Hajautus
Luku videona
Päivitys 1.6.2024: Vanhat luentovideot on poistettu edellisen vastuuopettajan pyynnöstä. Uudet videot julkaistaan keväällä 2025.
Luku tekstinä
Tässä luvussa käsitellään tietokantajärjestelmän palvelin- ja laitteistoarkkitehtuurin kautta tietokantajärjestelmien hajautusta. Hajautuksella (distribution) tarkoitetaan tässä luvussa yleisellä tasolla tietokantajärjestelmän jakamista usealle laitteelle. Tietokantajärjestelmän hajautus voidaan yleisellä tasolla jakaa kahteen osaan: laskentatehon ja datan hajautukseen. Hajautus on yleistä ja suuressa määrin yleistyvää.
Tämä luku jakautuu kolmeen osaan: ensimmäinen alaluku käsittelee palvelinarkkitehtuurin yleistä mallia, ns. kolmitasoarkkitehtuuria. Toinen alaluku käsittelee laitteistoarkkitehtuuria, joka koskee tietokantajärjestelmässä erityisesti kolmitasoarkkitehtuurin tietokannasta vastaavaa osaa. Viimeinen alaluku käsittelee erityisesti dataa koskevia hajautusmenetelmiä.
7.1 Kolmitasoarkkitehtuuri
Nykyään on tavallista, että tietokantajärjestelmä on palvelinarkkitehtuuriltaan ainakin kolmitasoinen (three tier). Asiakastason käyttöliittymä mahdollistaa tietokantajärjestelmän käytön asiakkaille (ns. front-end). Logiikkatason sovelluspalvelin sisältää tietokantajärjestelmän sovelluslogiikan. Datatason tietokantapalvelin sisältää tietokannanhallintajärjestelmän ja tietokannan (ns. back-end).
Kolmitasoarkkitehtuurin nk. edeltäjä on tiedostopalvelin. Sen mukaisessa palvelinarkkitehtuurissa tietokanta tai sen osa sijaitsee asiakaslaitteella, ja asiakaslaitteen vastuulla on myös liiketoimintalogiikka (eli mm. laskenta). Kolmitasoarkkitehtuurin etuja tiedostopalvelimeen ovat Quinlanin (1995) mukaan mm.:
- Asiakaslaitteilta ei vaadita suurta määrää muistia tai laskentatehoa, koska arkkitehtuurin muut tasot vastaavat laskennasta.
- Datan yhdenmukaisuuden varmistaminen on vaivattomampaa, koska data on yhdessä paikassa.
- Tietoturva vahvistuu, koska asiakaslaitteet eivät käsittele dataa suoraan, vaan sovelluslogiikkakerroksen kautta.
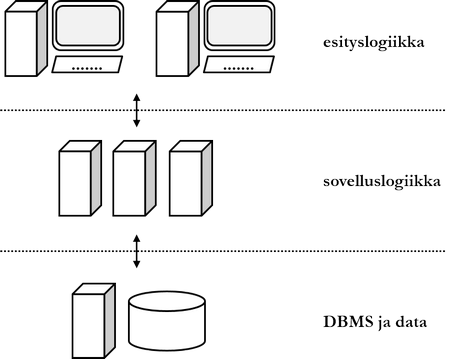
On syytä mainita, että kolmitasoisella (tai n-tasoisella) arkkitehtuurilla voidaan tarkoittaa myös sovellusarkkitehtuuria. Niiden mukaisesti sovellusohjelma jaetaan loogisesti kolmeen tasoon (layer). Näiden tasojen vastuut vastaavat yleisesti yllä kuvatun palvelinarkkitehtuurin tasojen vastuita: yksi taso on vastuussa käyttöliittymästä, toinen laskennasta ja kolmas datasta.
7.2 Rinnakkaisarkkitehtuurit
Rinnakkaisarkkitehtuureilla tarkoitetaan tässä alaluvussa laitteistoarkkitehtuureja, jotka pyrkivät ratkaisemaan tietokantajärjestelmien ongelmia erityisesti käyttämällä useita prosessoreita tai useita laitteita tai molempia. Lähtökohtia rinnakkaisarkkitehtuureille on kaksi: jaettu levy sekä täysin erillinen. Tämä alaluku perustuu lähteeseen Hellerstein, Stonebraker & Hamilton (2007, s. 165-175).
