Tietovarastointi
Luku videona
Päivitys 1.6.2024: Vanhat luentovideot on poistettu edellisen vastuuopettajan pyynnöstä. Uudet videot julkaistaan keväällä 2025.
Luku tekstinä
Tietovarastoinnilla (data warehousing) tarkoitetaan suunnitelmallista ja jaksotettua datan kopioimista, muuntamista ja jalostamista useista eri lähteistä ympäristöön, joka on tarkoitettu tiedon analysointiin. Tätä kohdetietokantaa tai -tietokantoja kutsutaan tietovarastoksi (data warehouse).
6.1 Yleistä tietovarastoinnista
Organisaatiot, joilla on vain yksi tietokanta, ovat harvinaisia. Organisaatioilla on yhä enemmän ja enemmän dataa, ja data sijaitsee eri tietokannoissa hyvinkin erilaisissa muodoissa. Koska operatiiviset tietokannat ovat tarkoitettuja pääasiassa päivittäisen liiketoiminnan mahdollistamiseksi, ne harvoin tyydyttävät organisaation johtajien tai analyytikoiden tietotarpeita. Tiedonhallinnan kannalta tietovarastointi edesauttaa merkittävästi organisaation menestymistä.
Tässä alaluvussa tutustutaan tietovarastoinnin yleiseen arkkitehtuuriin ja tarkoitukseen.
6.1.1 Arkkitehtuuri
Alla olevassa kuviossa on kuvattu tietovarastoinnin yleinen arkkitehtuuri käyttäen esimerkkinä pankkia. Pankilla on kaksi operatiivista eli päivittäisen liiketoiminnan mahdollistavaa tietokantajärjestelmää (online transaction processing, OLTP): maksuliikenne ja pörssi. Lisäksi kuviossa on pankin ulkopuolinen, luottolaitoksen tietokantajärjestelmä luottotiedot, jota pankki käyttää. Nämä tietokantajärjestelmät sisältävät ns. lähdetietokannat, jotka tavallisesti muistuttavat loogiselta rakenteeltaan tällä kurssilla jo käsiteltyjä tietokantoja.
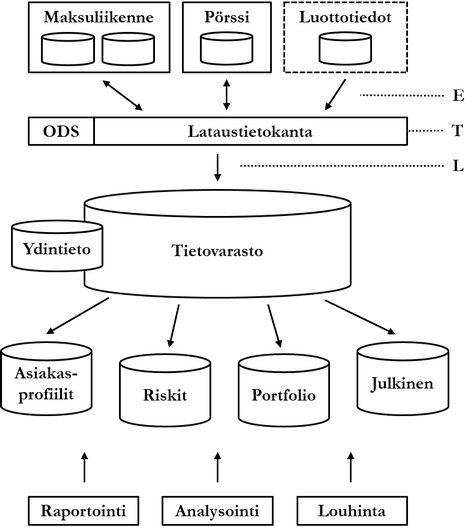
Lähdetietokannoista kerätään haluttu data (extract, E) ns. lataustietokantaan (staging area). Koska data kerätään mahdollisesti hyvinkin erilaisista lähteistä, se täytyy muuntaa yhtenäiseen muotoon. Lisäksi datasta suodatetaan huonolaatuinen, virheellinen ja muuten ei-toivottu data sekä mahdollisesti johdetaan haluttu tieto. Kaikki tämä muuntoprosessi (transform, T) suoritetaan lataustietokannassa. Lataustietokanta on varsinaisen tietokannan lisäksi joukko väliohjelmistoja (middleware). Lopuksi muunnettu data saatetaan (load, L) varsinaiseen tietovarastoon (data warehouse), tavallisesti jaksottain eräajona, esimerkiksi kerran viikossa tai jokaisen vuosineljänneksen päätteeksi.
Lataustietokanta tyhjennetään tasaisin väliajoin. Tietovarastoa on kuvattu kuviossa yhdellä tietokannalla, mutta tavallisesti tietovarastoon kuuluu useita tietokantoja. Väliohjelmiston toteuttama ETL-prosessi on kohdealueen tarpeista riippuen monimutkainen, erityisesti datan laadunvalvonnan osalta. On myös mahdollista, että laadunvalvontaprosessin päätteeksi dataa syötetään takaisin lähdetietokantoihin. Näin virheellinen tai muuten puutteellinen data korjataan myös lähdetietokannoissa.
Lopuksi tietovaraston data voidaan jakaa ns. paikallisvarastoihin (data mart). Paikallisvarastot voivat olla fyysisiä tietokantoja tai ne voidaan toteuttaa puhtaasti loogisilla tietorakenteilla kuten näkymillä. Tietovaraston jako paikallisvarastoihin helpottaa monimutkaisen rakenteen ymmärtämistä sekä rajoittaa loppukäyttäjien oikeuksia jalostettuun dataan. Paikallisvarastojen tai tietovaraston dataa käsitellään edelleen raportoimalla, analysoimalla ja louhimalla.
