student.
Instead, a student ID or student number used in Finland can instead be sufficient information to identify a student depending on the scope of the database.
Such an attribute or set of attributes, with which a single entity of an entity set can be uniquely identified, is called a key attribute. If the value of one attribute is not enough to identify entities from each other, more than one attribute can be used, however, so that a proper subset of key attributes is not enough to identify entities from each other.
Esimerkki
In the university student register, in the STUDENT entity set modelling students, the student ID StudId is suitable as a key attribute, as the student ID can identify the student within the register. Instead, the attribute set {StudId, FirstName} is not a good key attribute set, as its proper subset {StudId} is already enough to identify the student.
Note that identification is always sufficient at the level of the domain database: in another university's register, another student could in principle have the same ID. The essential thing is that the key attribute identifies the student within the same database.
The value of a key attribute cannot be null. Key attributes of an entity set are identified by the underlining of their names.
Composite Attribute
A composite attribute refers to an attribute whose value can be divided into identifiable parts. Directing into parts is especially justified when the attribute is referred to both as a whole and as parts. For example, the attribute Address can be divided into parts Street, PostalCode, and City according to the figure below. If, for example, the address were always referred to as a whole, dividing into parts would not be justified.
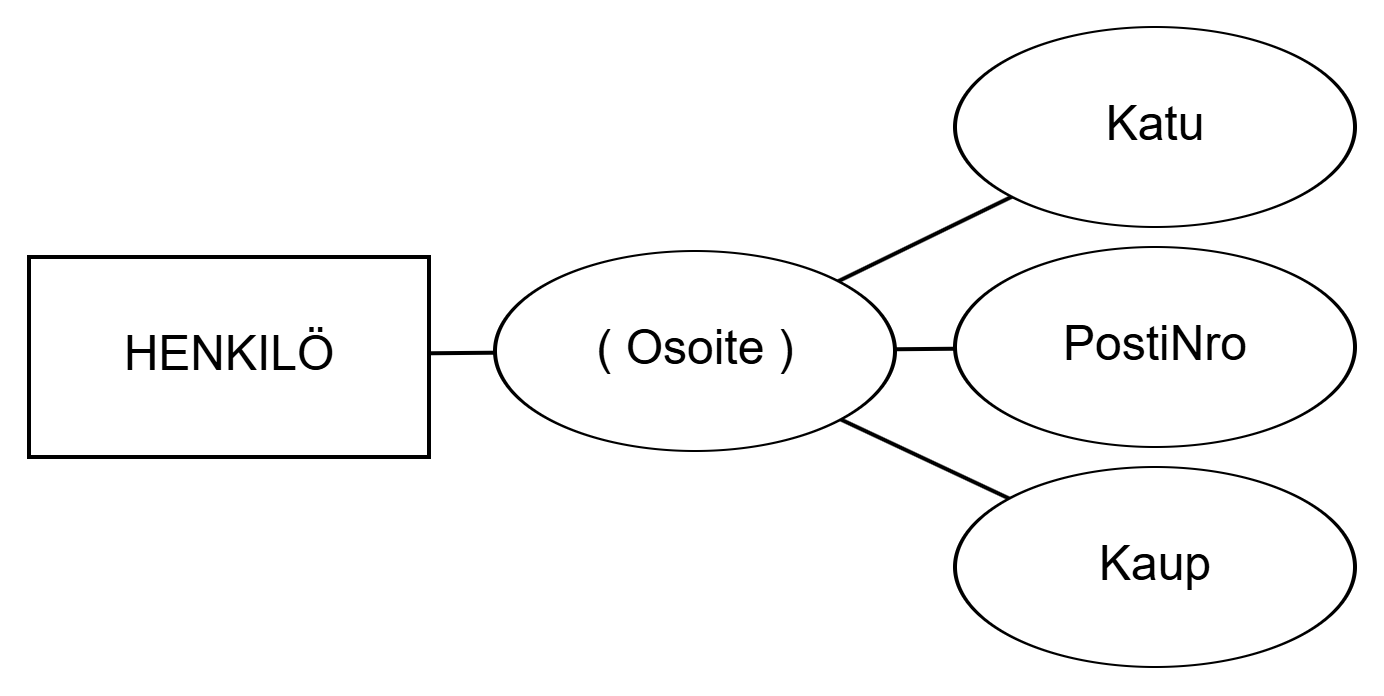
Address of the entity set PERSON.If an attribute is not composite, it is simple. Composite attributes can form even deeper hierarchies.
Derived Attribute
A derived attribute refers to an attribute whose value is derived either
- from the values of another attribute or attributes or
- from the number of entities of a related entity set.
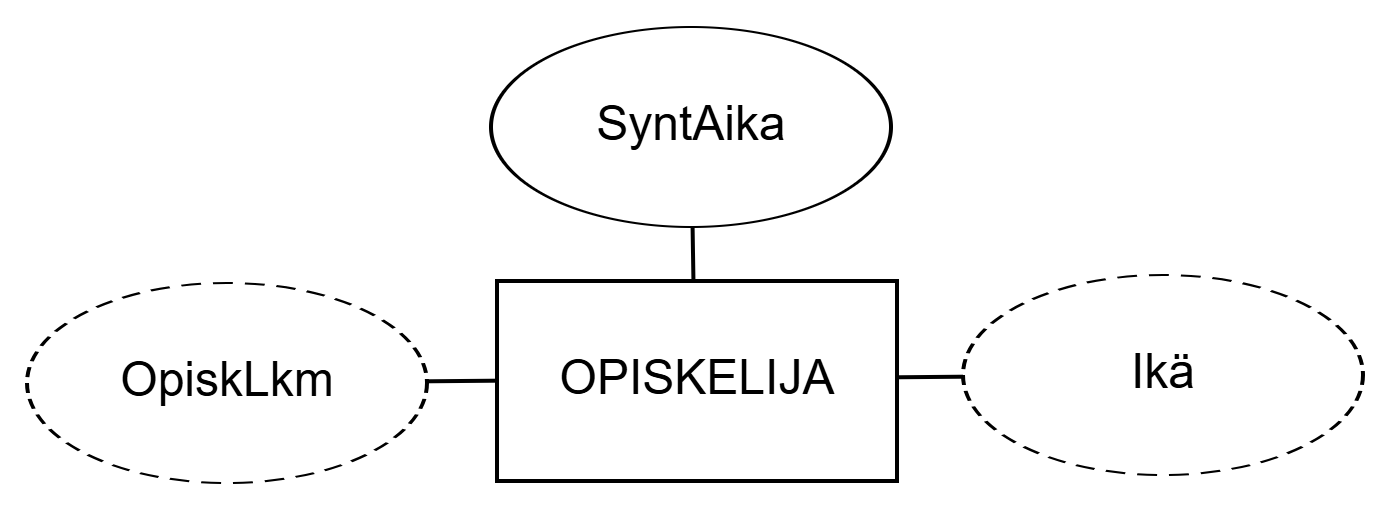
Age and StudentCount of entity set STUDENT. Attribute Age is derived from attribute DateOfBirth and StudentCount from the number of entities.If an attribute is not derived, it is stored.
Multivalued Attribute
Usually, attributes have one value, and such attributes are called atomic. However, it is possible that attributes of entities in an entity set can have multiple values, for example, a student can have multiple phone numbers or email addresses. If an attribute can have multiple values, it is called multivalued.
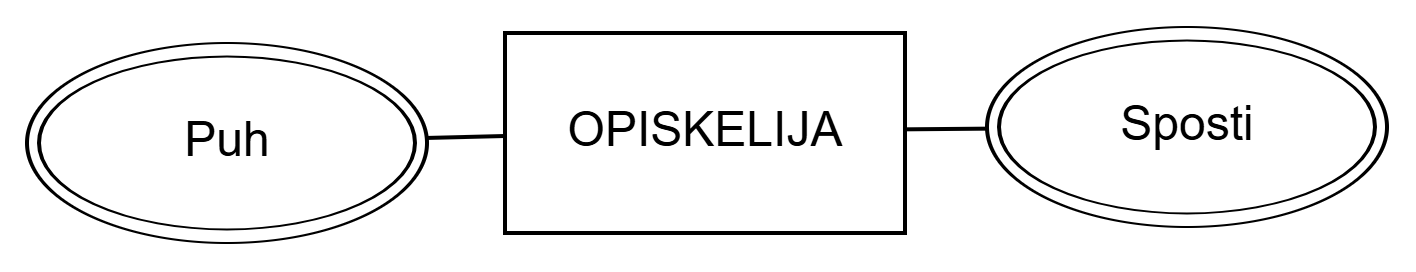
Phone and Email of the entity set STUDENT.A multivalued attribute is marked with a double oval as shown in the figure above.
Relationship Sets
Entities, like real-world things, typically have some kind of relationships with each other. A relationship is any dependency or other context interesting from the domain's perspective existing between one or more entities. Sets of relationships form relationship sets. When designing a database, relevant relationships between entities must be identified and described in the ER diagram.
Relationship sets are described in ER notation with a horizontally rotated diamond pattern, which is connected to the entity sets participating in the relationship. The relationship is usually described with some 3rd person singular verb. In this material, relationships are written with the same spelling as attributes, i.e., with an initial capital letter and without spaces (so-called PascalCase). As before, small differences may be found in images and videos; spelling has no practical significance.
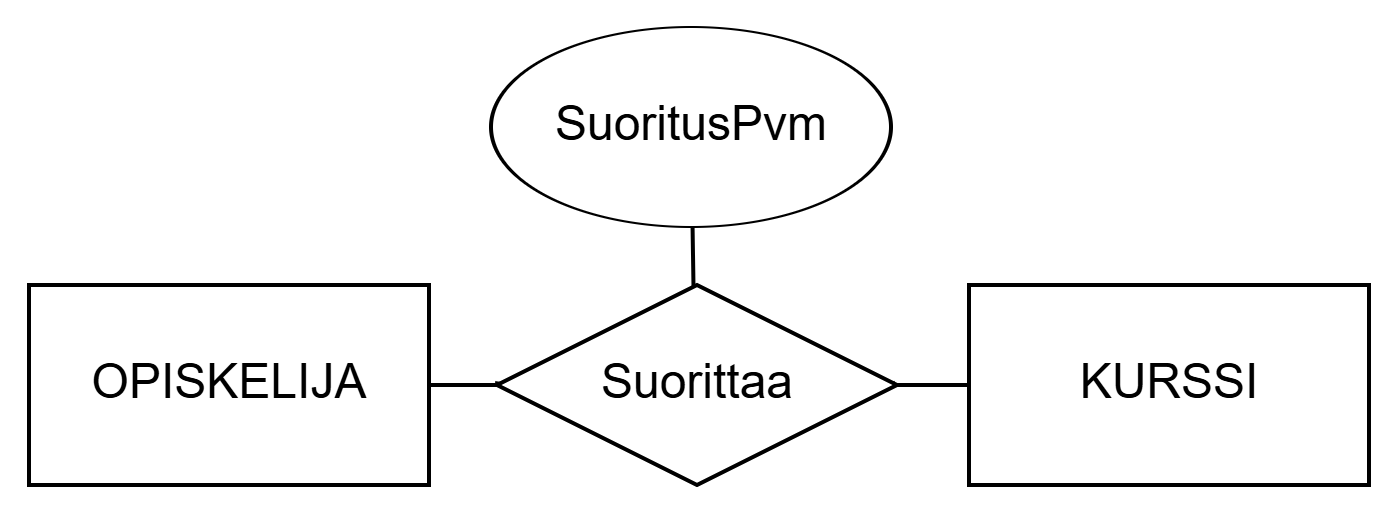
Completes between entity sets STUDENT and COURSE. Attribute CompletionDate relates to the relationship set describing the date of the course completion.Relationship sets can also have attributes. Attributes of a relationship set describe some property of the relationship, for example, CompletionDate in the example above. The completion date does not relate to the entity set COURSE, nor to the entity set STUDENT, but to the relationship between the entity sets.
Degree of a Relationship
A relationship set in which  entity sets participate is said to be of degree . The degree of the relationship set described above is 2, i.e., the relationship set is binary. Two entity sets can have more than one binary relationship set between them. The degree of a relationship set can be any integer 1..n. Below is described a unary (degree 1) and ternary (degree 3) relationship set.
entity sets participate is said to be of degree . The degree of the relationship set described above is 2, i.e., the relationship set is binary. Two entity sets can have more than one binary relationship set between them. The degree of a relationship set can be any integer 1..n. Below is described a unary (degree 1) and ternary (degree 3) relationship set.
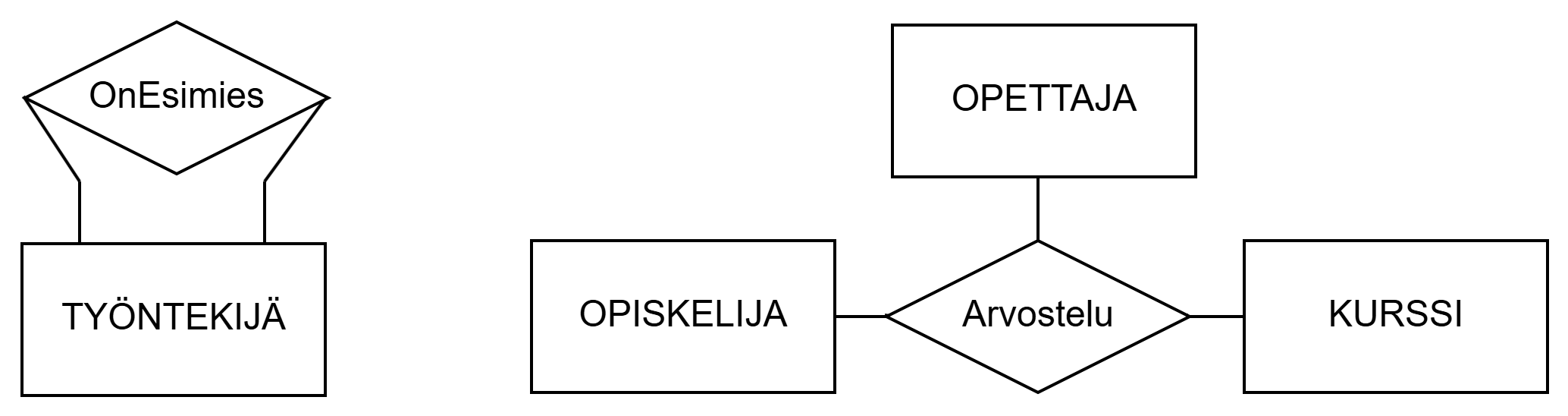
According to the figure above, an employee can be a supervisor for other employees. In the second example, it is important for the domain to know which teacher has graded the student's course performance.
Huomautus
Relationship sets with a degree higher than two have their own problems, and they are hardly covered in this material.
