Muut tietokantaparadigmat
Luku videona
Päivitys 1.6.2024: Vanhat luentovideot on poistettu edellisen vastuuopettajan pyynnöstä. Uudet videot julkaistaan keväällä 2025.
Luku tekstinä
Tässä luvussa esitellään tietomalleja, joita käytetään tietokannoissa, ts. tietokantaparadigmoja. Tähän mennessä kurssimateriaali on keskittynyt relaationaaliseen tietokantaparadigmaan, ja tässä luvussa esitellään yleisellä tasolla kuusi muuta tietokantaparadigmaa: oliosuuntautunut, oliorelaationaalinen, avain-arvopari, dokumentti, graafi ja sarakeperhe.
8.1 Oliosuuntautunut
Oliotietokanta (object database) on oliosuuntautunutta ohjelmointiparadigmaa noudattava tietokanta. Oliotietokantaa käyttävästä tietokannanhallintajärjestä käytetään nimitystä oliotietokannanhallintajärjestelmä (Object-Oriented Database Management System, OODBMS).
8.1.1 Keskeiset käsitteet
Oliotietokannoilla ei ole yleistä tai formaalia mallia tai standardia, kuten relaatiotietokantojen relaatiomalli. Toisaalta relaatiomalli tarjoaa perustan vain osalle RDBMS:n toiminnoista ja oliotietokantojen taustalla vaikuttavat oliosuuntautuneen ohjelmoinnin vakiintuneet käsitteet. Oliotietokantoja on yrittänyt standardisoida Object Data Management Group, Object Management Group ja Object Database Technology Working Group, mutta standardit ovat jääneet keskeneräisiksi tai niitä ei ole otettu laaja-alaisesti käyttöön.
Oliosuuntautunut ohjelmointi on ohjelmointiparadigma, jonka mukaan sovellus jaetaan olioihin. Oliot omistavat dataa ja käyttäytymisen, joiden avulla olio toimii ja kommunikoi järjestelmän muiden olioiden kesken. Seuraavaksi on lyhyesti selitetty oliosuuntautuneisuuteen liittyvät peruskäsitteet oliotietokantojen näkökulmasta. Peruskäsitteiden ymmärtäminen auttaa ymmärtämään oliotietokannan tietomallin. Määritelmät perustuvat Bertinon & Martinon (1993, s. 12-34) esitykseen. Jos oliokeskeiset käsitteet ovat tuttuja, voit siirtyä seuraavaan alalukuun 8.1.2.
Olio (object) on reaalimaailman asiaa tai käsitettä kuvaava osa järjestelmää. Jokaisella oliolla on yksilöivä tunniste (Object Identifier, OID), joka määrää olion identiteetin. Olioilla on dataa eli attribuutteja arvoineen. Attribuutin arvo voi olla yksinkertainen, kuten kokonaisluku tai arvo voi olla toinen olio tai olioiden joukko. Attribuuttien arvot kuvastavat olion tilaa (state).
Kapselointi (encapsulation) tarkoittaa, että oliolla on sekä metodit että rajapinta joilla oliota voidaan tarkastella ja muokata. Metodit koostuvat nimestä (signature) ja toteutuksesta (implementation): metodin nimeä kutsumalla metodin toteutus suoritetaan. Olion rajapinta on joukko metodeja, joita kutsumalla olio voi toimia. Olion metodit kuvastavat olion käytöstä (behaviour).
Näkyvyysalue (scope) määrää attribuutti- ja metodikohtaisesti, mikä olio voi lukea ja muuttaa attribuutin arvoja tai kutsua metodia.
Luokka (class) on olioiden joukko. Kaikki oliot, joilla on samat attribuutit ja metodit, kuuluvat samaan luokkaan. Kaikki oliot kuuluvat johonkin luokkaan. Olio, joka kuuluu luokkaan X sanotaan olevan luokan X instanssi.
Perintä (inheritance) tarkoittaa, että luokka voi olla yhden tai useamman muun luokan instanssi ja periä näiden luokkien attribuutit ja metodit. Näin määriteltyä luokkaa kutsutaan aliluokaksi (subclass) ja luokkia, jotka aliluokan määrittävät kutsutaan yliluokiksi (superclass).
Ylikuormituksella (overloading) tarkoitetaan, että saman nimisellä metodilla voi olla useita toteutuksia. Näin järjestelmä voi päättää, mitä metodin toteutusta käytetään minkäkin operaation suorittamiseksi.
Olioiden pysyvyydellä (persistence) tarkoitetaan sitä, millaisella politiikalla oliot tallennetaan ja poistetaan oliotietokantaan. Yleistäen voidaan sanoa, että oliokeskeisessä tietojärjestelmässä oliot ovat olemassa muistissa. Usein olioita on kuitenkin tarve tallentaa tietokantaan massamuistiin, jotta ne säilyvät ja jotta muistia vapautuu muiden olioiden käyttöön. Muistissa sijaitsevaa oliota kutsutaan lyhytkestoiseksi (volatile) ja levyllä sijaitsevaa oliota pysyväksi (persistent). Pysyvyyden ratkaisemiseen on lähtökohtaisesti kolme tapaa (Bertino & Martino, 1993, s. 25-26):
- Ensimmäisen lähestymistavan mukaan järjestelmän kaikki oliot ovat implisiittisesti pysyviä. Tällöin kun uusi olio luodaan, se tallennetaan tietokantaan.