6.1.2 Tarkoitus
Tietovarastointi voi olla yrityksen sisäinen tapa saavuttaa hyötyä tai tietovarastointi voi itsessään olla liiketoimintaa. Tietovarastoinnin juuret ovatkin markkinatutkimuksessa, jonka kaikki data kerätään ulkopuolisista lähteistä. Kun organisaation data on kerätty tietovarastoon, dataa voidaan hyödyntää eri tavoin edistämään liiketoimintaa, esimerkiksi päätöksenteon apuna, markkinoiden ennustamisessa tai uhkien kartoittamisessa.
Teknisemmästä näkökulmasta (Inmon 1992) tietovarastoinnin tarkoituksena on yhdistää eritasoisissa ja eri-ikäisissä tietojärjestelmissä (legacy systems) oleva epäyhtenäinen ja eriaikainen (time-variant) tieto tietyistä aihe-alueista (subject-oriented) pysyvästi tallennetuksi (non-volatile) ja mielekkäällä tavalla haettavaksi.
Tietovaraston datan hyödyntäminen voidaan jakaa hyödyn tavoittelun näkökulmasta kolmeen osaan:
- Raportointiin, jonka avulla saadaan yksinkertaisia vastauksia yksinkertaisiin kysymyksiin kuten "Mitä tapahtui lainojen koroissa vuoden 2015 ensimmäisellä kvartaalilla".
- Analysointiin, jonka avulla saadaan vastauksia monimutkaisiinkin kysymyksiin kuten "Mitä on tapahtunut punaisten tuotteiden myynnissä vuonna 2014 ja miksi". Liiketoimintatiedon analysoinnin työkaluja ja tekniikoita kutsutaan yleisesti nimellä OLAP (online analytical processing).
- Tiedonlouhintaan, jonka avulla saadaan monimutkaisiakin vastauksia monimutkaisiinkin kysymyksiin kuten "Mitä kehitystä todennäköisesti tapahtuu Ranskan bruttokansantuotteessa vuonna 2020" tai "Mitä mielenkiintoista yrityksen henkilöstössä tapahtuu ensi vuonna". Tiedonlouhintaa käsitellään yleisellä tasolla tämän luvun lopussa.
6.1.3 Ydintieto
Organisaation keskeinen tieto eli ydintieto (master data) kootaan yhteen ja vain yhteen paikkaan oikeellisuuden varmistamiseksi. Ydintieto on tietoa, joka on organisaatiossa tunnustettu oikeelliseksi ja toimijoiden kesken jaettu. Ydintieto voi olla organisaation toiminnan kannalta kriittistä dataa (esimerkiksi pankin tilitiedot), mutta ydintiedon ei tarvitse rajoittua siihen. Ydintietoon ja sen hallintaan liittyy datan kannalta kaksi keskeistä käsitettä: system of entry (SOE) tarkoittaa datan lähdettä (esim. ERP-järjestelmä), joka on hyväksytty, ts. tunnustettu luotettavaksi. Koska hyväksyttyjä datalähteitä voi olla useita, täytyy ristiriitojen ilmetessä olla keino varmistua siitä, mikä hyväksytyistä tietoalkioista on oikea. Käsitteellä system of record (SOR) tarkoitetaan oikeelliseksi tunnustettua versiota datasta. Niitä voi olla ainoastaan yksi, jolloin ei ole edes teoriassa mahdollista, että data on ristiriitaista.