The example above could be implemented with a weak entity set GRADING. Weak entity sets will be discussed a little later.
Cardinality
Cardinality tells how many relationships of a certain type an entity participates in or can participate in. There are two types of cardinalities: minimum cardinality (i.e., modality) tells the minimum necessary number of entities in the relationship, while maximum cardinality tells the maximum allowed number of entities.
This material covers notation where the minimum cardinality is either 0 or 1 and the maximum cardinality is either 1 or N. In other words, the cardinality of an entity set in a relationship can be presented in four ways:
| Max. 1 | Max. N | |
|---|---|---|
| Min. 0 | 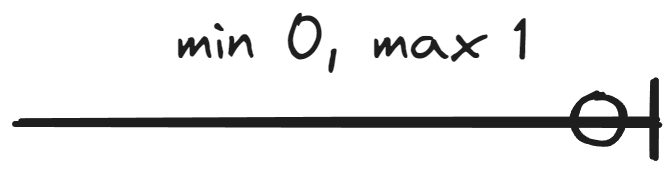 |
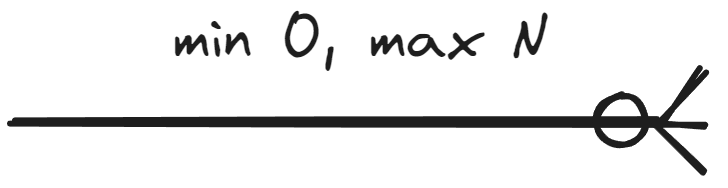 |
| Min. 1 | 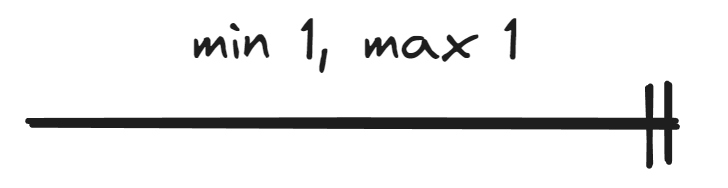 |
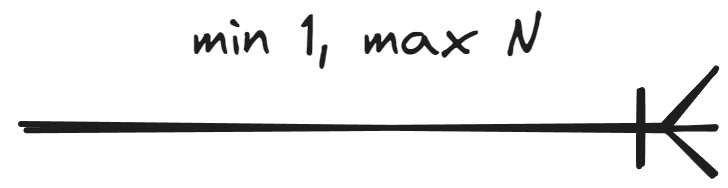 |
The cardinality of an entity set is marked on the side of the relationship towards which it is read.
Esimerkki
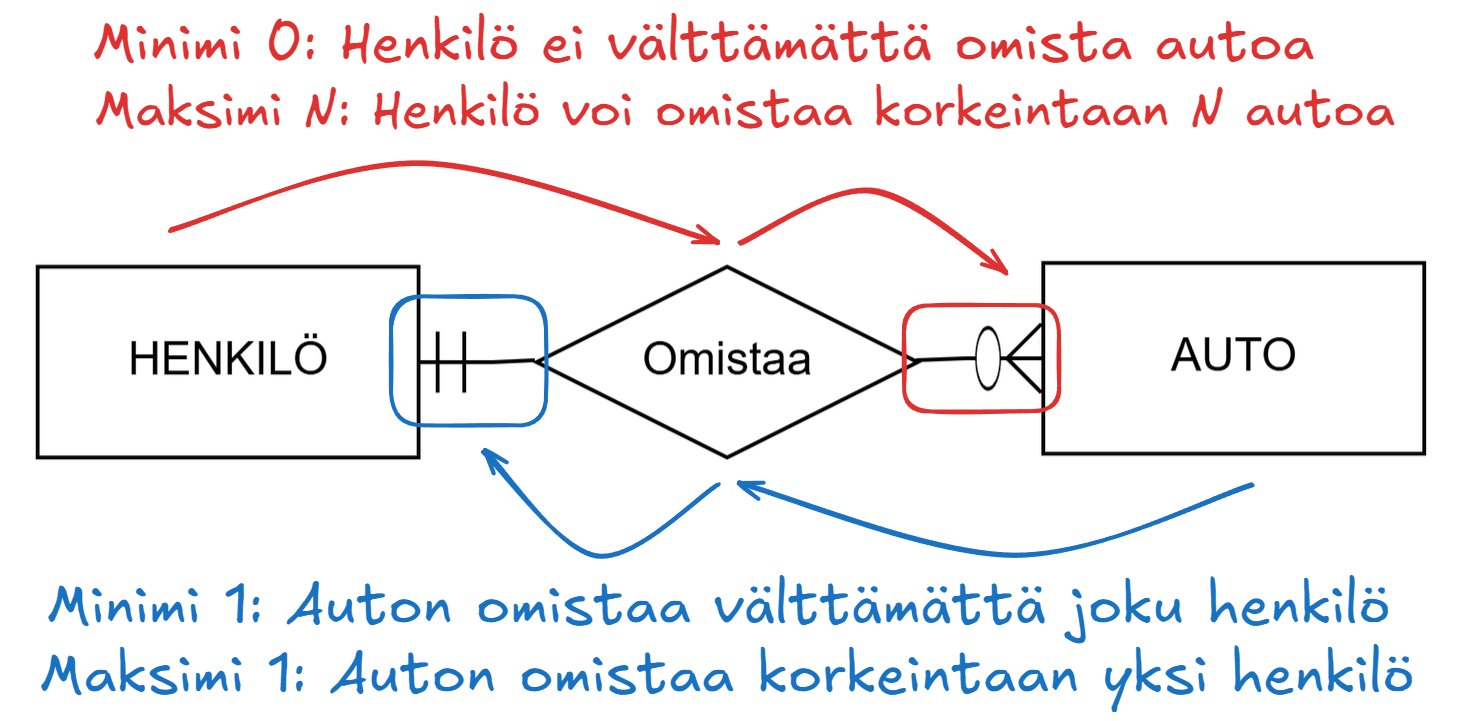
Let's think about cardinalities in the following domain: we want to design a car register that keeps track of cars and the people who own them.
In this case, there are two entity sets PERSON and CAR and the relationship Owns between them. Based on the domain, it is most sensible to choose the cardinality of the relationship as follows:
- A person does not necessarily own a car but can own several. Thus, the minimum cardinality is 0 and the maximum cardinality is N.
- A car always has exactly one owner. The minimum cardinality is thus 1 and the maximum cardinality is 1.
Using the table above as help, we get the following ER model:

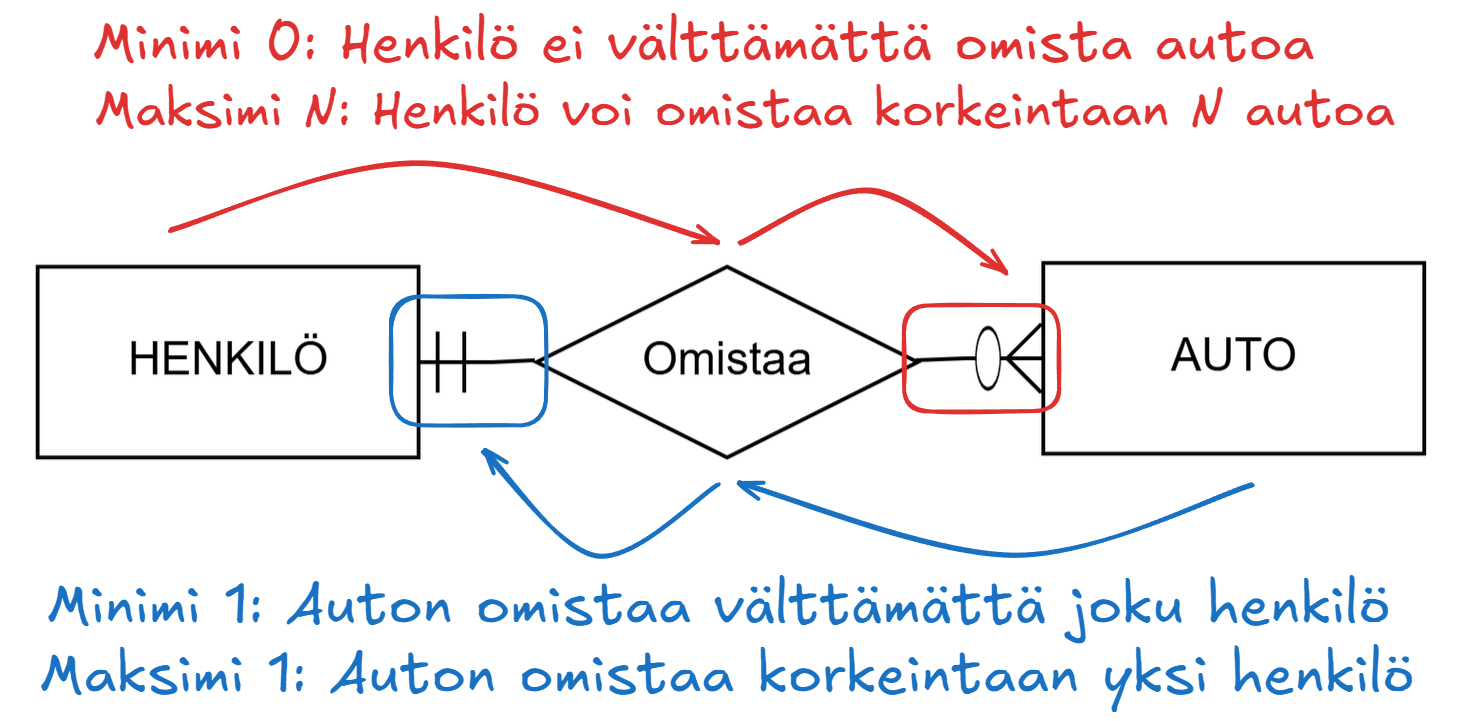
Owns between entities PERSON and CAR with cardinality markings.Note the reading direction:
- Left to right: "A person owns zero to many cars"
- Right to left: "A car can be owned by at least one and at most one person"
The reading direction is marked more clearly below:
Markings can be thought of through example entities. Imagine the following example with three people and four cars. In this case, the ownership relationship between car and person could look like this:
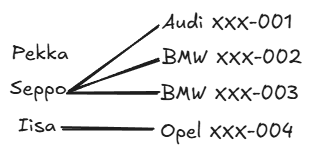
Since from every car there is always one line to some person, minimum cardinality 1 (vertical line) and maximum cardinality 1 (vertical line) are chosen for the PERSON entity set side. Similarly, since no line goes from some person to a car, minimum cardinality 0 (circle) is chosen for the CAR entity set side. Since from one person there are multiple lines to different cars, the maximum cardinality is N (branching lines).
Huomautus
The cardinality notation described above is the so-called Hoffer-Prescott-McFadden notation, which is popular in many 3rd party design tools used alongside database management systems.
Other commonly used cardinality notations are described below: on the left Chen's notation, in the middle a UML-like notation, and on the right the Hoffer, Prescott & McFadden notation used in the material.
![Figure: Different cardinality notations: Chen [5]; UML [32]; Hoffer, Prescott & McFadden [19].](/files/kurssit/tie/itka2004/course/sections/2/02_ch22_er_mallinnus/en-US/3a3763c774f3886ae79be3a895da1d737006aec8.png)
Weak Entity Set and Identifying Relationship Set
If entities according to an entity set cannot be identified using its own attributes, it is called a weak entity set. A weak entity set is marked with a double rectangle. Entities according to a weak entity set are identified using key attributes of another entity set, and such an entity set is called an identifying entity set. An identifying entity set is described using an identifying relationship set. An identifying relationship set is described with a double diamond.
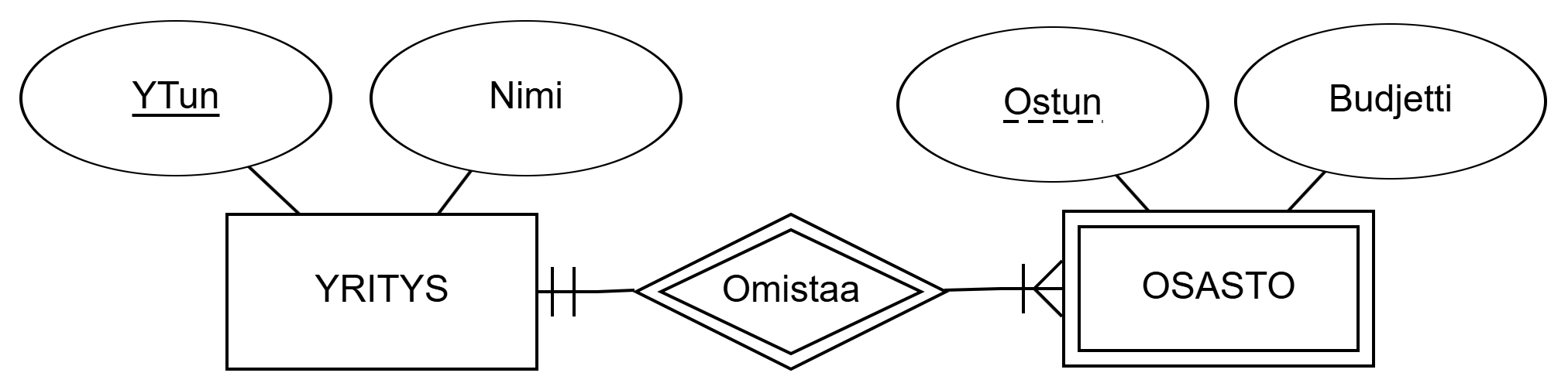
DEPARTMENT and identifying entity set COMPANY.In the figure above, the weak entity set DEPARTMENT is identified using the strong entity set COMPANY. The name of the weak entity set's key attribute is underlined with a dashed line. Departments of the domain described above are thus identified by a combination of the department ID and the company ID. In other words, the database can adhere two departments with the same department ID DepId, but they belong to a different company. Thus, the attribute set {CompId, DepId} can uniquely identify a department.
Huomautus
The maximum cardinality of a weak entity set in an identifying relationship set should usually be at most 1.
This is not a constraint, but rather a strong recommendation. In the figure above, a department can belong to at most one company, and a department can be uniquely identified through its company ID and department ID.
What if a department could belong to two different companies? How would the department be identified then? Can the department then be uniquely identified in two ways: {CompId1, DepId} and {CompId2, DepId}? Or are IDs of both companies needed to identify the department: {CompId1, CompId2, DepId}? ER notation does not offer clear markings for different alternatives, and these cannot be easily converted into a logical structure of a database. Therefore, it is better to take as a rule of thumb that a weak entity set can belong at most once to an identifying relationship.
DEPARTMENT entity set. Modelling this at the logical level is difficult.In such cases, it may be easier to change the weak entity set to a regular entity set.