- Toisen lähestymistavan mukaan pysyvyys on eksplisiittinen piirre. Tällöin olion luonnin yhteydessä sitä ei tallenneta tietokantaan ja sen elinkaaren päätteeksi olio tuhotaan pysyvästi, ellei oliota ole erityisesti muutettu pysyväksi. Tämän lähestymistavan vahvuutena voidaan pitää joustavuutta ja heikkoutena monimutkaisuutta.
- Kolmannen lähestymistavan mukaan pysyvyys on jotakin kahden edellisen väliltä. Esimerkiksi osa järjestelmän luokista takaa niihin kuuluvien olioiden pysyvyyden, kun taas toisten pysyvyys on määrättävä oliokohtaisesti.
Olion attribuutin arvo voi olla viite toiseen olioon tai toisiin olioihin. Olioiden poistamiseen liittyy viitteiden käsittely, jolle on kaksi tapaa. Ensimmäisen tavan mukaan olioiden poistaminen sallitaan vain, jos mikään toinen olio ei viittaa poistettavaan olioon. Toisen tavan mukaan olioiden poistaminen sallitaan vapaasti, ja viittaukset poistettuihin olioihin aiheuttavat poikkeuksen. Tämän tavan mukaan olioiden poistoon ei ole erillistä operaatiota, ja pysyvä olio poistetaan vain, jos kaikki ulkoiset nimet ja viittaukset, johon pysyvä olio viittaa, poistetaan.
8.1.2 Olio-relaatioyhteensopimattomuus
Tietokantajärjestelmässä, jossa tietokannanhallintajärjestelmä on relaationaalinen ja sovellusohjelma oliosuuntautunut voidaan pitää etuna sitä, että järjestelmän tietokanta on selvästi erotettavissa sovellusohjelmasta: tietokanta nähdään relaatioina ja sovellusohjelma olioina. Oliotietokannoilla on kuitenkin joitakin ominaisuuksia, jotka relaatiotietokannoilta puuttuvat:
- Monimutkaiset tietorakenteet: relaatiotietokannoissa yksi asiakokonaisuus on tavallisesti jaettuna useaan tauluun, esim. asiakas ja hänen tilaamansa tuotteet ovat yhteensä neljässä taulussa: asiakas, tilaus, tilausrivi ja tuote.
- Tietueisiin voidaan liittää operaatioita.
- Tietueiden käytös ei muutu sovellusohjelman tarpeiden mukaan, vaan käytös on tallennettu tietueeseen.
- Tietueella on identiteetti, joka on erillään tietueen tilasta.
Yllä mainittujen ominaisuuksien puuttumisen lisäksi relaatiotietokannanhallintajärjestelmän ja oliosuuntautuneen sovellusohjelman liittäminen voi johtaa tunnistettujen ongelmien ja epäjohdonmukaisuuksien joukkoon nimeltä olio-relaatioyhteensopimattomuus (object-relational impedance mismatch). Yhteensopimattomuus ei sinänsä tarkoita, että RDBMS ei sovi yhteen oliosuuntautuneen sovellusohjelman kanssa, vaan että niiden yhteenliittäminen voi olla virhealtista ja työlästä. Alla olevaan taulukkoon on koottu potentiaaliset ongelmatilanteet.
| Ongelma | Kuvaus |
|---|---|
| Kapselointi | Olion rajapinnan kautta käsiteltävä data asetetaan tietokannassa näkyviin. |
| Kyselyt | SQL on korkean tason kieli. Ohjelmointikieli on matalatasoisempi. |
| Näkyvyysalueet | Käyttöoikeudet ovat tietokannassa suhteellisia, mutta olioilla absoluuttisia. |
| Perintä | Perintää ei voida helposti mallintaa tietokannassa. |
| Rakenne | Oliot voivat olla rakenteeltaan monimutkaisempia kuin tietokannan rivit. |
| Suhteet | Olioiden välisiä suhteita ei voida välttämättä kuvata viiteavaimilla. |
| Tietotyypit | Tietokannassa on erilaiset tietotyypit ja ne toimivat eri tavalla kuin sovellusohjelmassa. |
Olio- tai NoSQL-tietokannat voivat olla yksi ratkaisu yllä esitettyihin ongelmatilanteisiin. Toinen vaihtoehto on yrittää suunnitella sovellusohjelma relaatiotietokannan ehdoilla. Kolmas vaihtoehto on valita RDBMS:ksi jokin oliosuuntautuneita ominaisuuksia tukeva tuote, ts. oliorelaationaalinen tietokannanhallintajärjestelmä (Object-Relational Database Management System, ORDBMS). Neljäs vaihtoehto ovat ns. ORM-työkalut (Object-Relational Mapper), jotka pyrkivät helpottamaan sovellusohjelman ja RDBMS:n yhteenliittämistä.