7.2.1 Jaettu levy -arkkitehtuuri
Jaettu levy -rinnakkaisarkkitehtuurin (shared disk) mukaan usea laite pitää yllä tietokantainstansseja (ts. kokoelmaa prosesseja ja varattua muistia) samasta tietokannasta, ts. massamuisti jaetaan laitteiden kesken. Tätä suhdetta, jossa usea tietokantainstanssi voi yhdistää samanaikaisesti yhteen tietokantaan, kutsutaan klusteroinniksi tai ryvästämiseksi (clustering). Ryvästämisen tarkoituksena on tarjota asiakasohjelmalle sama toiminnallisuus kuin keskitetynkin järjestelmän, mutta paremmalla suorituskyvyllä ja vikasietoisuudella.
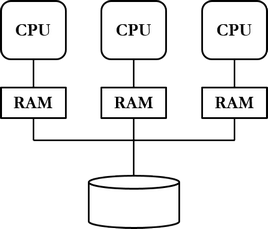
Tämän rinnakkaisarkkitehtuurin vahvuutena nopeuden lisäksi on vikasietoisuus: vaikka jokin tietokantainstansseja ylläpitävistä laitteista menetetään, voidaan asiakkaita silti palvella. Ideaalitapauksessa asiakaslaite ei ole tietoinen, vaikka tietokantainstanssia ylläpitävä laite menetetään kesken tietokantajärjestelmän käytön, vaan toinen solmu ottaa huolekseen asiakkaan palvelemisen.
Jaettu levy -rinnakkaisarkkitehtuurin uhkana voidaan pitää vikatilannetta tietokantaa ylläpitävässä laitteessa. Tätä potentiaalista ongelmaa voidaan kuitenkin lieventää toisintamalla tietokanta usealle laitteelle. Toisintamista käsitellään tarkemmin myöhemmin alaluvussa 7.3. Tämän rinnakkaisarkkitehtuurin heikkoutena voidaan pitää myös tietokantajärjestelmän infrastruktuurin suunnittelun ja toteutuksen haastavuutta.
7.2.2 Täysin erillinen -arkkitehtuuri
Täysin erillinen -arkkitehtuurin (shared nothing) mukaan tietokanta on looginen kokonaisuus, joka on jaettu fyysisesti eri laitteille. Jokainen järjestelmän tietokantainstanssi pitää yllä osaa tietokannasta.
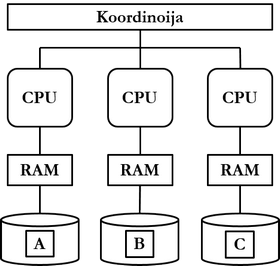
Asiakasohjelmalle tietokannanhallintajärjestelmä näyttää ja toimii samoin kuin keskitetty järjestelmäkin, ja kaikki liikenne tapahtuu tavallisesti koordinoijan kautta. Koordinoija huolehtii siitä, että asiakasohjelmalta saapuvat pyynnöt välitetään oikealle solmulle tietokantajärjestelmässä. Jos koordinoijia on useita, arkkitehtuurin mukaisessa järjestelmässä minkä tahansa solmun menettäminen ei saata järjestelmää toimimattomaan tilaan. Arkkitehtuurilla saavutetaan teoriassa lineaarinen skaalautuvuus.
7.2.3 Jaettu muisti -arkkitehtuuri
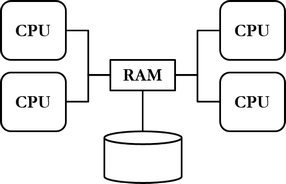
Jaettu muisti -rinnakkaisarkkitehtuurin (shared memory tai shared everything) mukaisesti joukko prosessoreita tai ytimiä jakaa saman keskusmuistin. Jaettu muisti ei ole nykyään enää varsinainen rinnakkaisarkkitehtuuri, vaan rinnakkaisarkkitehtuurin laajennos, joka on käytössä muiden rinnakkaisarkkitehtuurien ohessa, sillä kaikki nykyaikaiset prosessorit ovat moniytimisiä.
7.3 Toisintaminen ja sirpalointi
Jos tietokanta sijaitsee usealla laitteella (ts. solmulla), tietokantaa kutsutaan hajautetuksi (distributed). Hajautus jaetaan tässä alaluvussa kahteen luokkaan: toisintamiseen (data on kopioitu usealle laitteelle) ja sirpalointiin (data on jaettu usealle laitteelle).