Abstraction Structures
ER notation has been supplemented later. One such addition is the so-called EER notation (extended or enhanced ER), which adds abstraction structures, among other things, to the notation. With abstraction structures, hierarchies and inheritance according to object-orientation can be modelled: sub-entity sets inherit attributes of their super-entity set. Inheritance between entity sets is marked according to the following figure.
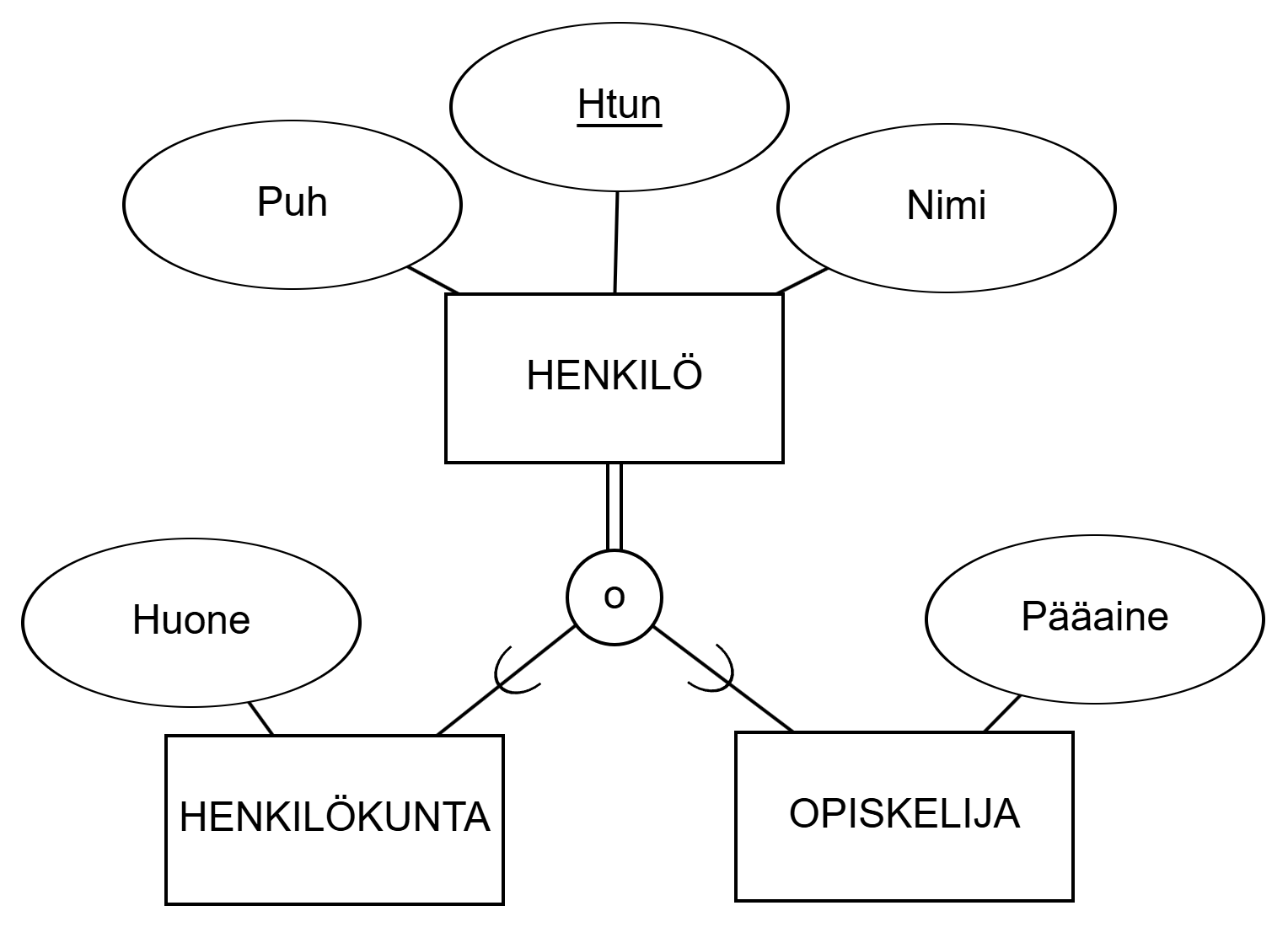
STAFF and STUDENT inherit attributes of the super-entity set PERSON.The super-entity set in the figure is PERSON, sub-entity sets STUDENT and STAFF. U-shaped markings point to sub-entity sets. The circle is connected to the super-entity set by either one or two lines depending on the coverage of sub-entities. Abstraction structures can form even more complex hierarchies.
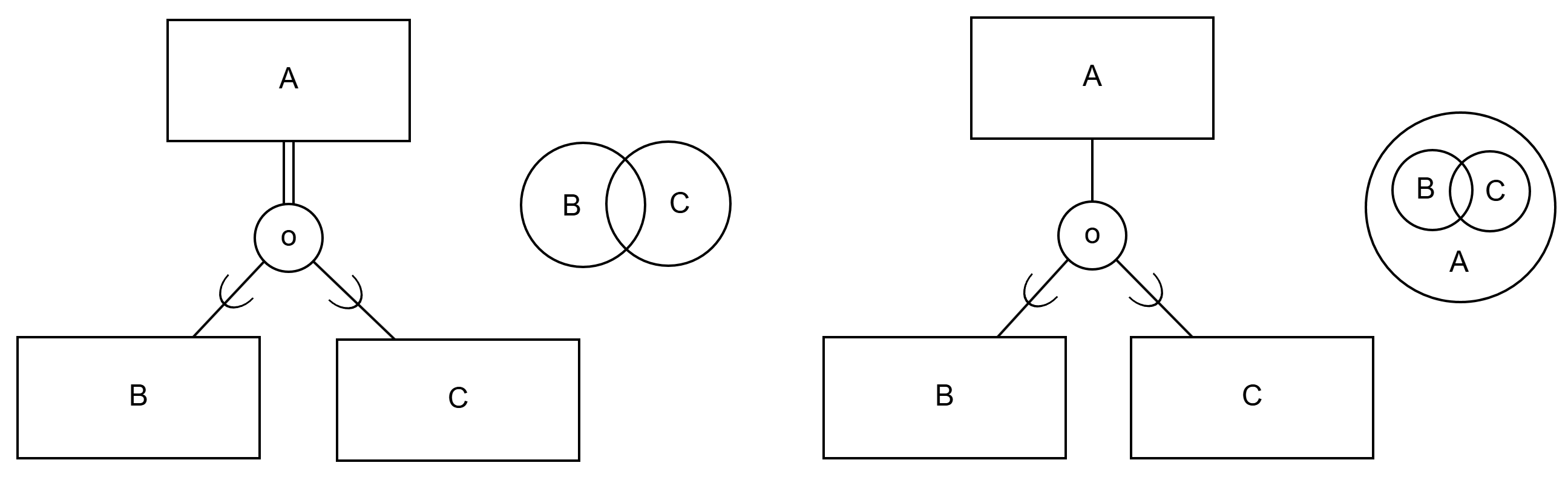
Inside the circle is marked either the letter d or o depending on whether the abstraction is disjoint (d) or overlapping (o). Let's examine next these two different generalization structures according to EER notation.
Disjoint
Disjoint abstraction structure means that sub-entities can belong to at most one sub-entity set (so-called either-or abstraction). For example, a VEHICLE can be either a CAR or a BOAT. Disjoint abstraction is marked with the letter d placed inside the circle.
The coverage of the sub-entity set group is described by one or two lines between the circle and the super-entity set:
- one line (partial abstraction): a certain entity does not need to be an entity according to any sub-entity set (e.g., there can be vehicles in the domain that are neither cars nor boats, such as motorcycles);
- two lines (total abstraction): all entities belong to some sub-entity set (e.g., in the domain all occurring vehicles are either cars or boats).
The figure below summarizes what entities a disjoint and total as well as disjoint and partial abstraction structure can model.
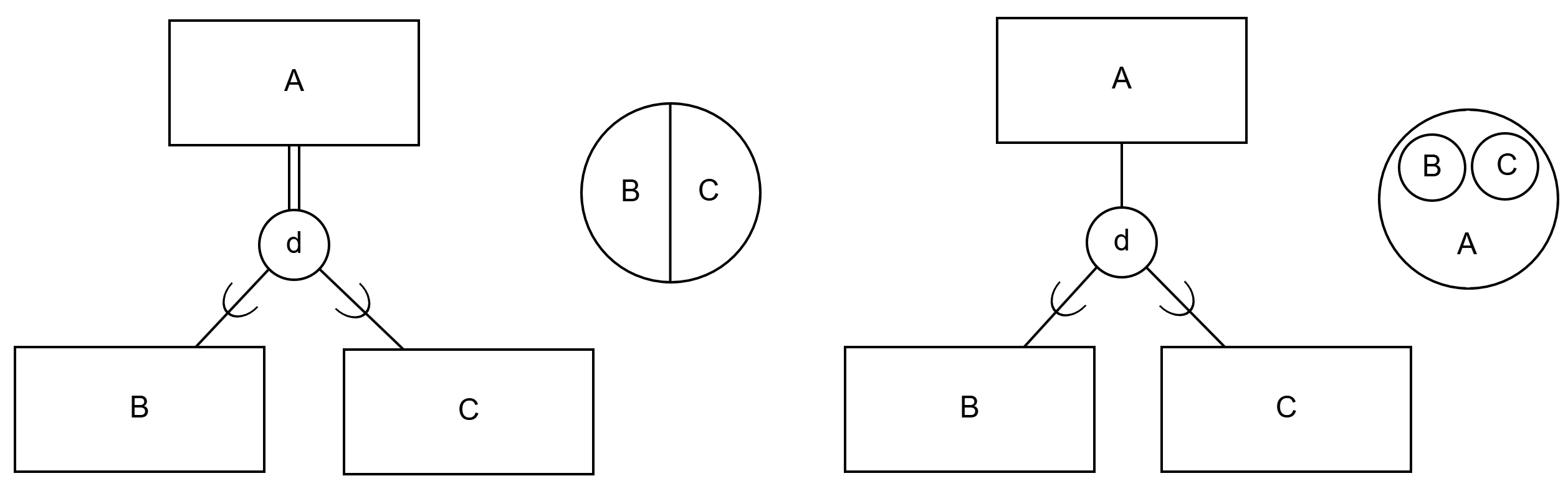
A can be either B or C"). On the right, disjoint and partial generalization relationship and relationship between entities ("entities A can be B or C or something else").Overlapping
Overlapping abstraction structure means that sub-entities can belong to more than one sub-entity set (so-called "both-and" abstraction). For example, a room can be both a kitchen and a dining room. Overlapping abstraction structure is described with the letter o placed inside the circle. Like disjoint, overlapping abstraction structure is either total or partial. For example:
- one line (partial abstraction): in the domain, there can be vehicles that are either cars, boats, or both or something else;
- two lines (total abstraction): in the domain, all vehicles are either cars, boats, or both.
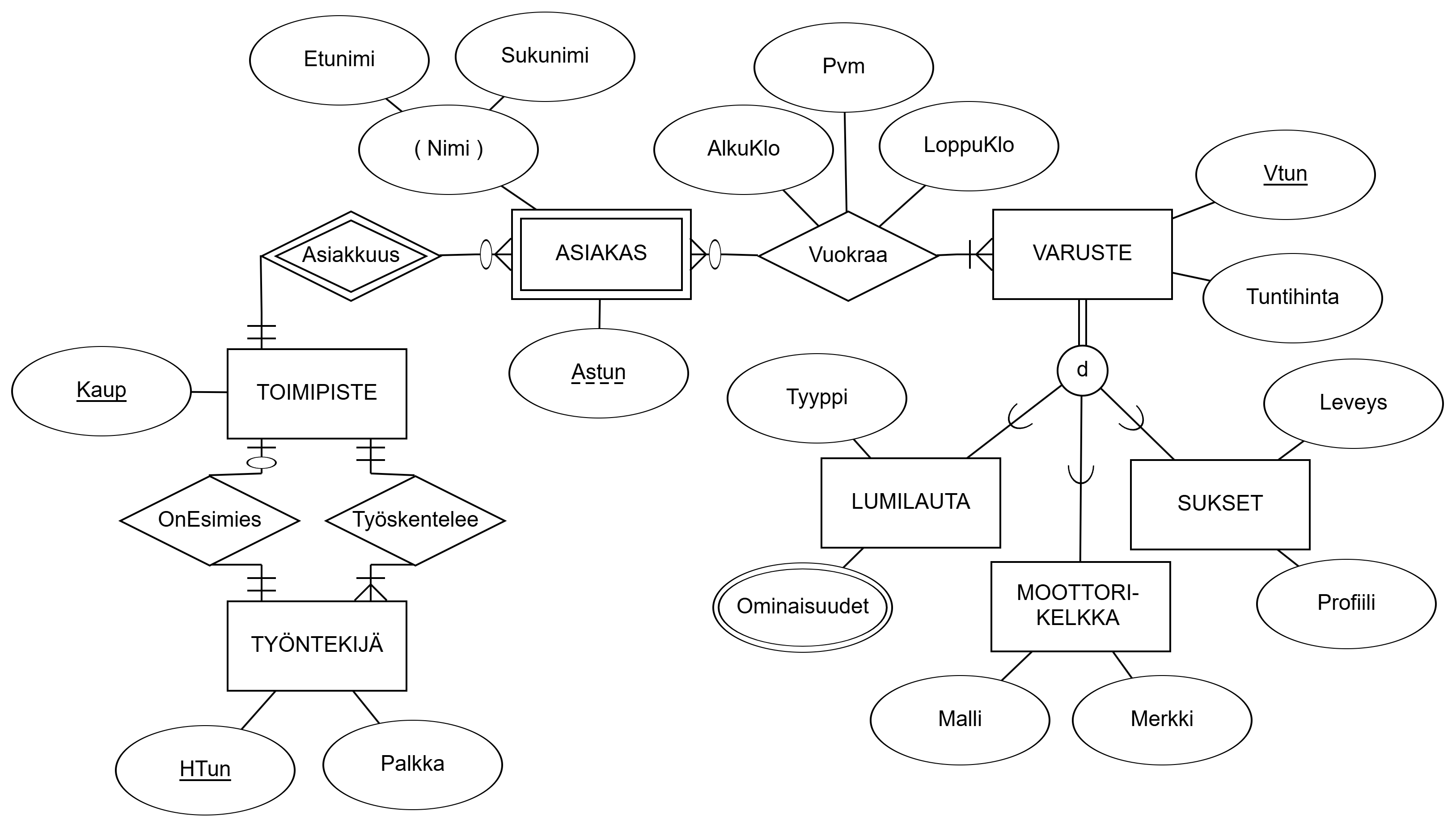
A can be B or C or both at the same time"). On the right, overlapping and partial generalization relationship and relationship between entities ("entities A can be B, C, both, or something else").Multiple choice questions relate to the following ER diagram:
Phases of Conceptual Modelling
There is no precisely standardized process for conceptual modelling. Below are some tips on how to approach modelling:
Draw up a requirements specification if one does not already exist. The requirements specification should make clear the domain, the needs of the system to be implemented, and the central concepts related to it.