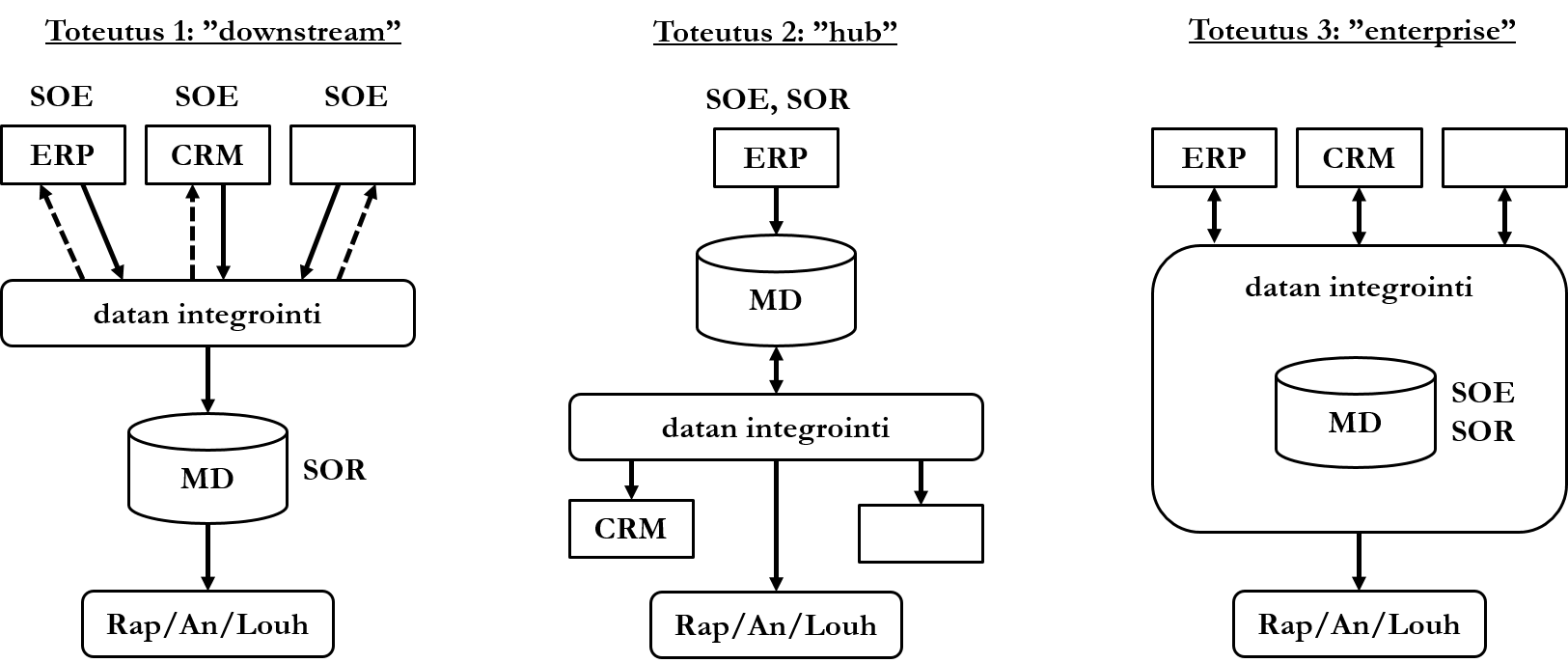
- Downstream-toteutus on tavallisesti yksinkertaisin toteuttaa, mutta datan jäljittäminen takaisin oikeaan lähdejärjestelmään voi olla haastavaa. Tässä toteutuksessa organisaation tietojärjestelmät toimivat hyväksyttyinä datan lähteinä. Data tuodaan integrointiprosessiin, joka muistuttaa tietovarastointiarkkitehtuurin muunnosprosessia (transform). Dataa voidaan tarvittaessa syöttää takaisin lähdejärjestelmiin. Integroinnin jälkeen data tuodaan rakenteelliseen tietokantaan, joka toimii oikeellisena datana. Tätä dataa käytetään edelleen raportointiin, analysointiin ja tiedonlouhintaan.
- Hub-toteutuksessa yksi lähdejärjestelmä toimii ainoana hyväksyttynä datalähteenä ja oikeellisena versiona datasta. Data syötetään muihin organisaation tietojärjestelmiin sellaisessa muodossa, jossa tietojärjestelmät sitä tarvitsevat.
- Enterprise-toteutus on tavallisesti vaativin toteuttaa. Siinä ydintietokanta toimii sekä hyväksyttynä datan lähteenä ja oikeellisena datana. Vaikka data alun perin tuodaan lähdetietojärjestelmistä, sen tulee läpäistä integrointiprosessi ennen kuin data on todettu oikeelliseksi. Oikeelliseksi todettu data syötetään takaisin lähdetietojärjestelmiin.
6.2 Tietovaraston kehittäminen
Tietovaraston kehittämisen vaiheet noudattavat pääpiirteiltään tietojärjestelmän kehitysvaiheita. Vaiheet eivät ole tiukasti perättäisiä, vaan osittain limittäisiä ja vaiheisiin voidaan palata. Kehittämisen tekevät tavallisesti ohjelmoijista ja analyytikoista (tai muista kohdealueen liiketoimintalogiikan tuntijoista) koostuva ryhmä. Tietovarastoinnin kehityksessä toimijoiden yhteistyö on erityisen tärkeää.
6.2.1 Analyysi ja suunnittelu
Ensimmäiseksi on valittava tietovarastoinnin painopisteet tai fokukset, eli mitä tietovarastoinnilla halutaan saavuttaa. Painopisteiden on oltava selvästi eroteltavissa, ja niitä voi olla useita. Painopiste voi olla esimerkiksi:
- Kenelle voidaan antaa lainoja ja millaisella korolla?