Hajautuksella pyritään mm. skaalautuvuuteen eli laajennettavuuteen, jonka tarkoituksena on järjestelmän suorituskyvyn tehostaminen. Tietokantajärjestelmien skaalautuvuus voi olla n-tasoisen arkkitehtuurin sovelluslogiikkakerroksen skaalautuvuutta tai tietokannan eli datan skaalautuvuutta. Edelleen skaalautuvuus voi olla vertikaalista (scaling up), joka pyrkii yhden solmun suorituskyvyn lisäämiseen tai horisontaalista (scaling out), joka pyrkii lisäämään järjestelmän suorituskykyä lisäämällä järjestelmään solmuja.
7.3.1 Toisintaminen
Toisintamisella (replication) tarkoitetaan datan kopioimista usealle solmulle: tietokanta nähdään loogisena kokonaisuutena ABC, joka kopioidaan kokonaisuudessaan usealle solmulle. Toisintamisen tarkoituksena on vikasietoisuuden tai suorituskyvyn parantaminen tai molemmat.

Toisintamisen toteutukselle on kaksi erilaista kokoonpanoa: isäntä-orja- (master-slave tai primary-secondary) ja vertaiskokoonpano (peer-to-peer). Isäntä-orja -kokoonpanossa asiakassovellukset tekevät tavallisesti kirjoitusoperaatiot isäntäsolmuun ja lukuoperaatiot orjasolmuihin alla olevan kuvion mukaisesti. Vertaiskokoonpanossa asiakassovellukset tekevät luku- (read, R) ja kirjoitusoperaatioita (write, W) mihin solmuun tahansa.
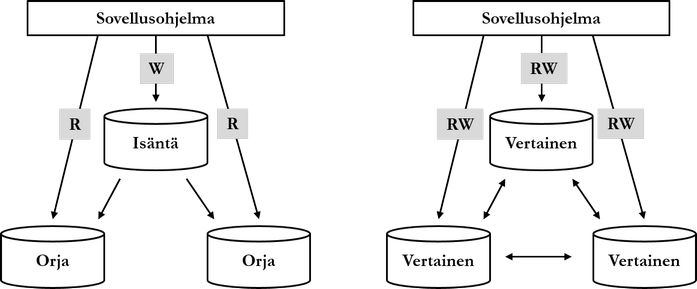
Isäntä-orja -kokoonpano voidaan toteuttaa myös niin, että kaikki kirjoitus- ja lukuoperaatiot tehdään vain isäntäsolmuun, ja data toisinnetaan orjasolmuihin ainoastaan vikasietoisuuden takaamiseksi. Näin data on kaikille asiakkaille yhdenmukainen, mutta operaatiot potentiaalisesti hitaampia. Yllä olevassa kuviossa (vasen) orjasolmut toisintavat datan isäntäsolmulta. On myös tuotteesta riippuen asetuksia muuttamalla mahdollista, että orjasolmut toisintavat dataa toisiltaan.
Koska vertaiskokoonpanossa kaikkiin solmuihin voidaan tehdä kirjoitusoperaatioita, kirjoitusoperaatioista johtuvat poikkeamat ovat mahdollisia. Toisaalta taas vertaiskokoonpano ei kuormita ainoastaan yhtä solmua kirjoitusoperaatioilla, vaan kuorma on tasattu solmujen kesken.
Toisintaminen voi edelleen olla synkronista tai asynkronista. Synkronisessa toisintamisessa kirjoitusoperaation vastaanottava solmu odottaa, että kaikki tai määrätty osa muista solmuista on toisintanut datan itselleen ennen kuittauksen lähettämistä sovellusohjelmalle. Asynkronisessa toisintamisessa kuittaus lähetetään heti, kun kirjoitusoperaation vastaanottanut solmu on tallentanut datan.
7.3.2 Sirpalointi
Sirpaloinnin (sharding) mukaisesti tietokanta on looginen kokonaisuus ABC, joka jaetaan loogisesti ja fyysisesti usealle eri solmulle. Jokaisessa solmussa on oma skeemansa, ns. skeemainstanssi. Sirpalointi on yleistä erityisesti NoSQL-tietokannoissa. Relaatiotietokannoissa käytetään myös ns. partitiointia (partitioning), jonka mukaisesti tietokanta jaetaan loogisiin osiin yhden skeeman sisäisesti. Käytännössä tämä tarkoittaa relaatioiden jakamista useisiin eri tauluihin vaakasuuntaisesti eli monikoittain.