Start by identifying basic entity sets from the requirements specification.
- Look for, among other things, recurring concepts that are concrete things (e.g. product, customer) or conceptual things (e.g. order, order line)
- Is there information related to the concept that generally wants to be stored in the database?
- Give the entity sets clear names and, if necessary, describe their meaning.
- Note: if some information can be derived through some other database information, it is not worth modelling. For example, various reports, printouts, and analytics can be derived directly from other entity sets.
Next, identify central relationship sets and their cardinalities.
- Focus on relationships that are relevant to the database.
- The most common relationships concern existence, action, or event.
- Is it meaningful to store the relationship in the database (e.g. who printed which report, who bought what)?
- You may have to make additional assumptions to define cardinalities.
Identify attributes.
- What properties are really wanted to be stored in the database?
- Some properties may be derived from other properties.
- Choose a suitable key attribute. If one is not found, create some
IDattribute (e.g. a sequential number that identifies entities). - Mark special attributes correctly (multivalued, derived, composite).
Iterate and refactor.
- Add new entities, attributes, or relationships that emerge during the modelling process. Remember to supplement the requirements specification if necessary.
- Can entity sets and attributes be named better?
- Do some attributes belong better to a relationship than to an entity set?
- Are cardinalities marked sensibly from the domain's perspective?
- Use abstraction structures if necessary to clarify the model, especially if several entities have the same attributes.
Esimerkki
Let's make an ER diagram according to the description below, showing entity sets, relationship sets, most essential attributes, key attributes, as well as minimum and maximum cardinalities.
- The database contains information about customers: customer ID, name, address.
- Customers order products on certain days, which have a product number, product name, and price.
- An order is identified by an order number.
- An order can concern multiple products (certain amounts).
Let's identify initially all basic entity sets (concepts, things, conceptual things), relationship sets (relevant verbs related to concepts), and attributes (properties related to concepts).
Identified ENTITIES, Attributes, and Relationships marked in the description:
- The database contains information about
CUSTOMERs:CustomerId,Name,Address. - Customers Order on certain days
PRODUCTs, which haveProductNumber,ProductName, andPrice. ORDERis identified byOrderNumber.- An order can Concern multiple products (certain
Amounts).
Cardinalities cannot be fully deduced based on the given description. In this case, a few sensible additional assumptions from the domain's perspective are made:
- A customer can exist without orders (e.g. online store).
- Every order is made by exactly one customer.
- An order always has some product (on the other hand: could it be sensible that there could be? Think e.g. online store where the shopping cart is empty at the beginning.)
- A product has not necessarily ever been ordered before, i.e., it is not in any order.
Based on these, the final ER diagram can be modelled.
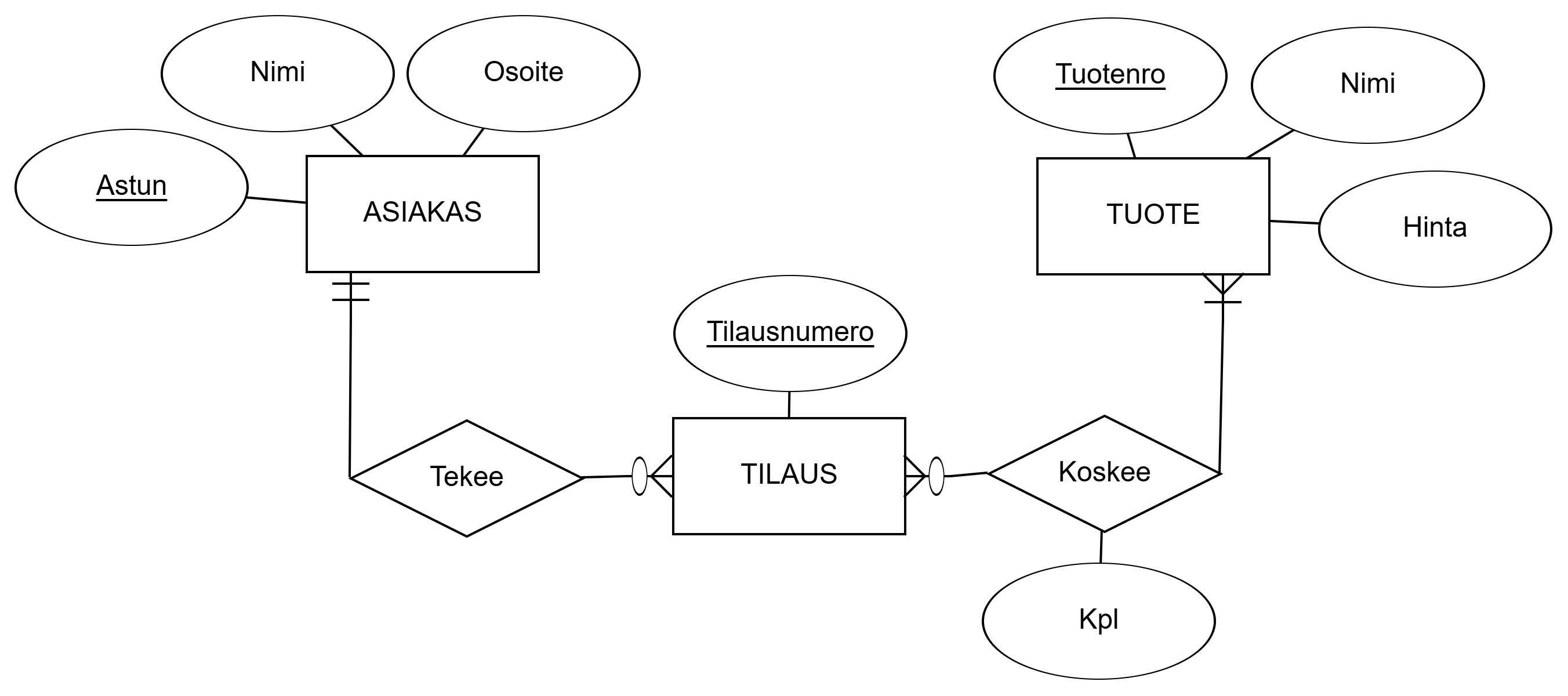
Observations:
- Try to keep models simple. Weak entity sets, composite attributes, and ternary relationships often complicate design. The best solution is usually the simplest one!
- Similarly, there could be many different valid ER diagrams for the same requirements specification. In later chapters, we will notice that even different ER diagrams can finally produce a similar database structure.
- Requirements specifications are rarely perfect. Think about what information is missing and refine the requirements specification. If necessary, you have to make sensible additional assumptions from the domain or application perspective. In this example, e.g.,
ORDERcannot be without products, but in some applications, this could be sensible.
Käsitteellinen mallintaminen
Tietokantajärjestelmän suunnittelun ensimmäisiin vaiheisiin kuuluu käsitteellinen mallintaminen. Käsitteellinen mallintaminen voidaan mieltää kuuluvaksi tietojärjestelmän elinkaaren analyysi- ja suunnitteluvaiheisiin. Tässä vaiheessa kohdealueen vaatimusmäärittelyn perusteella mallinnetaan, mitä tietoa tietokantaan tallennetaan ja miten eri tiedot liittyvät toisiinsa. Käsitteellinen mallintaminen on tietomalliriippumaton, eli tässä vaiheessa ei vielä mietitä, mitä DBMS:ää tai tietomallia lopullinen tietokantajärjestelmä käyttää.
Tässä alaluvussa tarkastellaan käsitteellistä mallintamista käyttäen ER-mallia (Entity-Relationship model). ER-notaatio on suosittu tietokantojen alustavan suunnittelun työkalu. Luvussa oletetaan, että lukija tuntee analyysivaiheen UML-luokkakaavion (Unified Modeling Language) perusperiaatteet ja osaa luoda sellaisen.
ER-mallien merkintätavalle ei ole virallista standardia. Tästä huolimatta miltei kaikki käsitteellisen mallinnuksen merkintätavat pohjautuvat Chenin [5] esittämään notaatioon. Tällä kurssilla tutustutaan ja käytetään Jukićin ym. [22] esittämää notaatiota, joka on hieman yhdistetty ja selkeytetty versio Chenin [5], Elmasrin ja Navathen [15] sekä Hoffer, Prescott ja McFaddenin [19] notaatiosta.
Huomautus
Käsitteellisen mallintamisen ydintavoite on erottaa, mikä data on tietokannan kannalta oleellinen ja mikä ei.
Käsitteellinen mallintaminen on siten joksikin yksilöllistä; eri suunnittelijat saattavat tuottaa samalle vaatimusmäärittelylle hieman erilaisia käsitteellisiä malleja. Käsitteellinen mallintaminen on siten jokseenkin yksilöllistä; eri suunnittelijat saattavat tuottaa samalle vaatimusmäärittelylle hieman erilaisia käsitteellisiä malleja.
Kohdetyypit ja attribuutit
ER-malli koostuu kohdetyypeistä (entity set), suhdetyypeistä (relationship set) ja attribuuteista (attribute). Kohdetyypit muistuttavat luokkakaavion luokkia: ne kuvaavat jotakin itsenäistä, reaalimaailman konkreettista tai käsitteellistä asiaa eli kohdetta, esimerkiksi opiskelijaa, kurssia tai opintosuoritusta. Kohdetyyppi on kohdealueen kannalta mielenkiintoinen, eli siitä halutaan tallentaa tietoa tietokantaan. Kohdetyyppi ei ole vain yksi reaalimaailman asia, kuten "Matti" tai "Pankkitili #123", vaan kuvaa abstrahoidun asioiden joukon, kuten "Ihminen" tai "Pankkitili", ominaisuuksineen kuten luokkakaavion luokka.
Kohdetyypeillä voi olla attribuutteja, jotka ovat kohteiden kohdealueen kannalta mielenkiintoisia ominaisuuksia. Esimerkiksi opiskelijalla voi olla opiskelijatunnus, nimi ja syntymäaika. Attribuutin arvo on yksittäisen kohteen tai suhteen ominaispiirre.
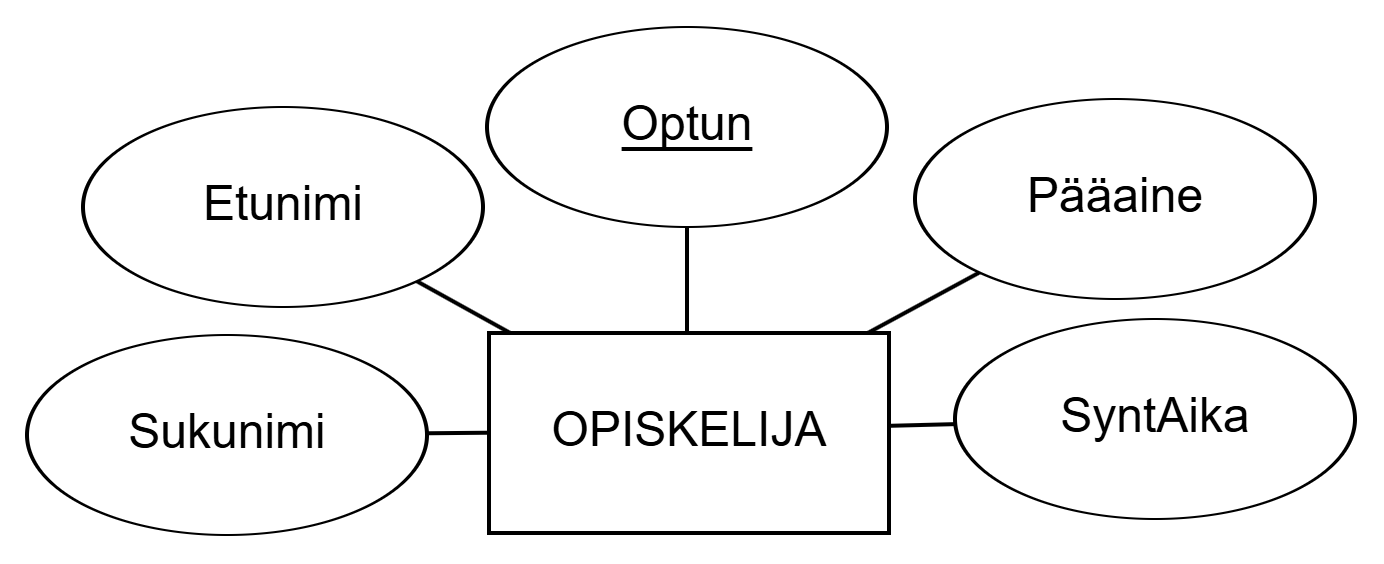
OPISKELIJA attribuutteineen. Tämä kohdetyyppi opiskelija kuvaa siis kaikkien tietokantaan tallennettavien opiskelijoiden joukon ominaisuuksineen.Kohdetyyppiä merkitään suorakulmiolla, jonka sisällä on kohdetyypin nimi. Kohdetyypin attribuutteja merkitään soikiolla, jonka sisällä on attribuutin nimi. Kohdetyyppien tai attribuuttien nimien kirjoitusasulla ei ole väliä. Selkeyden vuoksi tässä materiaalissa kohdetyypit pyritään kirjoittamaan isolla (esim. OPISKELIJA) ja attribuutit isolla alkukirjaimella ilman välilyöntiä (ns. PascalCase; esim. Etunimi, SyntAika). Pieniä eroja voi olla kuvissa ja videoissa; kirjoitusasulla ei loppujen lopuksi ole merkitystä tietokannan suunnittelun tai toiminnan kannalta.
Avainattribuutti
Jokaisen kohdetyypin kuvaaman kohteen on oltava yksiselitteisesti tunnistettavissa toisistaan. Tunnistaminen tehdään tavallisesti jonkin sellaisen attribuutin perusteella, jonka arvo on jokaisella kohteella yksikäsitteinen.
Esimerkki
Esimerkiksi yliopiston opiskelijarekisterissä (vrt. Sisu) opiskelijoita mallintavassa OPISKELIJA-kohdetyypissä opiskelijan nimi ei ole tarpeeksi yksikäsitteinen yksittäisen opiskelijan tunnistamiseksi.
Sen sijaan opiskelijatunnus tai Suomessa käytetty opiskelijan numero voi sen sijaan olla tietokannan laajuudesta riippuen riittävä tieto opiskelijan tunnistamiseksi. Sen sijaan opiskelijatunnus tai Suomessa käytetty opiskelijanumero voi sen sijaan olla tietokannan laajuudesta riippuen riittävä tieto opiskelijan tunnistamiseksi.