- Mitä tuotteita tuotetta X verkkokaupassa katselleet lopulta ostivat?
Seuraavaksi selvitetään, millaisella informaatiolla vaatimukset saavutetaan.
Lisäksi selvitetään, mitä dataa tarvitaan tarvittavan informaation johtamiseen, ja mistä lähteistä data saadaan. Päätetään myös, kuinka kauan dataa säilytetään. Esimerkiksi vartioimisliikkeen tulee lain mukaan säilyttää tapahtumailmoitukset viisi vuotta. Toisaalta verkkokauppa voi haluta säilyttää myyntihistoriansa perustamisvuodesta lähtien.
Suunnitteluun kuuluu looginen ja fyysinen suunnittelu: tietokannan skeeman, indeksien, tietotarpeiden ja saantipolkujen, laitteiston sekä integroinnin suunnittelu. Valitaan myös OLAP-työkalut, jotka tukevat tietotarpeita ja valittuja tekniikoita. Jos tietovarasto toteutetaan relaatiotietokannalla, suunnitellaan mahdolliset summataulut ja näkymät. Summataulut ovat tauluja, jotka sisältävät johdettua dataa. Tämä johdettu data tavallisesti vastaa usein toistuviin, koostamista vaativiin tietotarpeisiin. Summataulun avulla dataa ei tarvitse koostaa jokaisen kyselyn yhteydessä, vaan data on jo koostettuna taulussa.
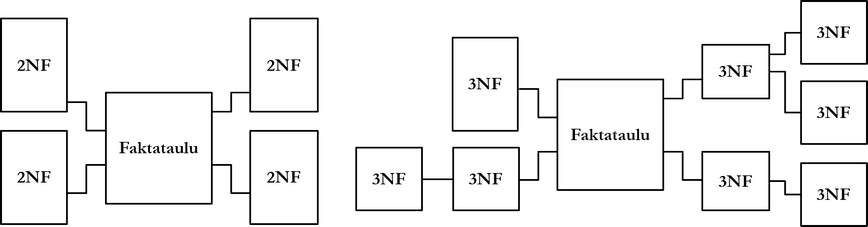
Tietovarastojen ja operatiivisten tietokantojen skeemat poikkeavat toisistaan. Kolme tietovarastojen tunnistettua skeemaa ovat ns. tähti-, lumihiutale- ja tähtihiutalemallit. Kaikissa malleissa on yhteistä tietokannan skeeman keskiössä sijaitseva faktataulu tai faktataulut. Faktataulu on kuten luvussa 3 käsitelty suhderelaatio, joka yhdistää useat kohteet toisiinsa ja sisältää mitattavaa dataa tapahtumista, esimerkiksi tilauksista tai tilisiirroista. Faktataululle on tavallista, että sillä on moniosainen perusavain, joka koostuu muiden, ns. ulottuvuustaulujen perusavaimista. Ulottuvuustaulut ovat kuten kohderelaatioita: ne sisältävät kuvaavaa dataa esimerkiksi tuotteista tai asiakkaista. Perusavaimensa lisäksi faktataululla voi olla lisäsarakkeita.
Tähtimalliksi kutsutaan tietovaraston skeemaa, jonka ulottuvuustauluja ei ole pitkälle normalisoitu. Lumihiutalemallin mukaisessa skeemassa ulottuvuustaulut on normalisoitu esimerkiksi 3. normaalimuotoon. Tähtihiutalemalli on ns. hybridimalli, jossa jotkin ulottuvuustaulut ovat pitkälle normalisoituja ja toiset eivät.
Suunniteluvaiheessa myös päätetään, käytetäänkö operatiivista tietovarastoa (operational data store, ODS). Sen avulla voidaan tarkastella reaaliaikaista operationaalista dataa OLAP-työkaluilla, vaikka dataa ei olisi vielä tuotu tietovarastoon. Tekniikan heikkoutena ovat kasvavat tallennustila- ja tiedonsiirtovaatimukset.
6.2.2 Toteutus, käyttöönotto ja ylläpito
Tässä vaiheessa toteutetaan tietovarasto ja lataustietokanta. Toteutetaan datan kerääminen lähdetietokannoista (extract), datan käsittely lataustietokannassa (transform) ja käsitellyn, laadukkaan datan saattaminen tietovarastoon (load). Potentiaalisia ongelmia ETL-vaiheissa (extract-transform-load) voivat olla esimerkiksi
- Data kerätään monesta eri lähteestä. Eri lähteiden data voi olla toisteista, ja toisteisuus voi olla hankalaa havaita. Esimerkiksi yksi järjestelmä tallentaa tuotenumerot eri muodossa kuin toinen.