8.1.3 Kyselykielet
Oliotietokannoilla ei ole yhteistä standardoitua kyselykieltä kuten SQL, vaan nykyään on tavallista, että kyselyt tehdään isäntäkielellä, ns. natiivikyselyinä. Eräs tunnettu kyselykomponentti on Microsoftin LINQ (Language Integrated Query) .NET-kieliin, jolla voidaan suorittaa erilaisia lausekkeita kokoelmiin. Tällainen kokoelma voi olla esimerkiksi relaatiotietokannan relaatio tai oliotietokannan kokoelma. Alla on esitetty esimerkkejä seuraavan SQL-kyselyn vastineita muilla kielillä.
LINQ:
OODBMS GemStone, jossa on käytetty natiivikyselyä SmallTalk-ohjelmointikielellä:
OODBMS db4o (database for objects), jossa on käytetty natiivikyselyä Javalla:
Oliotietokannanhallintajärjestelmien kyselykielet voivat olla ilmaisuvoimaltaan SQL:ää heikompia, jolloin kielet voivat olla helpommin omaksuttavissa. Kyselyt voidaan tavallisesti myös toteuttaa natiivikyselyinä, jotka vastaavat ilmaisuvoimaltaan isäntäkieltä, mutta voivat olla haastavia toteuttaa. Äärimmäisessä tapauksessa varsinaista kyselykieltä ei ole lainkaan, ja OODBMS tarjoaa vain isäntäkielellä käytettävän ohjelmointirajapinnan (application programming interface, API) tallennettuihin olioihin. Tällaisista oliotietokannoista käytetään nimitystä persistent object store.
Tunnetuimpia oliotietokannanhallintajärjestelmiä ovat mm. db4o, Perst ja ObjectDB.
8.1.4 ORM-työkalut
RDBMS:n ja oliosuuntautuneen järjestelmän yhteenliittämisen ongelmia koskevassa luvussa mainittiin ORM-työkalut (Object-Relational Mapper). ORM-työkalut ovat tavallisesti isäntäkielen lisäkirjastoja. Ne on suunniteltu oliosuuntautuneen järjestelmän muistissa sijaitsevien olioiden liittämiseen levyllä sijaitsevaan relaatiotietokantaan niin, että olio-relaatioyhteensopimattomuuksia ei tapahtuisi. ORM-työkalut liittyvät siis nimensä mukaisesti tietokantajärjestelmiin, joissa on käytössä relaatiotietokanta.
ORM-työkalujen suurin hyöty on sovelluskehityksen, erityisesti alkuvaiheiden vauhdittuminen: suuri osa sovellusohjelman kyselyistä voidaan toteuttaa ilman SQL:ää käyttäen ORM:n metodeja datan noutamiseen, muokkaamiseen ja poistamiseen. Alla on esitetty esimerkkejä seuraavan SQL-kyselyn vastineita erilaisilla ORM-työkaluilla:
Erityisen monipuolinen Javalle tarkoitettu jOOQ:
Tunnetun ActiveRecordin Ruby-kielinen sovellus:
Eritysesti web-kehityksessä suositun Django-viitekehyksen (framework) ORM Python-ohjelmointikielellä:
Suosittu ja monipuolinen ORM-moduuli SQLAlchemy, joka toimii Python-ohjelmointikielessä:
Käytännössä ORM-työkalut generoivat metodiensa perusteella SQL-lauseita, jotka lähetetään RDBMS:lle. ORM-työkalut eivät aina ole ilmaisuvoimaltaan SQL:n tasolla, ja voivat generoida heikosti optimoitua SQL:ää. Sovelluskehityksen alkuvaiheessa ORM-työkalujen käytöllä saavutettu ajallinen hyöty voidaankin myöhemmin menettää optimoinnille, pahimmassa tapauksessa moninkertaisena. Tästä syystä ORM-työkalun käyttö ei poista tarvetta osata SQL:ää, jos tietokantajärjestelmässä on käytössä relaatiotietokanta.
8.2 Oliorelaationaalinen
Oliorelaationaaliset tietokannanhallintajärjestelmät (Object-Relational Database Management System, ORDBMS) ovat tavallisesti relaatiotietokannanhallintajärjestelmiä, joihin on myöhemmin lisätty oliosuuntautunutta ohjelmointia tukevia ominaisuuksia. Ominaisuudet on lisätty myös SQL-standardiin (SQL:1999), ja tietokantatuotteet kuten Greenplum, Oracle, PostgreSQL ja Informix ovat ottaneet niitä käyttöönsä. Tässä alaluvussa käsitellään yleisellä tasolla näistä ominaisuuksista kolme tärkeintä: mukautetut tietotyypit, perintä ja oliokäytös. Tämä alaluku perustuu lähteeseen Melton (2003a, s. 26-57, 68-105).