Tällaista attribuuttia tai -joukkoa, joiden avulla kohdetyypin yksittäistä kohdetta voi yksilöllisesti tunnistaa, kutsutaan avainattribuutiksi (key attribute). Jos yhden attribuutin arvo ei riitä tunnistamaan kohteita toisistaan, voidaan käyttää useampaa kuin yhtä attribuuttia kuitenkin niin, että avainattribuuttien aito osajoukko ei riitä tunnistamaan kohteita toisistaan.
Esimerkki
Yliopiston opiskelijarekisterissä opiskelijoita mallintavassa OPISKELIJA-kohdetyypissä opiskelijan tunnus Optun on sopiva avainattribuutti, sillä opiskelijan tunnus voi yksilöidä opiskelijaa rekisterin sisällä. Sen sijaan attribuuttijoukko {Optun, Etunimi} ei ole hyvä avainattribuuttijoukko, sillä sen aito osajoukko {Optun} riittää jo opiskelijan yksilöimiseksi.
Huomaa, että yksilöiminen riittää aina kohdealueen tietokannan tasolla: eri yliopiston rekisterissä toisella opiskelijalla voisi periaatteessa olla sama tunnus. Olennaista on, että avainattribuutti yksilöi opiskelijan saman tietokannan sisällä. Huomaa, että yksilöiminen riittää aina kohdealueen tietokannan tasolla: toisen yliopiston rekisterissä toisella opiskelijalla voisi periaatteessa olla sama tunnus. Olennaista on, että avainattribuutti yksilöi opiskelijan saman tietokannan sisällä.
Avainattribuutin arvo ei voi olla tyhjäarvo. Kohdetyypin avainattribuutit tunnistetaan niiden nimien alleviivauksesta.
Koottu attribuutti
Kootulla (composite) attribuutilla tarkoitetaan attribuuttia, jonka arvo voidaan jakaa tunnistettaviin osiin. Osiin jakaminen on erityisen perusteltua silloin, kun attribuuttiin viitataan sekä kokonaisuutena että osina. Esimerkiksi attribuutti Osoite voidaan alla olevan kuvion mukaan jakaa osiin Katu, PostiNro ja Kaup. Jos esimerkiksi osoitteeseen viitattaisiin aina kokonaisuutena, ei osiin jakaminen olisi perusteltua.
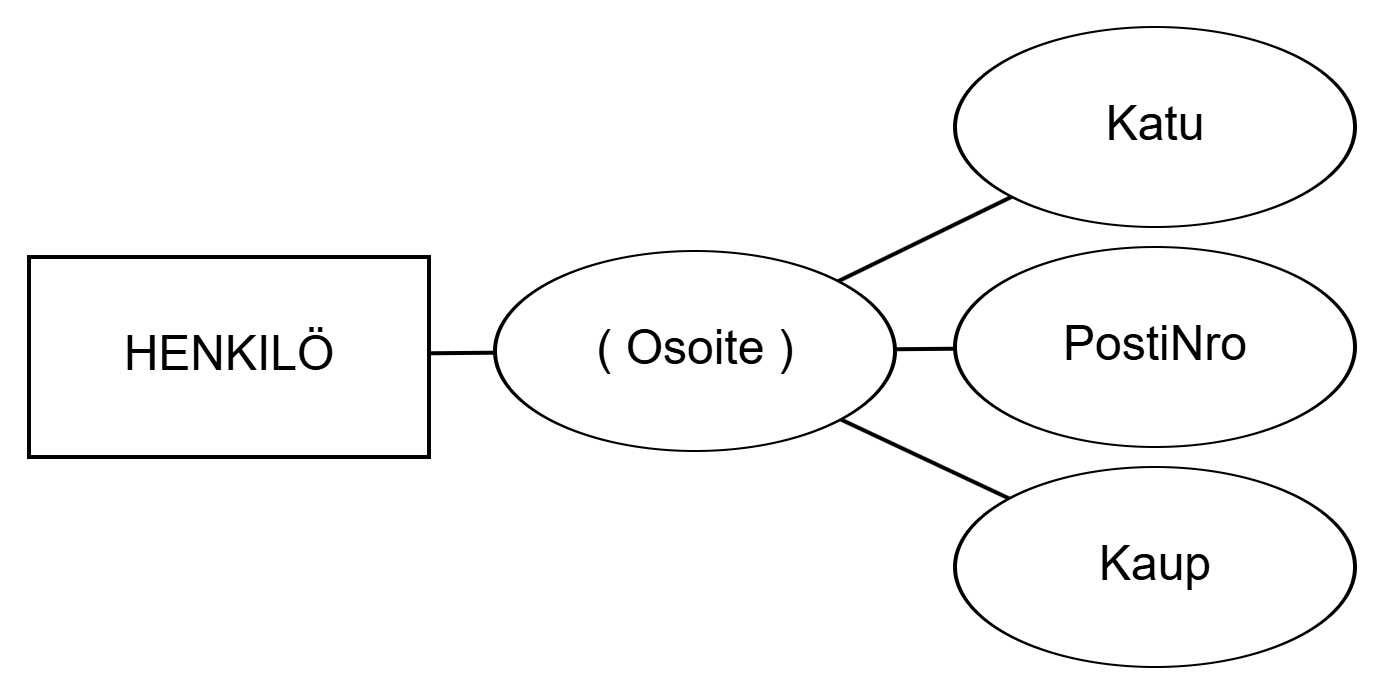
HENKILÖ koottu attribuutti Osoite.Jos attribuutti ei ole koottu, se on yksinkertainen (simple). Kootut attribuutit voivat muodostaa syvempiäkin hierarkioita.
Johdettu attribuutti
Johdetulla (derived) attribuutilla tarkoitetaan attribuuttia, jonka arvo on johdettu joko
- toisen attribuutin tai attribuuttien arvoista tai
- siihen liittyvän kohdetyypin kohteiden lukumäärästä.
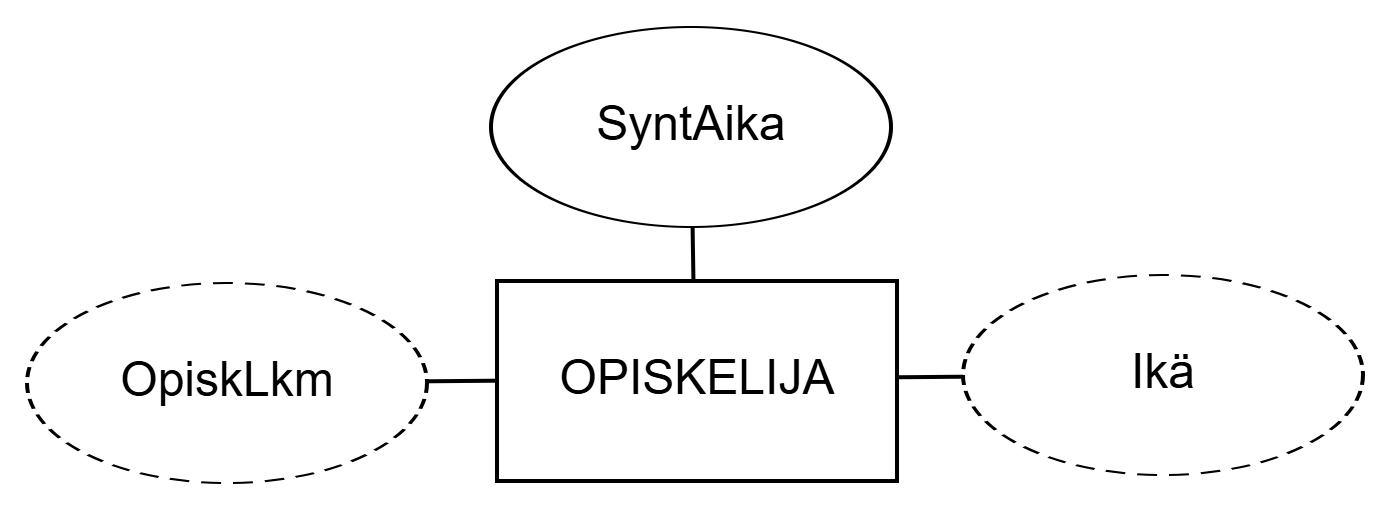
OPISKELIJA johdetut attribuutit Ikä ja OpiskLkm. Attribuutti Ikä on johdettu attribuutista SyntAika ja OpiskLkm kohteiden lukumäärästä.Jos attribuutti ei ole johdettu, se on tallennettu (stored).
Moniarvoinen attribuutti
Tavallisesti attribuuteilla on yksi arvo, ja tällaisia attribuutteja kutsutaan atomisiksi (atomic). On kuitenkin mahdollista, että kohdetyypin kohteiden attribuuteilla voi olla useampia arvoja, esimerkiksi opiskelijalla voi olla useita puhelinnumeroita tai sähköpostiosoitteita. Jos attribuutilla voi olla useampia arvoja, sitä kutsutaan moniarvoiseksi (multivalued).
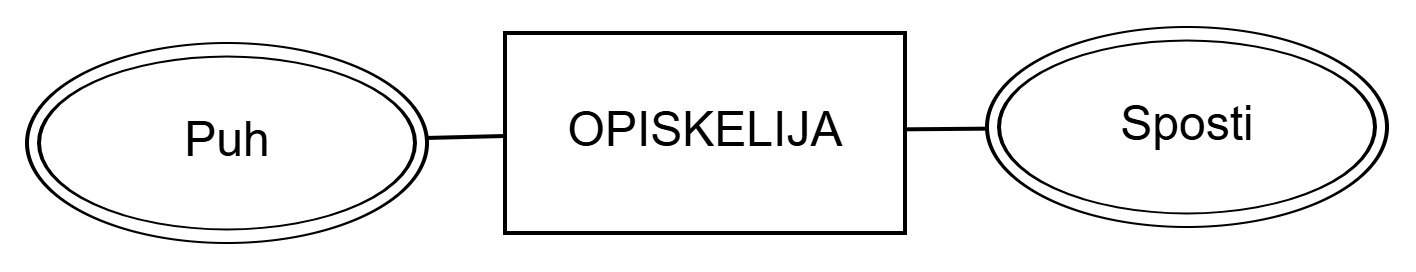
OPISKELIJA moniarvoiset attribuutit Puh ja Sposti.Moniarvoista attribuuttia merkitään yllä olevan kuvion mukaisesti kaksinkertaisella soikiolla.
Suhdetyypit
Kohteilla kuten reaalimaailman asioillakin on tyypillisesti jonkinlaisia suhteita keskenään. Suhde (relationship) on mikä tahansa yhden tai useamman kohteen välillä vallitseva riippuvuus tai muu kohdealueen kannalta kiinnostava asiayhteys. Suhteiden joukot muodostavat suhdetyyppejä (relationship set). Tietokantaa suunnitellessa relevantit suhteet kohteiden välillä on tunnistettava ja kuvattava ne ER-kaavioon.
Suhdetyyppejä kuvataan ER-notaatiossa vaakasuunnassa käännetyllä salmiakkikuviolla, joka on liitetty suhteeseen osallistuviin kohdetyyppeihin. Suhdetta kuvataan tavallisesti jollakin yksikön 3. persoonan verbillä. Tässä materiaalissa suhteet pyritään kirjoittamaan samalla kirjoitusasulla kuin attribuutit, eli isolla alkukirjaimella ja ilman välilyöntejä (ns. PascalCase). Kuten aiemminkin, pieniä eroja voi löytyä kuvissa ja videoissa; käytännön merkitystä kirjoitusasulla ei ole.
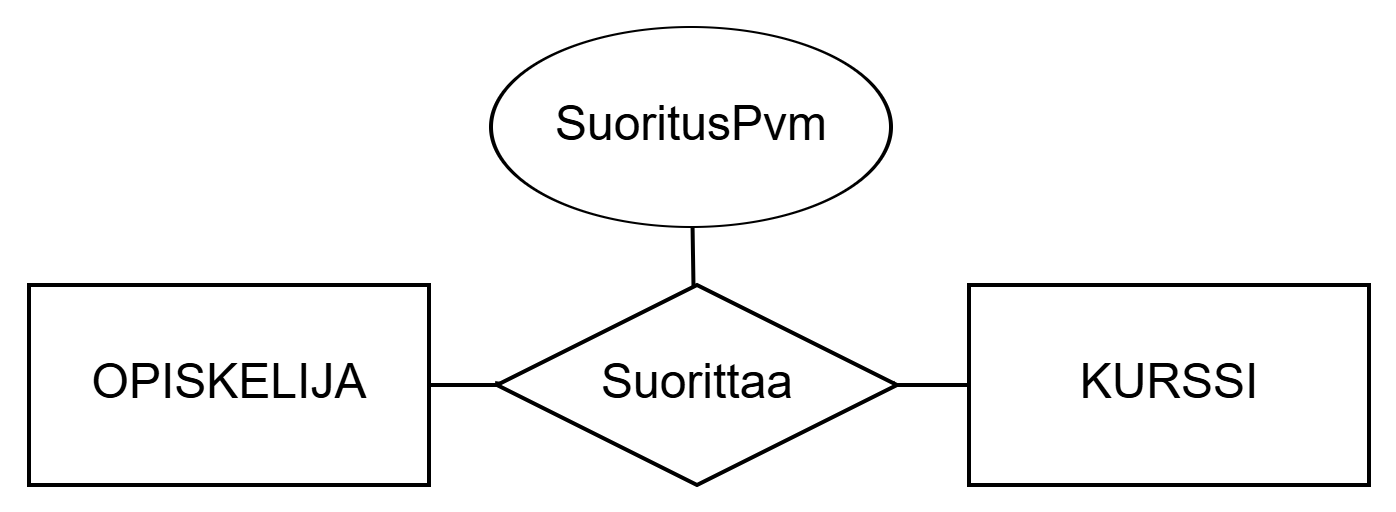
OPISKELIJA ja KURSSI välinen suhdetyyppi Suorittaa. Suhdetyyppiin liittyy attribuutti SuoritusPvm kuvaamaan kurssin suorituksen päivämäärää.Myös suhdetyypeillä voi olla attribuutteja. Suhdetyypin attribuutit kuvaavat jotakin suhteen ominaisuutta, esimerkiksi yllä olevan esimerkin SuoritusPvm. Suorituspäivämäärä ei liity kohdetyyppiin KURSSI, eikä kohdetyyppiin OPISKELIJA, vaan kohdetyyppien väliseen suhteeseen.
Suhteen asteluku
Suhdetyypin, johon osallistuu kohdetyyppiä, sanotaan olevan asteluvultaan (degree) . Yllä kuvatun suhdetyypin asteluku on 2, ts. suhdetyyppi on binäärinen. Kahdella kohdetyypillä voi olla keskenään useampi kuin yksi binäärinen suhdetyyppi. Suhdetyypin asteluku voi olla mikä tahansa kokonaisluku 1..n. Alla on kuvattu unaarinen (asteluku 1) ja tertiäärinen (asteluku 3) suhdetyyppi.