- Dataa voi liikkua lataustietokantaan ja sieltä pois huomattavia määriä. Milloin on operatiivisesti hyväksyttävää kuormittaa tietokantajärjestelmää tietovarastoinnilla?
- Käytetäänkö operaationaalista tietovarastoa?
- Miten datan laatua mitataan ja miten heikkolaatuista datan tulee olla jotta se hylätään?
- Miten reagoidaan ja varaudutaan esim. loogisen rakenteen muutoksiin erityisesti ulkoisissa lähdetietokantajärjestelmissä?
Lataustietokannan väliohjelmisto toteutetaan, tai jos käytetään kolmannen osapuolen ohjelmistoja, liitetään tietovarastoon.
Tässä vaiheessa tietovarasto ja OLAP-työkalut esitellään niitä käyttäville loppukäyttäjille. Lisäksi koulutetaan, miten tietoa noudetaan tietovarastosta ja miten tietoa hyödynnetään.
Jos suunnitteluvaiheessa ei ole suunniteltu paikallisvarastoja, ne voidaan luoda tässä vaiheessa. Paikallisvarastot palvelevat tiettyjä tietotarpeita, esimerkiksi markkinoinnin paikallisvaraston avulla markkinointiosaston analyytikot voivat saada tietoa tuotteiden myyntimääristä. Paikallisvarastojen sisältämä data on joko kerätty kokonaisuudessaan tietovarastosta tai se voi sisältää lisäksi muutakin dataa. Ensimmäistä tulkintaa kutsutaan Inmonin koulukunnaksi (Inmon 1992) ja jälkimmäistä Kimballin koulukunnaksi (Kimball 1996).
Paikallisvarastojen sisältämä data suunnitellaan painopisteitä vastaaviksi. Painopisteet voivat olla hyvinkin monimuotoisia, esimerkiksi
- Maantieteelliseen sijaintiin perustuvia, esimerkiksi Jyväskylän toimistojen paikallisvarasto.
- Yrityksen eri osastojen tietotarpeisiin perustuvia, esimerkiksi pankin riskit ja asiakasprofiilit.
- Datan koontiin perustuvia, esimerkiksi koko yrityksen myynti maailmanlaajuisesti.
- Markkina-alueisiin perustuvia, kuten yritysten x ja y osuus markkinoista.
- Datan arkaluontoisuuteen perustuvia, esimerkiksi jokin paikallisvarasto voi olla julkinen, toinen vain organisaation johdon käyttöön ja kolmannen data myytävänä kolmansille osapuolille.
Alla olevaan taulukkoon on koottu tietovarastojen ja operatiivisten tietokantojen (OLTP) eroja eri näkökulmista (Elmasri & Navathe 2007 sekä Watson 2006, s. 433-453).
| Operatiivinen tietokanta | Tietovarasto | |
|---|---|---|
| Käyttötarkoitus | Päivittäinen liiketoiminta | Analysointi, suunnittelu, ongelmanratkaisu |
| Datan lähde | Sovellusohjelma, käyttäjät | Lähdetietokannat |
| Datan rakeisuus | Tarkka | Koottu, tarkka |
| Datan luonne | Dynaaminen tilannekuva | Staattinen historia, koonti |
| Datan määrä | Pieni, keskikokoinen | Suuri, massiivinen |
| Hakulauseet | Yksinkertaisia, vähän rivejä palauttavia | Monimutkaisia, koostavia |
| Muokkauslauseet | Loppukäyttäjiltä tulevia: pieniä, nopeita | Eräajo: suuria, hitaita |
| Indeksejä | Vähän | Paljon |
| Normaalimuoto | Pitkälle normalisoitu | Denormalisoitu |
| Palvelee | Lähes kaikkia asiakkaita | Osaa käyttäjistä |
| Käyttötapa | Toistuvaa, ennustettavissa | Rakenteeton, heuristinen, ennustamaton |
6.3 Tietovarastointi ja liiketoiminta
Tässä alaluvussa tarkastellaan tietovarastointiin liittyvien käsitteiden ja tekniikoiden kehittymistä liiketoiminnan näkökulmasta.
6.3.1 Tiedonlouhinta ja siihen liittyvä kehitys
Tiedonlouhinnalla (data mining) tarkoitetaan tilastomenetelmiin pohjautuvien algoritmien avulla toteutettua tiedon jalostamista suurista datamääristä käytettäväksi liiketoiminnan päätöksenteossa. Tiedonlouhinnan voisi yleisellä tasolla sanoa eroavan analyysistä monimutkaisuudellaan ja siten, että datan analysointi pyrkii vastaamaan ennalta määrättyyn kysymykseen, kun tiedonlouhinta puolestaan pyrkii etsimään mielenkiintoisia malleja datasta, vaikka loppukäyttäjä ei erityisesti mitään kysyisikään.