8.2.1 Mukautetut tietotyypit
Mukautetut tietotyypit (User-Defined Type, UDT) ovat nimensä mukaisesti uusia, itse luotavia tietotyyppejä. Ominaisuus pyrkii lieventämään joitakin olio-relaatio yhteensopimattomuuden ongelmia kuten alaluvussa 8.1.2 esitetyn taulukon tietotyyppeihin ja rakenteeseen liittyviä ongelmia. Mukautetuilla tietotyypeillä RDBMS:n ja sovellusohjelman tietotyypit voidaan:
- sovittaa yhteensopiviksi luomalla RDBMS:ään uusia, isäntäkieltä vastaavia tietotyyppejä sekä
- monimutkaistaa RDBMS:n taulun rivin rakennetta vastaamaan sovellusohjelman olioiden monimutkaisuutta.
SQL-standardi määrittää yleisellä tasolla kahdenlaisia mukautettuja tietotyyppejä: erillisiä (distinct) ja rakenteisia (structured). Erilliset tietotyypit ovat yksinkertaisesti määriteltävissä, ja niiden avulla voidaan vaivattomasti estää esim. yhteensopimattomien attribuuttien vertailu keskenään tai attribuuttien arvon muokkaaminen aritmetiikalla. Erillisen mukautetun tietotyypin voi luoda SQL:llä esim. seuraavalla tavalla:
Kahdelle uudelle tietotyypille on asetettu lähdetietotyypiksi kokonaisluku. Luodun taulun attribuuttien jalka ja äo vertailu (...WHERE jalka = äo;) tai muuttaminen matemaattisilla operaattoreilla (...SET jalka = jalka + 2;) ei onnistu. Jos attribuuteille haluttaisiin tehdä mainittuja operaatioita, ne täytyisi muuntaa ensin tyyppimuunnoksella sellaiseksi tietotyypiksi, jolle operaatiot sallitaan.
Rakenteiset tietotyypit ovat erillisiä tietotyyppejä monimutkaisempia, ja niiden avulla yksi sarake voidaan määrittää kootuksi. Ominaisuuden avulla yksi olio voidaan tehokkaammin rinnastaa yhteen tauluriviin:
Yllä määritetyssä taulussa on kaksi koottua saraketta: katu ja kaupunki. Avainsanat NOT FINAL kuuluvat standardiin ja ovat pakolliset. Jälkimmäisessä esimerkissä on esitelty notaatio rakenteista tietotyyppiä koskevasta kyselystä ja sen syntaksista.
8.2.2 Perintä
Oliosuuntautuneen ohjelmoinnin perinnän vastineeksi SQL-standardi määrittää rakenteisten tietotyyppien perinnän (type inheritance). Perinnän mukaisesti rakenteiset tietotyypit voivat toimia yhden rakenteisen tietotyypin alityyppinä ja muodostaa hierarkioita. Alityyppi perii ylityyppinsä metodit ja sarakkeet.
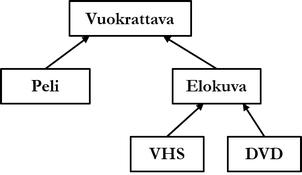
Yllä on esitetty esimerkki perinnästä. Vuokrattava-ylityypiltä peritään sarakkeet ja metodit tietotyypeille peli ja elokuva, ja edelleen elokuvan sarakkeet ja metodit periytyvät alityypeille vhs ja dvd. SQL-standardin mukaisesti moniperintää (multiple inheritance), jonka mukaan tietotyypillä voi olla useampi kuin yksi välitön (direct) ylityyppi, ei sallita. Alla on esitetty standardin mukaiset esimerkit perinnän toteuttamiseksi:
Yllä olevan esimerkin ensimmäisellä lauseella luodaan ylityyppi vuokrattava. Sille on asetettu lisämääre NOT INSTANTIABLE, joka estää tietotyypin instanssien luonnin, ts. tietotyyppi on abstrakti. Tämä johtuu siitä, että kuvitteellinen vuokraamo ei tallenna tietokantaan vuokrattavia, vaan konkreettisia vuokrattavia tuotteita: pelejä ja elokuvia. Tietotyyppi vuokrattava toimii siis ainoastaan alityyppiensä apuna. Jälkimmäisessä lauseessa on luotu konkreettinen tietotyyppi peli, jonka ylityypiksi on määritetty vuokrattava. Tietotyypin peli instansseilla on siis seitsemän saraketta.
Perintä ulottuu mukautettujen tietotyyppien lisäksi taulujen tasolle. Jatketaan yllä olevaa esimerkkiä luomalla kaksi taulua perustuen mukautettuihin tietotyyppeihin ja käyttämällä taulujen tasoista perintää:
Ensimmäisessä esimerkissä määritetään ns. itseensä viittaava sarake (self-referencing column) avainsanalla REF. Se on ORDBMS:n vastine perusavaimelle, ja sen avulla DBMS erottaa taulun rivit (tallennetut oliot) toisistaan, vaikka ne olisivat muuten identtiset. Itseensä viittaavien sarakkeiden arvot ovat uniikkeja globaalisti, ts. ne eivät ole taulu- vaan tietokantakohtaisia. Yllä olevan esimerkin mukaisessa taulussa huonot on lopulta neljä saraketta: tietotyypin vuokrattava sarakkeet sekä itseensä viittaava sarake id. Taulussa halvat_huonot_pelit on kahdeksan saraketta: perityt ja määritetyt sarakkeet tietotyypeiltä sekä taululta huonot peritty, itseensä viittaava sarake id.