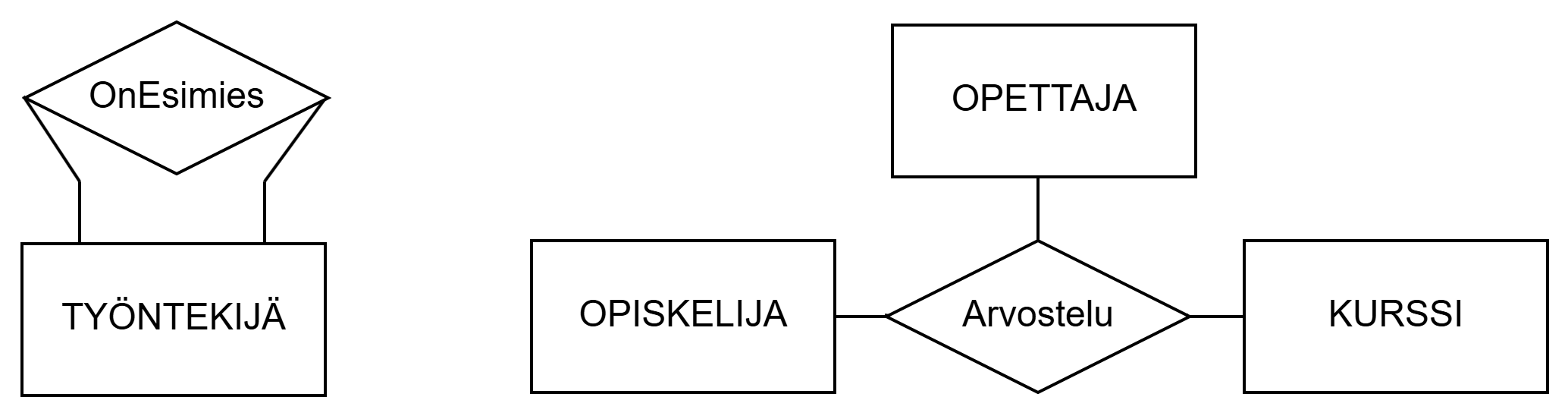
Yllä olevan kuvion mukaan työntekijä voi olla esimies muille työntekijöille. Toisessa esimerkissä kohdealueen kannalta on tärkeää, että tiedetään, kuka opettaja opiskelijan kurssisuorituksen on arvostellut.
Huomautus
Asteluvultaan kahta korkeammilla suhdetyypeillä on omat ongelmansa, eikä niitä juurikaan tässä materiaalissa käsitellä.
Yllä olevan esimerkin voisi toteuttaa heikolla kohdetyypillä ARVOSTELU. Heikkoa kohdetyyppiä käsitellään hieman myöhemmin.
Kardinaliteetti
Kardinaliteetti (tai kardinaalisuus) kertoo, kuinka moneen tietyn tyyppiseen suhteeseen kohde osallistuu tai voi osallistua. Kardinaalisuuksia on kahdenlaista: minimikardinaalisuus (eli pakollisuus) kertoo pienimmän tarvittavan kohteiden määrän suhteeseen, kun taas maksimikardinaalisuus kertoo suurimman sallitun kohteiden määrän.
Tässä materiaalissa käsitellään notaatio, jossa minimikardinaalisuus on joko 0 tai 1 ja maksimikardinaalisuus on joko 1 tai N. Toisin sanoin kohdetyypin kardinaalisuus suhteessa voidaan esittää neljällä tavalla:
| Max. 1 | Max. N | |
|---|---|---|
| Min. 0 | 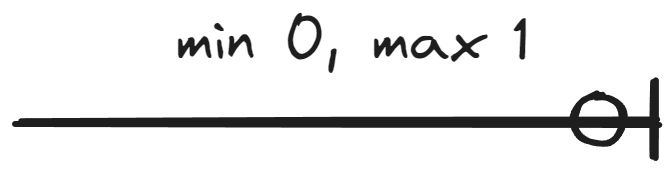 |
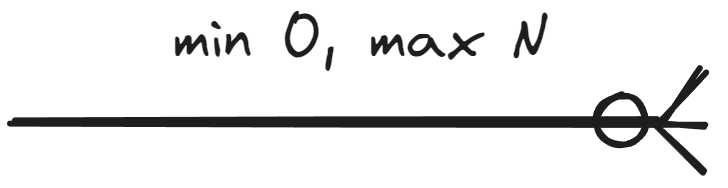 |
| Min. 1 | 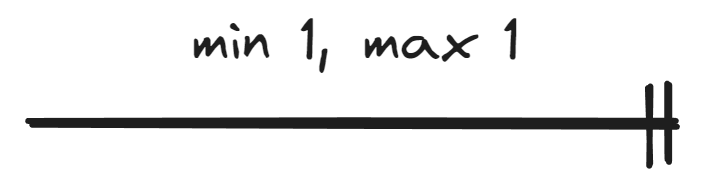 |
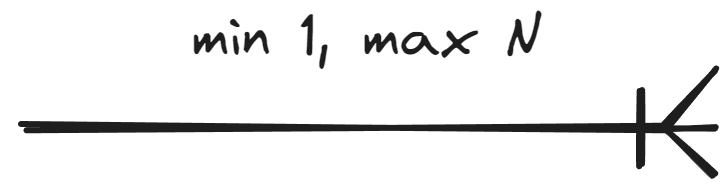 |
Kohdetyypin kardinaalisuus merkitään sille puolelle suhdetta, johon päin luetaan.
Esimerkki
Mietitään kardinaalisuuksia seuraavassa kohdealueessa: halutaan suunnitella autorekisteri, jossa pidetään kirjaa autoista ja niitä omistavista henkilöistä.
Tässä tapauksessa on kaksi kohdetyyppiä HENKILÖ ja AUTO sekä niiden välinen suhde Omistaa. Suhteen kardinaliteetti on kohdealueen perusteella järkevintä valita seuraavasti:
- Henkilö ei välttämättä omista autoa, mutta voi omistaa useita. Siispä minimikardinaalisuus on 0 ja maksimikardinaalisuus on N.
- Autolla on aina täsmälleen yksi omistaja. Minimikardinaalisuus on siten 1 ja maksimikardinaalisuus on 1.
Käyttämällä yllä olevaa taulukkoa avuksi saadaan seuraava ER-malli:

HENKILÖ ja AUTO välinen suhde Omistaa kardinaliteettimerkintöineen.Huomioi lukusuunta:
- Vasemmalta oikealle: "Henkilö omistaa nollasta moneen autoa"
- Oikealta vasemmalle: "Autoa voi omistaa vähintään yksi ja korkeintaan yksi henkilö"
Lukusuunta on merkitty selkeämmin alle:
Merkintöjä voi miettiä esimerkkikohteiden kautta. Kuvitellaan seuraava esimerkki, jossa on kolme henkilöä ja neljä autoa. Tällöin auton ja henkilön omistussuhde voisi näyttää seuraavalta:
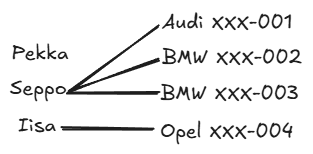
Koska jokaisesta autosta menee aina yksi viiva johonkin henkilöön, valitaan HENKILÖ-kohdetyypin puolelle minimikardinaalisuus 1 (pystyviiva) ja maksimikardinaalisuus 1 (pystyviiva). Vastaavasti, koska jostain henkilöstä ei lähde mitään viivaa autoon, valitaan AUTO-kohdetyypin puolelle minimikardinaalisuus 0 (ympyrä). Koska yhdestä henkilöstä lähtee useampi viiva eri autoon, maksimikardinaalisuus on N (haarautuvat viivat).
Huomautus
Yllä kuvattu kardinaliteetin merkintätapa on ns. Hoffer-Prescott-McFadden notaatio, joka on suosittu monissa tietokannanhallintajärjestelmien rinnalla käytetyissä 3. osapuolen suunnittelutyökaluissa.
Muita yleisesti käytettyjä kardinaalisuusnotaatioita on kuvattu alla: vasemmalla Chenin notaatio, keskellä UML:ää muistuttava notaatio ja oikealla materiaalissa käytetty Hoffer, Prescott & McFaddenin notaatio.
![Kuvio: Erilaisia kardinaalisuusnotaatioita: Chen [5]; UML [32]; Hoffer, Prescott & McFadden [19].](/files/kurssit/tie/itka2004/course/sections/2/02_ch22_er_mallinnus/3a3763c774f3886ae79be3a895da1d737006aec8.png)
Heikko kohdetyyppi ja tunnistava suhdetyyppi
Jos kohdetyypin mukaisia kohteita ei voida tunnistaa sen omien attribuuttien avulla, sitä sanotaan heikoksi kohdetyypiksi (weak entity set). Heikkoa kohdetyyppiä merkitään kaksoissuorakulmiolla. Heikon kohdetyypin mukaiset kohteet tunnistetaan toisen kohdetyypin avainattribuutteja hyväksi käyttäen, ja tällaista kohdetyyppiä kutsutaan tunnistavaksi kohdetyypiksi (identifying entity set). Tunnistava kohdetyyppi kuvataan tunnistavan suhdetyypin (identifying relationship set) avulla. Tunnistava suhdetyyppi kuvataan kaksoissalmiakilla.
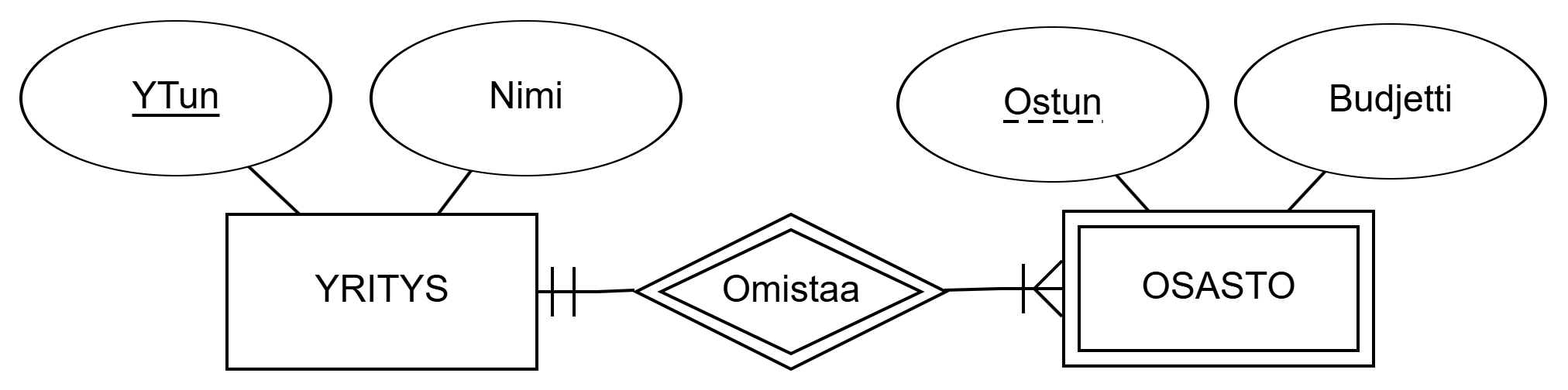
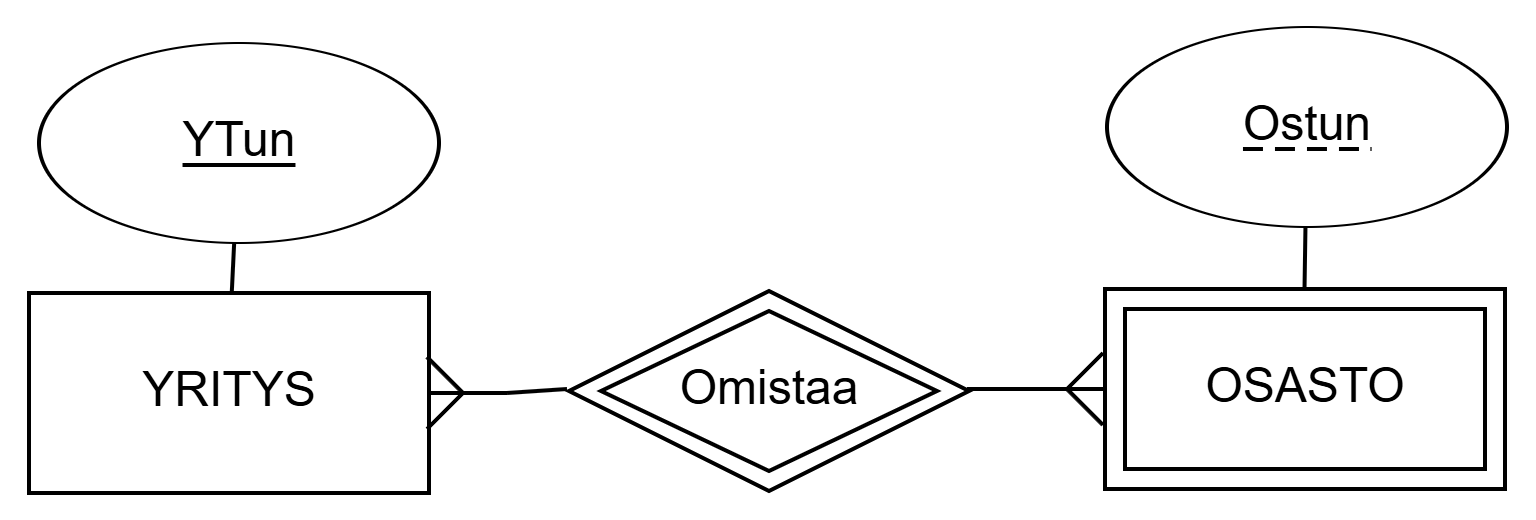
OSASTO ja tunnistava kohdetyyppi YRITYS.Yllä olevassa kuviossa heikko kohdetyyppi OSASTO tunnistetaan vahvan kohdetyypin YRITYS avulla. Heikon kohdetyypin avainattribuutin nimi alleviivataan katkoviivalla. Yllä kuvatun kohdealueen osastot tunnistetaan siis osaston tunnuksen ja yritystunnuksen yhdistelmällä. Toisin sanoin tietokannassa voi olla kaksi osastoa, jolla on sama osastotunnus Ostun, mutta ne kuuluvat eri yritykseen. Siispä attribuuttijoukolla {YTun, Ostun} voi tunnistaa osaston yksikäsitteisesti.
Huomautus
Heikon kohdetyypin maksimikardinaalisuuden tunnistavassa suhdetyypissä tulisi yleensä olla korkeintaan 1.
Tämä ei ole rajoite, vaan pikemmin vahva suositus. Yllä olevassa kuviossa osasto voi kuulua aina korkeintaan yhteen yritykseen, ja osasto voidaan yksilöllisesti tunnistaa sen yrityksen tunnuksen ja osaston tunnuksen kautta.