Tiedonlouhintaa voidaan soveltaa tietovarastoihin tai operatiivisiin tietokantoihin. Data täytyy ennen louhintaa valmistella louhittavaksi. Valmistelu voi pitää sisällään samantyyppisiä operaatioita kuin tietovarastoinnin käsittelyvaihe (transform):
- Erotetaan oikeellinen, virheellinen ja häiriöllinen data toisistaan. Häiriöllisellä (noisy) datalla tarkoitetaan dataa, jonka arvot ovat mahdollisesti virheellisiä, esimerkiksi 20% rekisteröityneistä käyttäjistä on syntynyt 1. tammikuuta.
- Päätetään, mitä tehdään puuttuvien arvojen suhteen. Esimerkiksi potilastiedoissa voi olla paljon tyhjäarvoja sukupuolesta tai iästä johtuen.
- Vähennetään louhittavien attribuuttien määrää niin, että tarkastellaan vain vertikaalisesti ositettua osajoukkoa datasta.
Tarkastellaan seuraavaksi muutamaa korkean tason esimerkkiä tiedonlouhintatekniikoista ja mitä niillä voidaan saavuttaa. Tekniikoiden jako perustuu löyhästi lähteeseen Leskovec, Rajaraman & Ullman (2014). Esitys ei ole kattava.
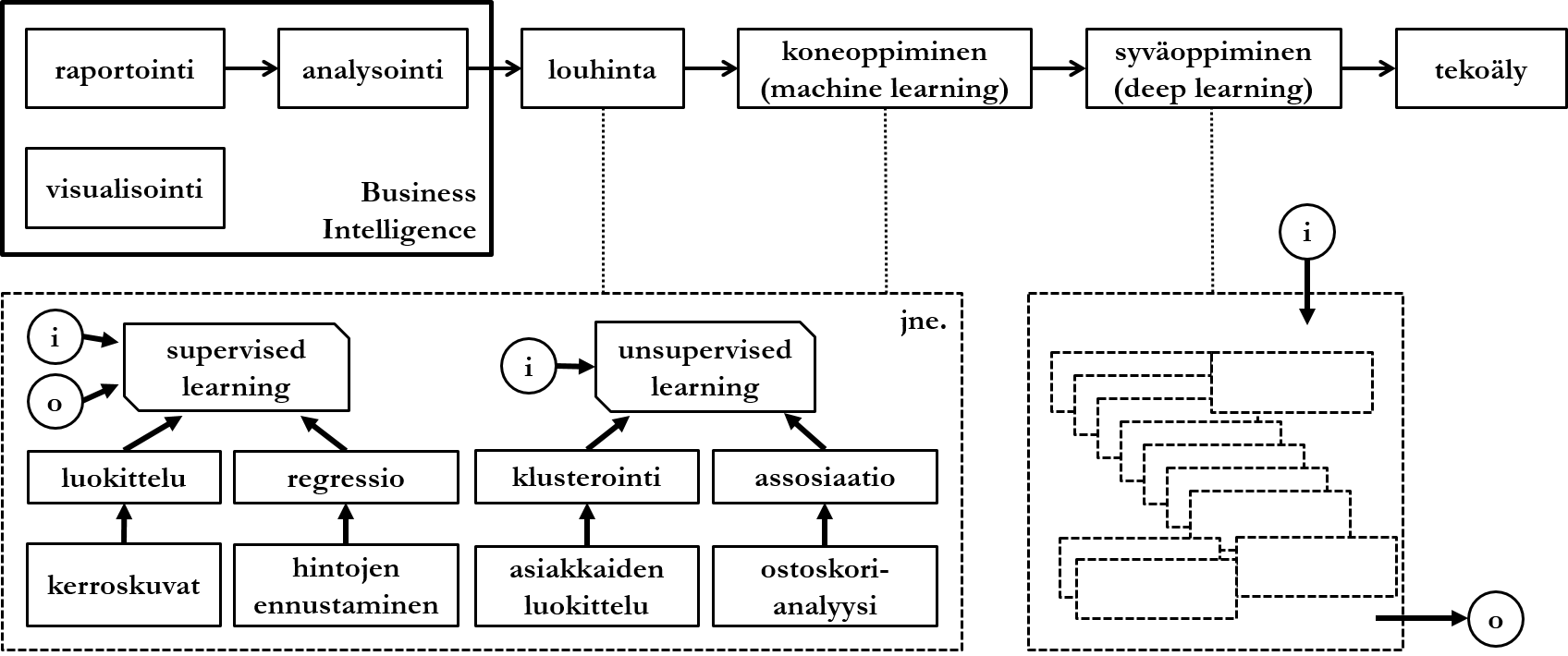
6.3.1.1 Ohjattu oppiminen
Tiedonlouhintatekniikat jaetaan usein ohjattuun (supervised), ohjaamattomaan (unsupervised) ja puoliohjattuun (semisupervised) oppimiseen (learning). Ohjattu oppiminen on yleisnimitys tekniikoille, jotka toimivat annetun syötteen ja odotetun tulosteen mukaisesti. Yksinkertaistettuna tällä tarkoitetaan, että varsinaisen analysoitavan datan (syöte) lisäksi algoritmille annetaan oppimisaineisto (odotettu tuloste), jota vastaan syöte analysoidaan.