8.2.3 Oliokäytös
Oliokäytöksellä (object behaviour) tarkoitetaan käytännössä metodeita. Metodit ovat SQL-standardin mukaan eräänlaisia funktioita, jotka liittyvät vahvasti johonkin mukautetun tietotyypin instanssiin (ts. tauluriviin). Mukautettu tietotyyppi, johon metodi kuuluu, kutsutaan metodiin liittyväksi tietotyypiksi (associated type).
SQL-standardin mukaan metodi määritetään kahdessa paikassa: metodin nimi, syöteparametrit ja palautusarvon tyyppi määritetään tietotyypin määrityksen yhteydessä ja metodin toiminta erillisellä käskyllä:
Yllä olevassa esimerkissä mukautetulle tietotyypille elokuva on määritetty metodikutsu kesto_luettavana. Metodi ei ota kutsuttaessa eksplisiittisiä syöteparametrejä, ja palauttaa merkkijonon.
Yllä on puolestaan määritetty metodin toiminta. On syytä huomata, että metodin ja siihen liittyvä tietotyyppi on sidottu toisiinsa sekä tietotyypin että metodin määrityksessä. Avainsana SELF viittaa instanssiin itseensä. Metodin toiminta on yksinkertainen: se palauttaa kutsuttaessa instanssinsa keston tunteina ja minuutteina. Lopuksi on esitetty esimerkki metodin kutsumisesta.
8.3 NoSQL
Tässä alaluvussa tarkastellaan neljää eri tietokantaparadigmaa, jotka muodostavat suurimman osan ns. NoSQL-paradigmaperheestä. Jos RDBMS-kentällä relaatiomalli ja SQL-standardi muodostavat perustan eri tuotteille, NoSQL-maailmassa eri tuotteiden voidaan katsoa muodostavan perustan tietokantaparadigmoilleen. Siitä huolimatta samojen tietokantaparadigmojen eri tuotteilla on suuriakin eroja. Tarkastellaan aluksi hieman NoSQL-tietokantojen perustavanlaatuisia eroja relaatiotietokantoihin.
8.3.1 BASE ja CAP
NoSQL-tietokantatuotteille on tyypillistä, että ACID-ominaisuuksista luovutaan tai niitä löyhennetään eri tavoin. Relaatiotietokannoille tyypillisien ACID-ominaisuuksien NoSQL-vastineeksi voidaan mieltää ns. BASE-ominaisuudet (Basically Available, Soft state, Eventually consistent). BASE-ominaisuudet kuvaavat niitä rajoitteita, jotka ovat usein tyypillisiä hajautetuille järjestelmille:
- Basically available tarkoittaa, että kaikkiin pyyntöihin pystytään vastaamaan huolimatta siitä, onko vastaus ajantasainen tai edes oikeellinen.
- Soft state tarkoittaa, että järjestelmän data ei ole välttämättä oikeellinen tietyllä hetkellä, vaikka tuolla hetkellä kirjoitusoperaatioita ei tapahtuisikaan. Tilan muutokset voivat johtua esimerkiksi järjestelmän automaattisesti suorittamasta datan tasauksesta tai toisintamisesta.
- Eventually consistent tarkoittaa, että järjestelmä päätyy lopulta yhdenmukaiseen tilaan, jos siihen ei kohdistu uusia kirjoitusoperaatioita.
NoSQL-tietokantatuotteita kuvataan usein ns. CAP-teoreeman näkökulmasta. CAP-teoreeman (tai Brewerin teoreema) mukaan järjestelmän on mahdollista toteuttaa kolmesta piirteestä korkeintaan kaksi:
- Yhdenmukaisuus (consistency): järjestelmä sisältää yhden ja vain yhden version datasta.
- Saatavuus (availability): kaikki järjestelmän aktiiviset solmut suorittavat operaatioita.
- Osioinnin sietokyky (partition tolerance): järjestelmä sietää osiointia.
Tuotteiden luokittelu CAP-teoreeman mukaan on kuitenkin monesti ongelmallista, sillä tuotteiden asetuksia muuttamalla ne voivat toteuttaa eri CAP-piirteitä. Lisäksi useassa tuotteessa on mahdollista valita tapahtuma- tai operaatiokohtaisesti, miten tärkeää tapahtuman onnistuminen on. Tällöin saman tuotteen eri tapahtumat voivat toteuttaa eri CAP-piirteitä.