Mitä jos osasto saisikin kuulua kahteen eri yritykseen? Miten osasto silloin tunnistettaisiin? Voidaanko osasto silloin yksilöllisesti tunnistaa kahdella tavalla: {YTun1, Ostun} ja {YTun2, Ostun}? Vai tarvitaanko osaston tunnistamiseksi kummankin yrityksen tunnukset: {YTun1, YTun2, Ostun}? ER-notaatio ei tarjoa eri vaihtoehdoille selkeitä merkintöjä, eikä näitä saa helposti muunnettua tietokannan loogiseksi rakenteeksi. Siispä on parempi ottaa nyrkkisäännöksi, että heikko kohdetyyppi voi kuulua korkeintaan yhden kerran tunnistavaan suhteeseen.
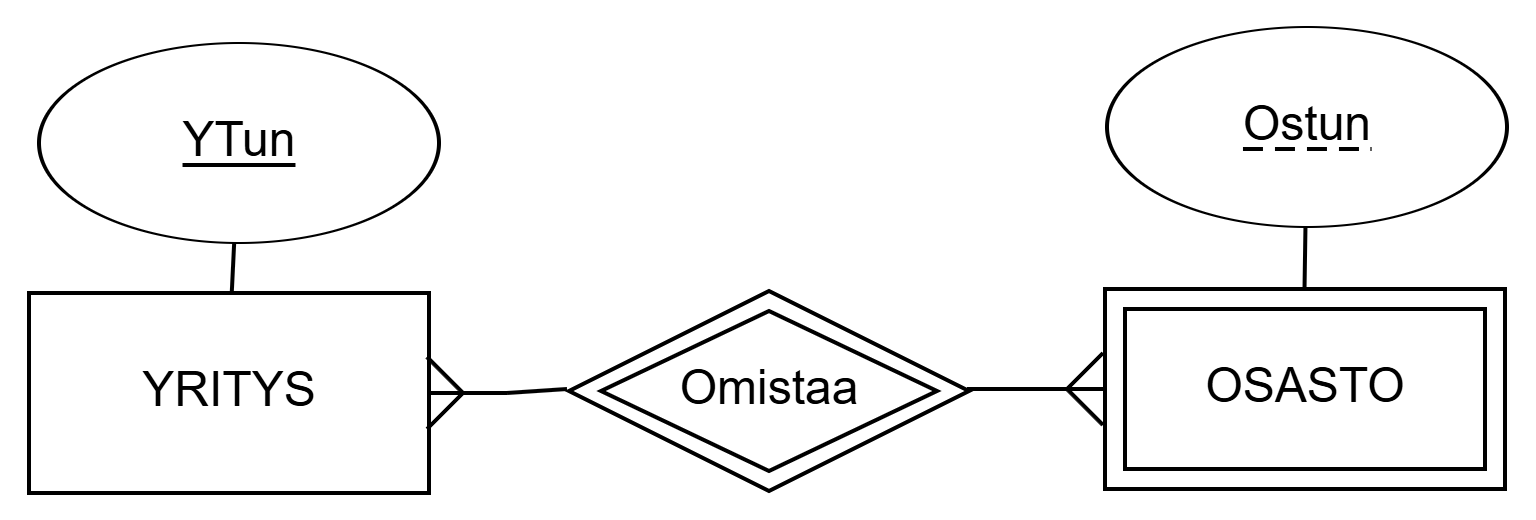
OSASTO-kohdetyypin tunnistamiseksi voidaan tarvita N yritystä. Tämän mallintaminen loogisella tasolla on hankalaa.Tällaisissa tapauksissa voi olla helpompaa muuttaa heikko kohdetyyppi tavalliseksi kohdetyypiksi.
Abstraktiorakenteet
ER-notaatiota on myöhemmin täydennetty. Yksi tällaisista täydennyksistä on nk. EER-notaatio (extended tai enhanced ER), joka lisää notaatioon mm. abstraktiorakenteet. Abstraktiorakenteiden avulla voidaan mallintaa hierarkioita ja oliosuuntautuneisuuden mukaista perintää: alikohdetyypit perivät ylikohdetyyppinsä attribuutit. Kohdetyyppien välistä perintää merkitään seuraavan kuvion mukaisesti.
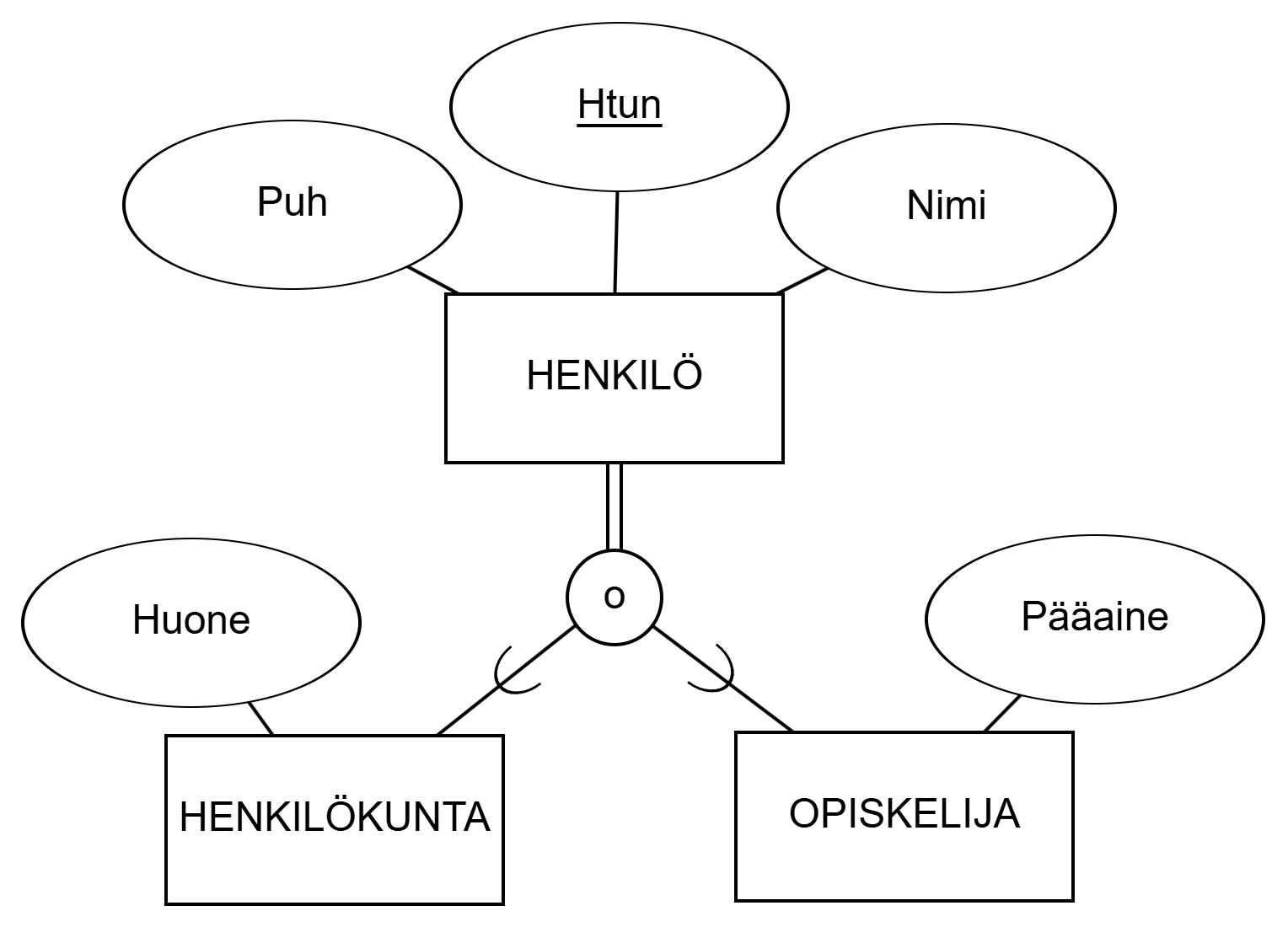
HENKILÖKUNTA ja OPISKELIJA perivät ylikohdetyypin HENKILÖ attribuutit.Ylikohdetyyppinä on kuviossa HENKILÖ, alikohdetyyppeinä OPISKELIJA ja HENKILÖKUNTA. U-kirjaimen muotoiset merkinnät osoittavat alikohdetyyppeihin. Ympyrä yhdistetään ylikohdetyyppiin joko yksi tai kaksi viivaa riippuen alikohteiden kattavuudesta. Abstraktiorakenteet voivat muodostaa monimutkaisempiakin hierarkioita.
Ympyrän sisälle on merkitty joko kirjain d tai o riippuen siitä, onko abstraktio erillinen (disjoint) tai leikkaava (overlapping). Tarkastellaan seuraavaksi näitä kahta erilaista EER-notaation mukaista yleistysrakennetta.
Erillinen
Erillisellä (disjoint) abstraktiorakenteella tarkoitetaan, että alikohteet voivat kuulua korkeintaan yhteen alikohdetyyppiin (ns. joko-tai -abstraktio). Esimerkiksi AJONEUVO voi olla joko AUTO tai VENE. Erillistä abstrahointia merkitään ympyrän sisälle sijoitetulla kirjaimella d.
Alikohdetyyppijoukon kattavuutta kuvataan yhdellä tai kahdella viivalla ympyrän ja ylikohdetyypin välillä:
- yksi viiva (osittainen abstraktio): tietyn kohteen ei tarvitse olla yhdenkään alikohdetyypin mukainen kohde (esim. kohdealueessa voi esiintyä ajoneuvoja, jotka eivät ole autoja eikä veneitä, kuten moottoripyörät);
- kaksi viivaa (kattava abstraktio): kaikki kohteet kuuluvat johonkin alikohdetyyppiin (esim. kohdealueessa kaikki esiintyvät ajoneuvot ovat joko autoja tai veneitä).
Alla oleva kuvio kiteyttää, mitä kohteita erillinen ja kattava sekä erillinen ja osittainen abstraktiorakenne voi mallintaa.
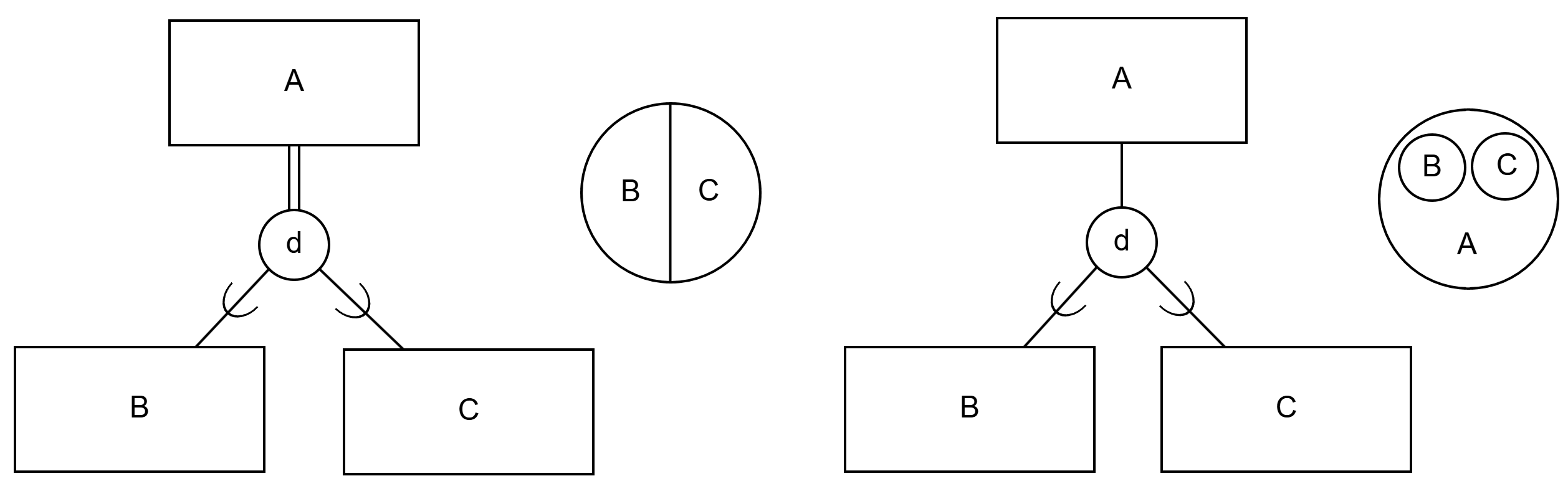
A voi olla joko B tai C"). Oikealla erillinen ja osittainen yleistyssuhde ja kohteiden suhde toisiinsa ("kohteet A voi olla B tai C tai jotakin muuta").Leikkaava
Leikkaavalla (overlapping) abstraktiorakenteella tarkoitetaan, että alikohteet voivat kuulua useampaan kuin yhteen alikohdetyyppiin (ns. "sekä-että" -abstraktio). Esimerkiksi huone voi olla sekä keittiö että ruokasali. Leikkaavaa abstraktiorakennetta kuvataan ympyrän sisään sijoitetulla kirjaimella o. Kuten erillinen, myös leikkaava abstraktiorakenne on joko kattava tai osittainen. Esimerkiksi:
- yksi viiva (osittainen abstraktio): kohdealueessa voi esiintyä ajoneuvoja, jotka ovat joko autoja, veneitä tai molempia tai jotakin muuta;
- kaksi viivaa (kattava abstraktio): kohdealueessa kaikki ajoneuvot ovat joko autoja, veneitä tai molempia.