Luokittelu (classification) on yksi yleisimmistä tiedonlouhinnan sovellutuksista. Luokittelualgoritmit pyrkivät ennustamaan epäjatkuvien (diskreettien) muuttujien arvoja perustuen muiden muuttujien arvoihin datassa:
- Yhtään demotehtävää tekemättömän opiskelijan kurssiarvosana on tavallisesti hylätty.
- Asiakas A käyttää luottokorttiaan tavallisesti Suomessa, Ruotsissa tai Virossa.
- Kerroskuvista voidaan tunnistaa, että tällä potilaalla ei ole keuhkosyöpää.
Luokittelualgoritmien tulosten perusteella voidaan ryhtyä jatkotoimenpiteisiin. Järjestelmä, joka toimii opiskelijan oppimisen tukena voi lähettää opiskelijalle muistutuksen demotehtävistä, tai pankki voi estää asiakkaan luottokortin käytön poikkeamiin perustuen.
Regressioalgoritmit pyrkivät ennustamaan jatkuvien muuttujien arvoja perustuen muiden muuttujien arvoihin datassa:
- Omakotitalojen myyntihinnat todennäköisesti nousevat seuraavalla kvartaalilla potentiaalisten ostajien määrän kasvaessa.
- Lisättyyn todellisuuteen liittyvien laitteiden maailmanlaajuinen liikevaihto ylittänee 100 miljardin euron rajan vuonna 2020.
Regressioalgoritmien toiminta perustuu historiallisen datan, ns. aikasarjadatan analysointiin. Yleinen tekniikka regressioalgoritmien toteuttamiseen on neuroverkot.
6.3.1.2 Ohjaamaton oppiminen
Ohjaamattomalla oppimisella tarkoitetaan tekniikoita, joilla ei ole erityistä, ennalta annettua kysymystä tai asettelua, vaan jotka pyrkivät etsimään mielenkiintoisia malleja datasta. Algoritmeille annetaan ainoastaan syöte.
Klusterointi- tai ryhmittelyalgoritmit pyrkivät jakamaan dataa ryhmiin datan ominaisuuksien mukaan:
- Asiakkaat X, Y ja Z syövät paljon leipää, koska he ovat ostaneet viimeisen vuoden aikana ainakin kolme leivänpaahdinta.
- Virukset voidaan jakaa ryhmiin A, B, C ja D niiden sisältämän perintöinformaation määrän mukaisesti.
- Dokumentit J, K ja L käsittelevät kissoja, koska sana kissa mainitaan niissä useasti.
Ryhmittelyalgoritmien tuloksia visualisoidaan usein 2- tai 3-ulotteisilla neliöillä tai kuutioilla, jossa akselit kuvaavat joukkojen kannalta relevanttien attribuuttien arvoja. Yksinkertaista ryhmittelyä on esimerkiksi TF-IDF-metodi (term frequency-inverse document frequency), jolla voidaan selvittää miten relevantti jokin sana on dokumentissa, kun datana on joukko dokumentteja:
")
Jossa:
 on sanan
on sanan  lukumäärä dokumentissa
lukumäärä dokumentissa  ,
, on dokumentissa esiintyvän yleisimmän sanan
on dokumentissa esiintyvän yleisimmän sanan  lukumäärä,
lukumäärä, on dokumenttien lukumäärä ja
on dokumenttien lukumäärä ja on dokumenttien lukumäärä, jossa sana esiintyy ainakin kerran.
on dokumenttien lukumäärä, jossa sana esiintyy ainakin kerran.
Assosiaatioalgoritmit pyrkivät etsimään eri muuttujien välisiä korrelaatioita datassa:
- Käyttäjät X ja Y tuntevat toisensa, koska he lähettävät paljon sähköpostia toisilleen.
- Lääkkeistä A ja B aiheutui eniten sivuvaikutuksia H, K ja L ikäryhmille P ja Q.
- Asiakkaat, jotka ostavat tuotetta X ostavat todennäköisesti myös tuotetta Y.
- Asiakaskertomuksia lukeneet asiakkaat eivät tavallisesti tee sähkösopimusta.
- Tilauksen tekeminen peruutetaan yleensä maksutavan valinta -vaiheessa.