NoSQL-tietokannanhallintajärjestelmiä verrataan usein eri näkökulmista relaationaalisiin tietokannanhallintajärjestelmiin. NoSQL-tuotteita on kuvattu mm. seuraavilla yleisnimillä eron tekemiseksi relaationaalisiin tuotteisiin: BASE-oriented, non-relational, NoJoin, schemaless, aggregate oriented, NoACID ja cluster oriented.
BASE-oriented ja NoACID viittaavat ACID-ominaisuuksien löyhentämiseen tai tapahtumanhallinnan tarkasteluun eri näkökulmasta. NoJoin ja aggregate oriented viittaavat NoSQL-tietokantojen loogisiin rakenteisiin, joissa usein tarvittu data koostetaan yhteen vastoin normalisointisääntöjä. Muun muassa tästä johtuen kaikki NoSQL-tuotteet eivät mahdollista lainkaan liitosten tekemistä kyselyissä.
Schemaless viittaa skeemattomaan loogiseen rakenteeseen. Siinä missä relaatiotietokannan taulujen rakenne on määrätty etukäteen ja sarakkeet vahvasti tyypitetty, NoSQL-tietokannassa tauluriveihin rinnastettavat tietueet saattavat poiketa rakenteeltaan huomattavasti toisistaan. Cluster oriented viittaa NoSQL-tuotteiden hajautusta suosivaan luonteeseen.
8.3.2 Avain-arvoparitietokannat
Avain-arvoparitietomalli (key-value store) on NoSQL-perheen yksinkertaisin. Sen mukaan tietue koostuu avaimesta ja avaimen arvosta: avain on arvonsa yksilöivä tunniste ja periaate on sama kuin esim. ohjelmoinnistakin tuttu hajautustaulu (hash table) tai loogisen tason tiedostojärjestelmä. Jotkin tuotteet sallivat arvoiksi monimutkaisetkin tietotyypit kuten moniulotteiset listat, hajautustaulut, XML-dokumentit tai binääridata.
Tietokannan loogisen rakenteen määrittävät vahvasti tietokantajärjestelmän tietotarpeet. Esimerkiksi verkkokaupan tietokannan avain-arvoparien arvot voivat koostua asiakkaan kaikista tiedoista sekä hänen tilaamistaan tuotteista. Näin kaikki asiakkaaseen liittyvä data voidaan noutaa yksinkertaisella kyselyllä, eikä liitoksia tarvitse muodostaa. Joissakin tuotteissa liitoksia ei ylipäätään voi muodostaa. Tietomallia on kuvattu alla yleisen rakenteen (vasemmalla) sekä esimerkin (oikealla) avulla.
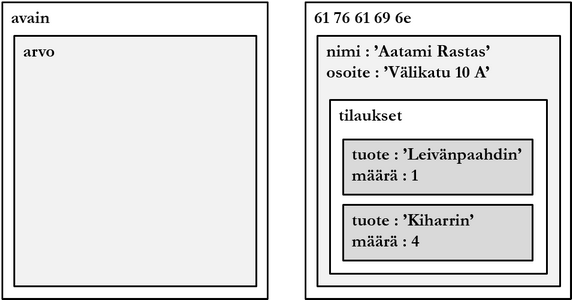
Yleistäen voidaan sanoa, että avain-arvoparitietokannan etuna on mm. yksinkertaisesta tietomallista johtuva suorituskyky, heikkoutena puolestaan samasta syystä johtuvat rajoittuneet kyselykielet. Avain-arvoparitietokannat muistuttavat tietomalliltaan dokumenttitietokantoja, mutta perustavanlaatuisena erona pidetään tavallisesti sitä, että dokumenttitietokannanhallintajärjestelmä ymmärtää datan rakennetta siinä merkityksessä, että DBMS:n kyselykieli pystyy käsittelemään dokumentin osia.
Tunnettuja avain-arvoparitietokantatuotteita ovat esimerkiksi Redis, Riak ja Memcached. Monet tuotteet on mahdollista asettaa toimimaan ainoastaan muistissa (ns. in-memory database), jolloin saavutetaan entistä parempi suorituskyky, mutta laitevirheet voivat olla datalle kohtalokkaita. Muistissa toimivat avain-arvotietokannat tukevat erityisesti vertikaalista skaalautuvuutta.
8.3.3 Sarakeperhetietokannat
Sarakeperhetietokantojen (column-family) termit on usein määritelty vahvasti tuotekohtaisesti, ja monet termit ovat samoja relaatiotietokantojen kanssa vaikka tarkoittavatkin eri asiaa. Sarakeperhetietokannassa data on matalimmalla loogisella tasolla tallennettu avain-arvopareiksi, joista käytetään nimitystä sarake ja sarakkeen arvo. Toisiinsa liittyvät sarakkeet arvoineen sijaitsevat samalla rivillä, jolla on yksilöivä tunnus (row id). Toisiaan muistuttavat rivit on ryhmitelty samaan sarakeperheeseen. Toisin kuin relaatiotietokannan taulussa, sarakeperheen riveillä ei tarvitse olla samaa määrää tai samoja sarakkeita.