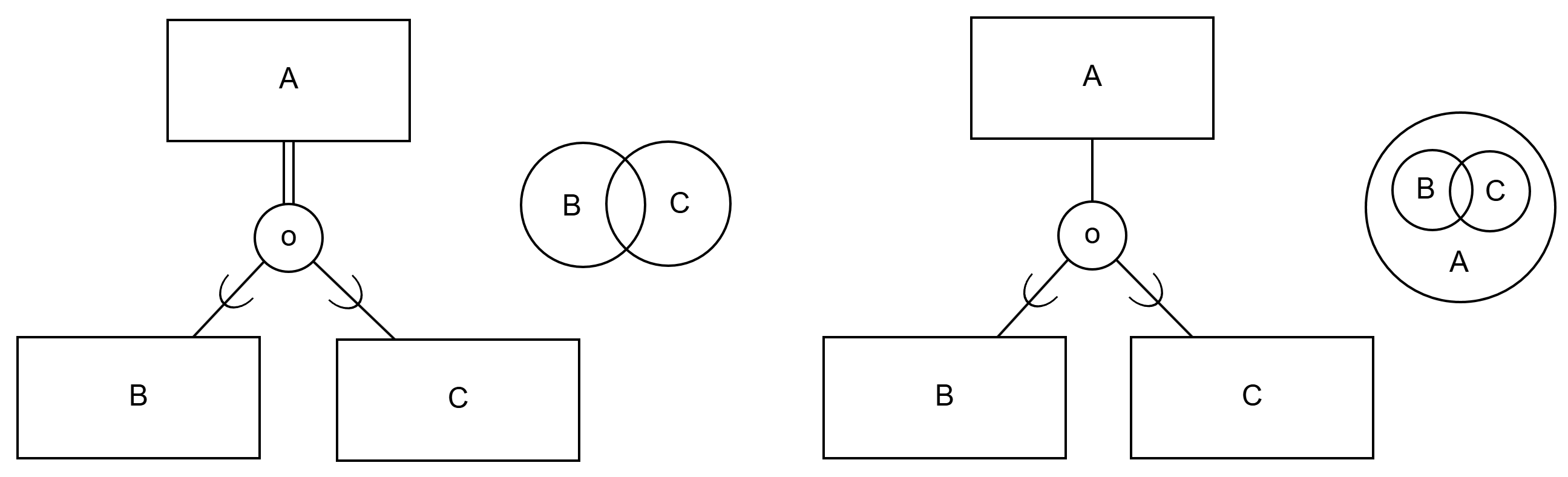
A voivat olla B tai C tai molempia samaan aikaan"). Oikealla leikkaava ja osittainen yleistyssuhde ja kohteiden suhde toisiinsa ("kohteet A voivat olla B, C, molempia tai jotakin muuta").Monivalintatehtävät liittyvät seuraavaan ER-kaavioon:
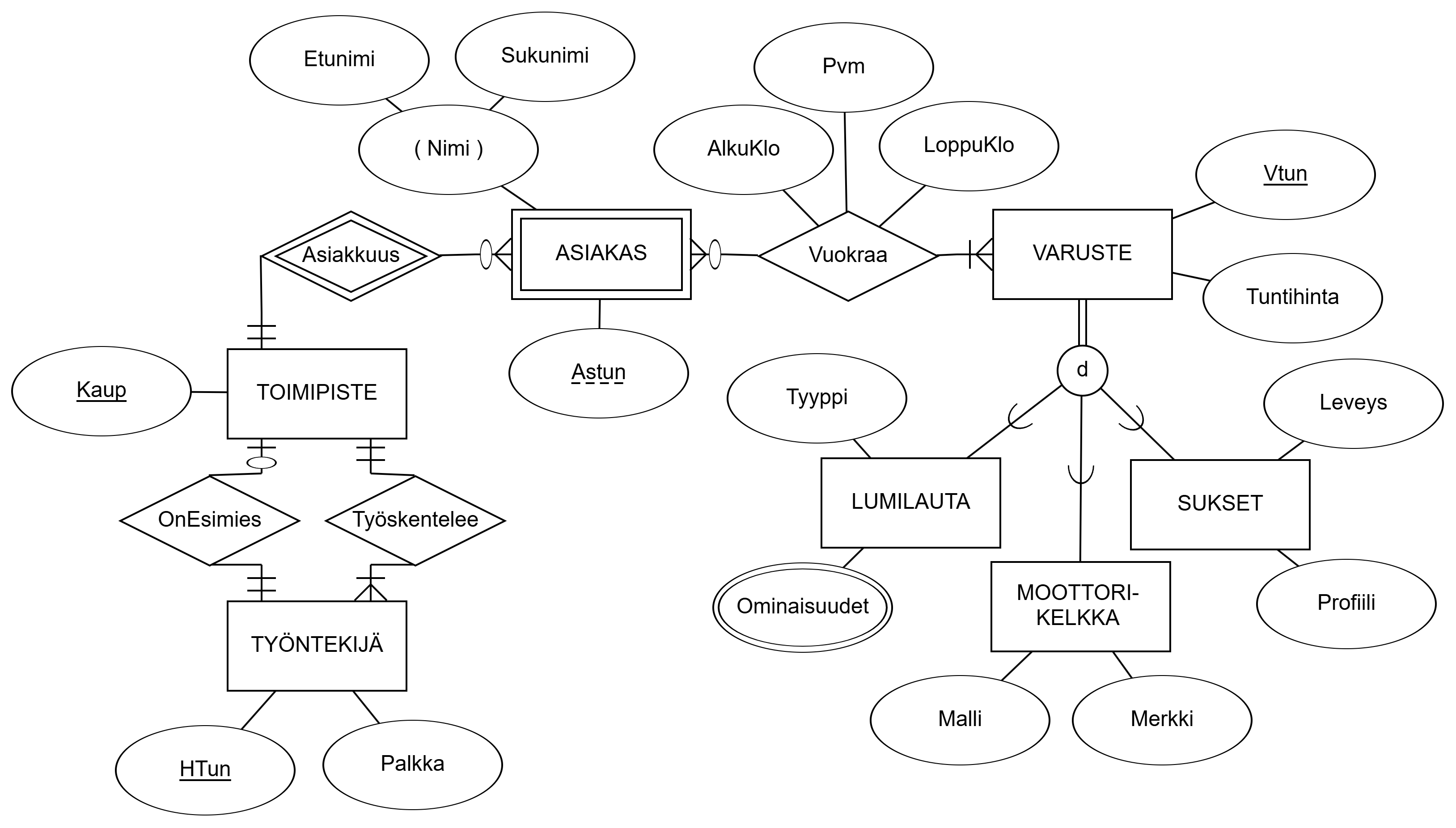
Käsitteellisen mallintamisen vaiheet
Käsitteelliselle mallintamiselle ei ole tarkkaan standardoitua prosessia. Alla on joitain vinkkejä siitä, miten mallintamista kannattaa lähestyä:
Laadi vaatimusmäärittely, ellei sitä ole jo olemassa. Vaatimusmäärittelystä tulee käydä selväksi kohdealue, toteutettavan järjestelmän tarpeet ja siihen liittyvät keskeiset käsitteet.
Aloita tunnistamalla peruskohdetyypit vaatimusmäärittelystä.
- Etsi muun muassa toistuvia käsitteitä, jotka ovat konkreettisia asioita (esim. tuote, asiakas) tai käsitteellisiä asioita (esim. tilaus, tilausrivi)
- Liittyykö käsitteeseen sellaista tietoa, jota oikeasti halutaan tallentaa tietokantaan?
- Anna kohdetyypeille selkeät nimet ja tarvittaessa kuvaile niiden merkitys.
- Huom: jos jokin tieto on johdettavissa jonkin muun tietokannan tiedon kautta, sitä ei kannata mallintaa. Esimerkiksi erilaiset raportit, tulosteet ja analytiikat voidaan johtaa suoraan muista kohdetyypeistä.
Tunnista seuraavaksi keskeiset suhdetyypit ja niiden kardinaliteetit.
- Keskity suhteisiin, jotka ovat tietokannan kannalta relevantteja.
- Yleisimmät suhteet koskevat olemassaoloa, toimintaa tai tapahtumaa.
- Onko suhdetta mielekästä tallentaa tietokantaan (esim. kuka tulosti minkä raportin, kuka osti mitäkin)?
- Joudut tekemään mahdollisesti lisäoletuksia kardinaliteettien määrittämiseksi.
Tunnista attribuutit.
- Mitä ominaisuuksia halutaan oikeasti tallentaa tietokantaan?
- Jotkin ominaisuudet voivat olla johdettavissa muista ominaisuuksista.
- Valitse sopiva avainattribuutti. Jos sellaista ei löydy, luo jokin
Tunnus-attribuutti (esim. juokseva numero, joka yksilöi kohteet). - Merkitse erikoisattribuutit oikein (moniarvoiset, johdetut, kootut).
Iteroi ja refaktoroi.
- Lisää uusia kohteita, attribuutteja tai suhteita, jotka ilmenevät mallintamisprosessin aikana. Muista tarvittaessa täydentää myös vaatimusmäärittely.
- Voiko kohdetyyppejä ja attribuutteja nimetä paremmin?
- Kuuluvatko jotkin attribuutit paremmin suhteeseen kuin kohdetyyppiin?
- Ovatko kardinaliteetit merkitty kohdealueen kannalta järkevästi?
- Käytä tarvittaessa abstraktiorakenteita selventämään mallia, erityisesti jos usealla kohteella on samoja attribuutteja.
Esimerkki
Tehdään alla olevan kuvauksen mukainen ER-kaavio, josta ilmenevät kohdetyypit, suhdetyypit, olennaisimmat attribuutit, avainattribuutit sekä minimi- ja maksimikardinaalisuudet.
- Tietokanta sisältää tietoja asiakkaista: asiakastunnus, nimi, osoite.
- Asiakkaat tilaavat tiettyinä päivinä tuotteita, joilla on tuotenumero, tuotenimi ja hinta.
- Tilaus tunnistetaan tilausnumerolla.
- Tilaus voi koskea useampia tuotteita (tiettyjä määriä).
Tunnistetaan alkuun kaikki peruskohdetyypit (käsitteet, asiat, käsitteelliset asiat), suhdetyypit (käsitteisiin liittyvät relevantit verbit) ja attribuutit (käsitteisiin liittyvät ominaisuudet).
Tunnistetut KOHTEET, Attribuutit ja Suhteet merkittyinä kuvaukseen:
- Tietokanta sisältää tietoja
ASIAKAS:ista:Asiakastunnus,Nimi,Osoite. - Asiakkaat Tilaavat tiettyinä päivinä
TUOTE:ita, joilla onTuotenumero,TuotenimijaHinta. TILAUStunnistetaanTilausnumerolla.- Tilaus voi Koskea useampia tuotteita (tiettyjä
Määriä).
Kardinaalisuuksia ei voi täysin päätellä annetun kuvauksen perusteella. Tässä tapauksessa tehdään muutama kohdealueen kannalta järkevä lisäoletus:
- Asiakas voi olla olemassa ilman tilauksia (esim. verkkokauppa).
- Jokaista tilausta tekee tasan yksi asiakas.
- Tilauksessa on aina jokin tuote (toisaalta: voisiko olla järkevää, että voisi olla? Mieti esim. verkkokauppa, jossa ostoskori on alussa tyhjä.)
- Tuotetta ei välttämättä ole ikinä tilattu ennen, eli se ei ole missään tilauksessa.
Näiden perusteella saadaan mallinnettua lopullinen ER-kaavio.
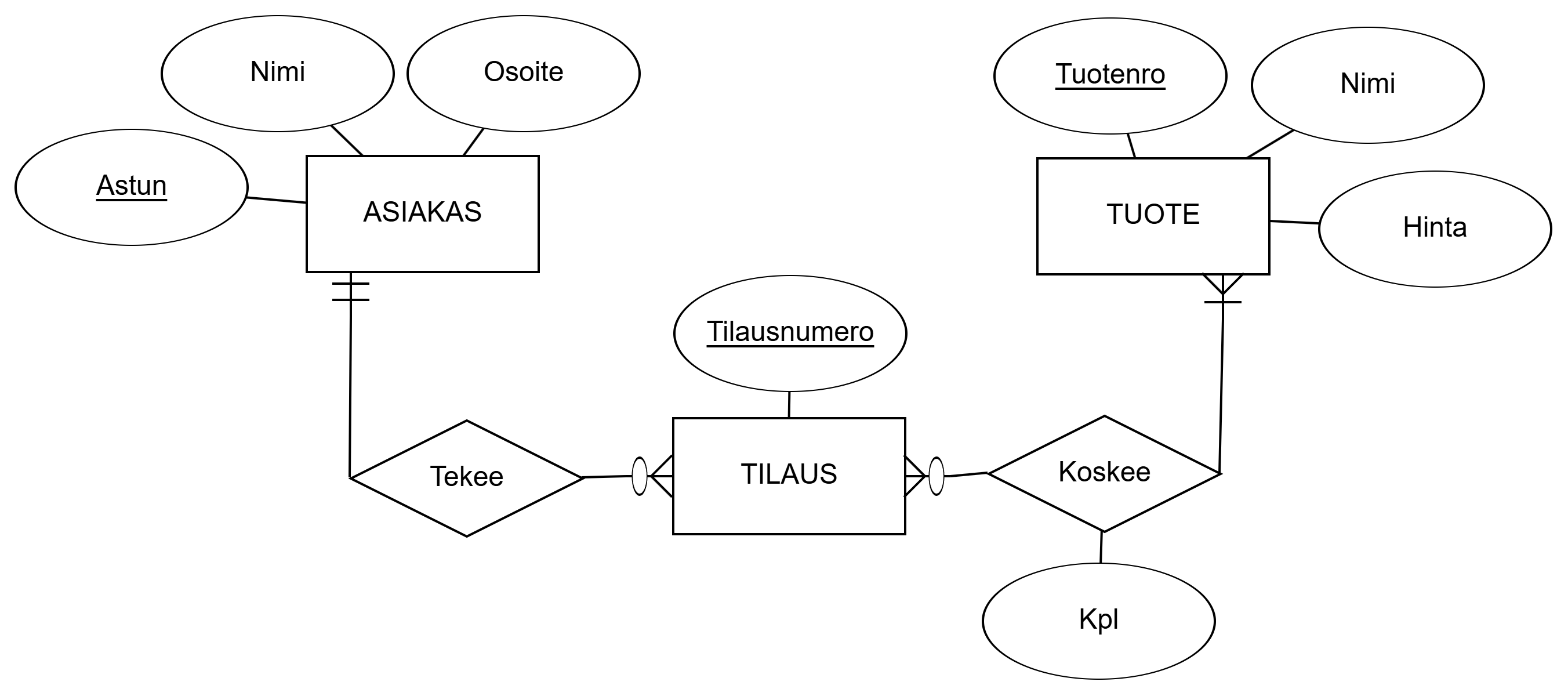
Huomioita:
- Pyri pitämään mallit yksinkertaisina. Heikot kohdetyypit, kootut attribuutit ja tertiääriset suhteet usein vaikeuttavat suunnittelua. Paras ratkaisu on yleensä yksinkertaisin!
- Vastaavasti samalle vaatimusmäärittelylle voisi olla monia eri päteviä ER-kaavioita. Myöhemmissä luvuissa huomataan, että erilaisetkin ER-kaaviot voivat tuottaa lopuksi samanlaisen tietokannan rakenteen.
- Vaatimusmäärittelyt ovat harvoin täydellisiä. Mieti, mitä tietoa puuttuu ja tarkenna vaatimusmäärittelyä. Tarvittaessa joudut tekemään kohdealueen tai sovelluksen kannalta järkeviä lisäoletuksia. Tässä esimerkissä esim.
TILAUSei voi olla ilman tuotteita, mutta jossain sovelluksissa tämä voisi olla taas järkevääkin.
These are the current permissions for this document; please modify if needed. You can always modify these permissions from the manage page.