Sirpalointia käytetään tyypillisesti toisintamisen rinnalla. Tästä syystä isäntä-orja-kokoonpanolla toisinnetussa tietokantajärjestelmässä on mahdollista olla useita isäntäsolmuja, joista jokainen huolehtii tietystä osasta dataa, ts. yhdestä sirpaleesta (shard). Sirpaloinnin tarkoituksena on suorituskyvyn parantaminen, ja toisaalta myös vikasietoisuuden parantaminen, jos ollaan valmiita palvelemaan asiakkaita puutteellisella datalla.
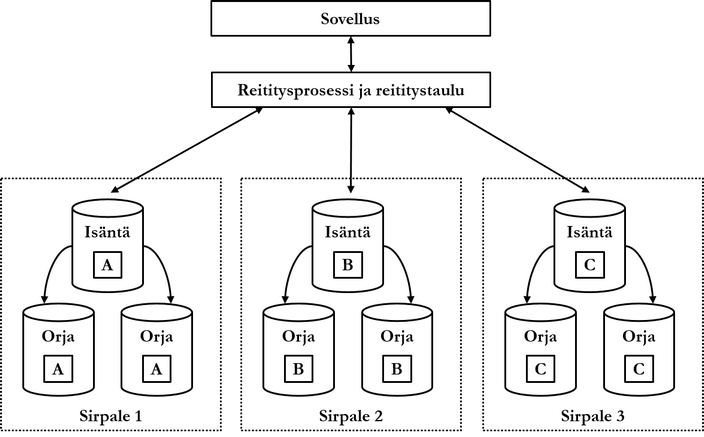
Yllä olevassa kuviossa tietokanta on hajautettu yhdeksään solmuun, jotka sijaitsevat kolmessa sirpaleessa. Data on toisinnettuna kolmeen solmuun. Sovellusohjelma kommunikoi tietokannan kanssa reititysprosessin välityksellä, eikä sovellusohjelman tarvitse tietää, että tietokanta on hajautettu.
Tietokannan sirpalointi tehdään sirpaleavaimen (shard key) avulla. Sirpaleavain on tietomallista riippuen jokin tietue, jonka arvojen perusteella sirpalointi suoritetaan. Useimmat NoSQL-tuotteet tukevat ns. autosharding-ominaisuutta. Sen avulla tietokannanhallintajärjestelmä huolehtii automaattisesti datan tasaamisesta solmujen kesken, kun sirpaleavain on valittu. Datan tasaaminen solmujen kesken suoritetaan jakamalla kunkin solmun data kimpaleisiin (chunk) ja siirtämällä kimpaleita solmujen välillä niin, että jokaisessa solmussa on suunnilleen sama määrä dataa.
Tarkastellaan lopuksi matalan tason esimerkkiä yllä olevaa kuviota hyödyntäen. Oletetaan, että tietokannasssa on tietoa asiakkaista. Tietokannan sirpaleavaimeksi on valittu asiakkaan syntymäaika. Sirpaleessa 1 ovat tallennettuina asiakkaat, joiden syntymäaika on välillä minimi-3.4.1970, sirpaleessa 2 asiakkaat, joiden syntymäaika on välillä 4.4.1970-1.2.1989 ja sirpaleessa 3 asiakkaat, joiden syntymäaika on välillä 2.2.1989-maksimi. Sovellusohjelma lisää tietokantaan uuden asiakkaan, jonka syntymäaika on 10.1.1989:
- Reititysprosessi tarkastaa pyynnön saatuaan reititystaulusta, mihin sirpaleeseen uusi asiakas kuuluu. Reititystaulun mukaan asiakas kuuluu sirpaleeseen 2.
- Reititysprosessi välittää uuden asiakkaan sirpaleen 2 isäntäsolmulle.
- Sirpaleen 2 isäntäsolmu havaitsee, että kimpale numero 109 pitää sisällään asiakkaat, joiden syntymäaika on välillä 5.1.1989-1.2.1989 ja ryhmittää uuden asiakkaan tähän kimpaleeseen.
- Tietokannanhallintajärjestelmän autosharding-prosessi havaitsee, että sirpaleessa 3 on kynnyksen ylittävä määrä vähemmän dataa kuin muissa sirpaleissa.
- Kimpale 109 siirretään sirpaleen 3 isäntäsolmuun, jotta datan määrä tasaantuu sirpaleiden välillä.
- Tieto sirpaleiden uusista arvojoukoista tallennetaan reititystauluun.
- Kimpale 109 toisinnetaan sirpaleen 3 orjasolmuihin.
These are the current permissions for this document; please modify if needed. You can always modify these permissions from the manage page.