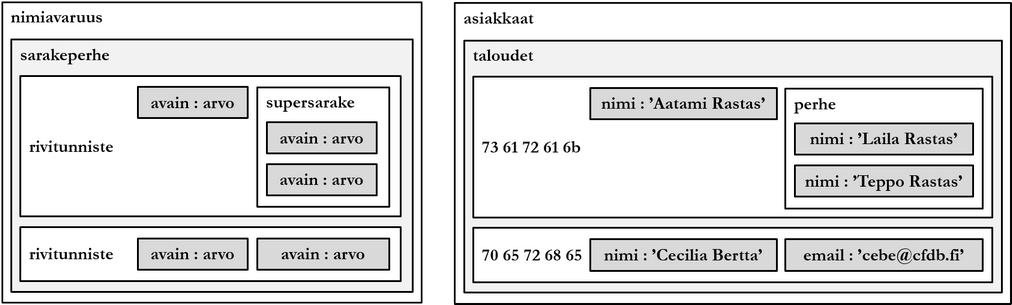
Ylimmällä loogisella tasolla sarakeperhetietokannassa on nimiavaruus (keyspace), joka sisältää yhden tai useamman sarakeperheen. Nimiavaruus vastaa löyhästi relaatiotietokannan skeemaa tai tietokantaa. Joissakin sarakeperhetietokantatuotteissa on lisäksi ns. supersarakkeita (super column). Supersarakkeet voivat sisältää muita sarakkeita mahdollistaen näin korkeintaan nelitasoisen hierarkian: nimiavaruus, sarakeperhe, supersarake ja sarake.
Tunnettuja sarakeperhetietokantatuotteita ovat esimerkiksi Cassandra, HBase ja Hypertable. Kaikki näistä tietokannanhallintajärjestelmistä mahdollistavat datan eri versioiden ylläpitämisen. Lopuksi on syytä mainita, että tuotteiden nimeämiskäytännöissä on tietomallin osalta suuriakin eroja.
8.3.4 Dokumenttitietokannat
Dokumenttitietokannat (document-oriented database) tallentavat dokumentteja. Dokumentit tallennetaan tavallisesti hieman avain-arvoparitietokannan tapaisesti: dokumentti koostuu dokumentin tunnisteesta ja sisällöstä. Dokumentin sisältö voi olla rakenteeltaan hyvinkin monimutkainen hierarkia, ja dokumenttitietomallia voidaankin pitää NoSQL-perheen joustavimpana. Dokumenttitietokannanhallintajärjestelmä pystyy tavallisesti ymmärtämään dokumentin rakennetta, ja tekemään siihen tarkempia kyselyitä kuin esimerkiksi avain-arvoparitietokannanhallintajärjestelmä avaimen arvoon. Lisäksi eri tuotteissa on lisärakenteita esim. samankaltaisten dokumenttien ryhmittelyyn.

Dokumentit tallennetaan tavallisesti XML- (Extensible Markup Language), JSON- (JavaScript Object Notation) tai BSON-muodossa (Binary JSON), joista kaksi jälkimmäistä ovat nousevassa suosiossa, ja niiden kyselykieli on tavallisesti JavaScript-pohjainen. XML-dokumenttitietokannoissa tietokantaoperaatiot tehdään tavallisesti XQuery-kyselykielellä. Alla on esitetty esimerkkidokumentti XML-muodossa.
<asiakas id="a800">
<nimi>
<etunimi>Matti</etunimi>
<sukunimi>Meikäläinen</sukunimi>
</nimi>
<osoite>
<katu>Kuja 2</katu>
<postinro>40100</postinro>
<kaupunki>Jyväskylä</kaupunki>
</osoite>
<tilaukset>
<tilaus id="t101">
<tuotenimi>Paahdin</tuotenimi>
<maara>1</maara>
</tilaus>
<tilaus id="t102">
<tuotenimi>PC</tuotenimi>
<maara>1</maara>
</tilaus>
</tilaukset>
</asiakas>Vastaava dokumentti JSON-muodossa:
Tunnettuja dokumenttitietokantatuotteita ovat esimerkiksi MongoDB ja CouchDB, joista molemmat hyödyntävät JSON-formaattia. Monessa suositussa RDBMS:ssä (esim. SQL Server, Oracle ja PostgreSQL) on puolestaan XML:ää tukevaa toiminnallisuutta. Lisäksi PostgreSQL sisältää monipuoliset työkalut JSON-dokumenttien tallentamiseen tai taulurivien palauttamiseen JSON-muodossa.
8.3.5 Graafitietokannat
Graafitietokannat (graph database) on tarkoitettu spesifisiin kohdealueisiin, joissa on tarpeen mallintaa erityisesti datan välisiä suhteita. Tietomalli perustuu verkkoteoriaan: se koostuu solmuista (node), suunnatuista kaarista (edge) ja ominaisuuksista. Ominaisuudet voivat kuulua joko kaariin tai solmuihin, ja ominaisuus koostuu avaimesta ja avaimen arvosta. Huomaa, että verkkoteorian solmu ei tarkoita samaa asiaa kuin esim. hajautusta koskevassa luvussa esitetty solmu. Graafitietomallin solmut kuvastavat tavallisesti reaalimaailman kohteita (kuten relaatiotietokannan kohderelaatiot) ja suunnatut kaaret solmujen välisiä suhteita (kuten relaatiotietokannan suhderelaatiot). Kaarten ominaisuudet kuvaavat suhteiden laatua tai piirteitä.