Termi tiedonlouhinta alkoi yleistyä jo 1990-luvulla. Tekniikoiden kehittyessä ja laajentuessa kattamaan lisää erilaisia algoritmeja, lanseerattiin termi koneoppiminen (machine learning). Käsitteiden raja on häilyvä, ja tämän kurssin puitteissa ne voi käsittää synonyymeiksi. Syväoppimisella (deep learning) tarkoitetaan yksinkertaistaen erilaisten tiedonlouhintatekniikoiden yhdistämistä sellaiseksi kokonaisuudeksi, joka jäljittelee monimutkaisuudellaan ihmisen päätöksentekoa. Käytännössä tämä tarkoittaa, että koneen ns. päättelyketjua tietystä syötteestä tiettyyn tulosteeseen on haastava jäljittää.
6.3.2 Tiedonhallinta ja siihen liittyvä kehitys
Tietovarastointi on perinteisesti perustunut rakenteisen datan tallentamiseen niin, että lähdedatasta suodatetaan ainoastaan haluttu data, joka sen jälkeen muunnetaan sopivaksi tietovarastoon. Tarvittaessa dataa voidaan palauttaa lähdejärjestelmiin. Uusien tekniikoiden ja kohdealueiden (esim. sosiaalinen media ja erilaiset IoT-laitteet) yleistymisen myötä nouseva trendi ovat olleet ns. data lake -ratkaisut. Data lake eroaa tietovarastosta rakenteettomuudellaan: sinne kerätään tavallisesti kaikki data lähdejärjestelmistä, eikä dataa pakoteta ennalta määrättyyn rakenteeseen, kuten relaatiotietokannan tauluihin.
Data lake -ratkaisuja kuvataan tavallisesti matalaksi ja laajaksi järveksi, jossa on paljon dataa monesta eri lähdejärjestelmästä. Kun data halutaan raportoida, analysoida tai louhia, sille luodaan tehtävään soveltuva rakenne. Siinä missä tietovarastojen tekninen toteutus perustuu usein perinteisiin ja kypsiin (usein myös kaupallisiin) relaatiotietokannanhallintajärjestelmiin, data lake -ratkaisuihin käytetään kypsyysasteeltaan tuoreempia tekniikoita, joista suosituin lienee Apache Hadoop -viitekehys.
Data lake -ratkaisun potentiaalisena ongelmana nähdään datan räjähdysmäinen kasvu, ja rakenteettoman datan sekoittuminen toisiinsa ilman tehokasta metadatan hallintaa. Gartner käyttää epäonnistuneesta data lake -toteutuksesta kuvaavaa nimeä data swamp, jolla viitataan tärkeän tiedon uppoamiseen tarpeettomaan dataan. Tietovarastointi- ja data lake -tekniikoiden parhaiden puolien yhdistämiseen perustuvaa ratkaisua kutsutaan nimellä data vault. Data vault on tavallisesti ratkaisu, jossa käytetään sekä rakenteista relaatiotietokantaa että rakenteetonta data lake -ratkaisua rinnakkain.
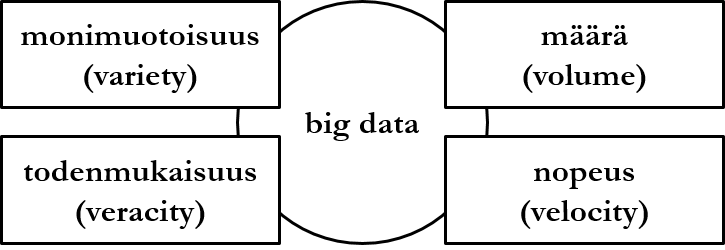
Muun muassa data lake -ratkaisuihin liittyy käsite big data. Se on yleisnimitys suurelle määrälle tietynlaista dataa, sekä tällaisen datan hallintaan liittyville tekniikoille ja haasteille. Big data määritellään datan määrän (volume) lisäksi kolmella ominaispiirteellä:
- Monimuotoisuudella (variety) tarkoitetaan, että data ei ole rakenteellista, esim. relaatiotietokannan näkökulmasta data ei sijaitse ennalta määritellyissä tauluissa ja niiden nimetyissä, tietotyypiltään määrätyissä sarakkeissa.
- Todenmukaisuudella (veracity) tarkoitetaan, että data tunnustetaan mahdollisesti osittain virheelliseksi, jolla voidaan tarkoittaa esim. vanhentunutta, ristiriitaista tai puutteellista dataa.
- Nopeudella (velocity) tarkoitetaan, että datavirta on jatkuvaa ja dataa virtaa tietokantaan runsaasti.
These are the current permissions for this document; please modify if needed. You can always modify these permissions from the manage page.