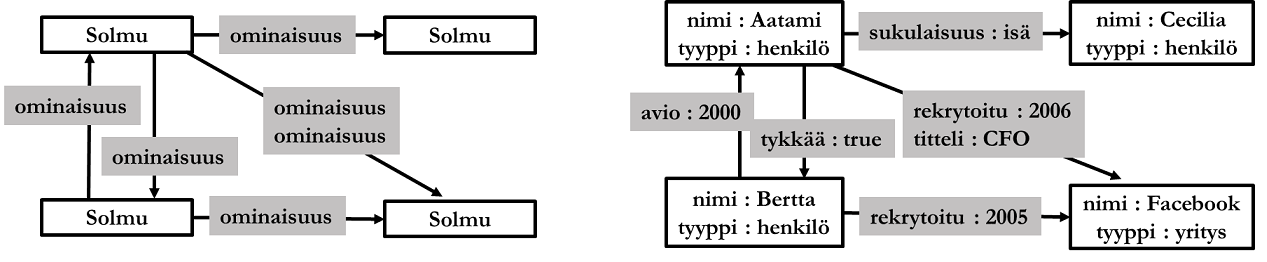
Graafitietokantojen perustavanlaatuinen ominaisuus on kyky suorittaa kohteiden suhteisiin perustuvat kyselyt nopeasti. Relaatiotietokannassa taulujen liitokset ovat yleisesti hitaita, koska DBMS joutuu liittämään relaatiot kyselyn aikana, mahdollisesti suhderelaatioita käyttäen. Graafitietokannassa puolestaan kaaret muodostavat sekä tietokannan rakenteen että datan, ts. datan rakenne on data itse. Kaaret myös muodostavat datan fyysisen rakenteen, ja kaari viittaa fyysisellä tasolla siihen liittyviin solmuihin.
Tunnettuja graafitietokantatuotteita ovat esimerkiksi Neo4J, OrientDB ja Infinite Graph. Tunnistettuja kohdealueita ovat esimerkiksi sosiaalisen median palvelut, bioinformatiikka, verkkosivujen indeksointi ja ydintiedonhallinta.
8.4 Lopuksi
Vuonna 2017 näyttää, että NoSQL-tuotteet ovat tulleet jäädäkseen korvaamatta kuitenkaan relaationaalisia tuotteita. Yleistyvä tapa näyttää olevan ns. monikielisyys (polyglot persistence), jolla tarkoitetaan tietokantajärjestelmän käyttävän useita eri tietomalleja. Näkemyksen mukaan kutakin tietomallia käytetään sellaisessa osassa tietokantajärjestelmää, johon se parhaiten soveltuu. Esimerkiksi verkkohuutokauppa voisi jakautua tietomalleiltaan seuraavalla tavalla:
| Osa-alue | Kriittistä osa-alueessa | Tietomalli |
|---|---|---|
| Huudot | Nopeus | Avain-arvopari |
| Maksutapahtumat | Datan oikeellisuus | Relaationaalinen |
| Tuotesuositukset | Nopeat liitokset | Graafi |
| Käyttäjien suhteet | Nopeat liitokset | Graafi |
| Raportointi | Monipuoliset raportointiominaisuudet | Relaationaalinen |
| Analysointi | Suurten datamäärien reaaliaikainen analysointi | Sarakeperhe |
Alla olevaan taulukko on yleistetty NoSQL-tuotteiden ja relaationaalisten tuotteiden vahvuuksia ja heikkouksia eri näkökulmista. On syytä huomata, että piirteet ovat tyypillisiä, eivät joustamattomia. Esimerkiksi RDBMS:n tapahtumanhallinta voidaan muuttaa asetuksin heikoksi tai tapahtumanhallinnan heikkous voi olla jopa tapahtumakohtaista.
| Relaationaaliset | NoSQL | |
|---|---|---|
| Paikallisvaste | Suuri | Pieni |
| Kyselykielet | Monipuoliset | Yksinkertaiset |
| Tapahtumanhallinta | Vahva | Heikko |
| Hajautus | Työlästä | Vaivatonta |
| Käyttökohteet | Yleiskäyttöisiä | Spesifiset kohdealueet |
| Raportointi | Monipuolista | Rajoittunutta |
| Tuotteiden kypsyys | Kypsiä | Tuoreita |
| Yhteisön tuki | Monipuolinen | Vaihteleva |
| Maksullisuus | Maksuttomia ja kaupallisia | Tavallisesti maksuttomia |
| Datan toisteisuus | Pyritään minimoimaan | Toistoa siedetään, jopa suositaan |
These are the current permissions for this document; please modify if needed. You can always modify these permissions from the manage page.