Datan hallintakieli (DML)
Luku videoina
Video on koostettu Toni Taipaluksen kevään 2023 luentonauhoitteista. Videolla mainitut viittaukset demoihin tai tenttiin eivät pidä paikkaansa keväällä 2024. Ajankohtaiset tiedot kurssin suorittamisesta löytyvät etusivulta.
Luku tekstinä
Datan hallintakieli (Data Management Language, DML) muodostaa suuren osan SQL-kielestä. Sen avulla tietokannasta voidaan mm. etsiä SELECT, lisätä INSERT, muokata UPDATE ja poistaa DELETE dataa. Seuraavaksi tarkastellaan näitä neljää komentoa.
4.3.1 Luentoesimerkkien tietokanta
Seuraavat osiot sisältävät interaktiivisia tehtäviä. Voit kokeilla ajaa valmiiksi kirjoitettuja SQL-lauseita ja voit myös muokata niitä. Hakulauseiden luentoesimerkkien tietokannanhallintajärjestelmä on SQLite.
Kokeile alkuun tietokannan toimivuutta alla olevalla interaktiivisella tehtävällä. Painamalla alla olevan esimerkin Aja-painiketta luentoesimerkkien tietokanta ladataan ja tulosteena näytetään kaikki tietokannassa olevien taulujen nimet.
Alla on esitetty interaktiivisissa esimerkeissä käytetyn tietokantasi kaava eli skeema.
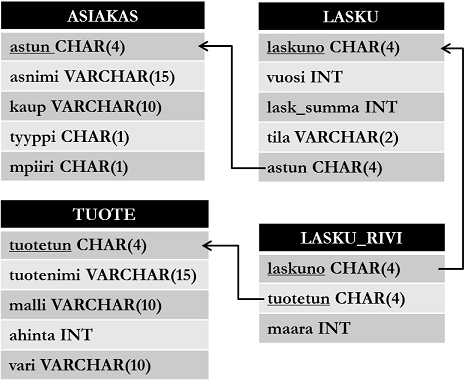
Voit tarkastella tietokannan luomiseksi käytettyä koodia osoitteesta
https://tim.jyu.fi/files/kurssit/tie/itka2004/kurssimoniste/sqlite_luentoesim.sql
Tietokannassa on neljä taulua: asiakas, tuote, lasku ja lasku_rivi. Taulujen nimi on esitetty suorakulmion ensimmäisellä rivillä ja taulun sarakkeiden nimet tietotyyppeineen seuraavilla. Viiteavaimet on esitetty viivoilla. Kunkin taulun rivi kuvastaa seuraavaa tietoa:
- Asiakkaalla (
astun) on nimi (asnimi), asuinkaupunki (kaup), asiakkuuden tyyppi (tyyppi) joukosta {'y' = yritysasiakas, 'h' = henkilöasiakas} ja myyntipiiri (mpiiri) joukosta {'i' = itä, 'l' = länsi, 'e' = etelä, 'p' = pohjoinen, 'k' = keski}. - Tuotteella (
tuotetun) on nimi (tuotenimi), malli (malli), yksikköhinta (ahinta) ja väri (vari). - Laskulla on laskunumero (
laskuno), laskutusvuosi (vuosi), laskun yhteissumma (lask_summa), tila (tila) joukosta {'m' = maksettu, 'l' = laskutettu, 'k' = karhuttu} sekä asiakas, jota on laskutettu (astun). - Lasku_rivi kuvaa mitä tuotetta (
tuotetun) on laskutettu milläkin laskulla (laskuno) ja kuinka monta kappaletta (maara).
4.3.2 Yhteen tauluun kohdistuvat hakulauseet
Tarkastellaan ensin yhteen tauluun kohdistuvia hakulauseita, hakulauseen yleistä muotoja ja erilaisia ehtolausekkeita.
4.3.2.1 Hakulauseen yleinen muoto
SQL-hakulause eli SELECT-lause koostuu yksinkertaisimmillaan kahdesta osasta. SELECT-osassa luetellaan pilkkulistalla ne sarakkeet, joiden arvoja tulostauluun halutaan. Tulostaulun otsake (header) muodostuu tämän listan perusteella. Ensimmäiseksi luetellusta sarakkeesta tulee tulostaulun vasemmanpuoleinen sarake jne. FROM-osassa luetellaan pilkkulistalla ne taulut, joista tietoa etsitään. FROM-osan sisältöä kutsutaan myös taulujen esittelyksi.
Kyselyn voisi lukea auki myös näin: "Hae asiakas-taulun astun-, asnimi-, kaup-, tyyppi- ja mpiiri-sarakkeiden arvot".
4.3.2.2 Ehtolausekkeet ja tulosten rajaus
Hakulauseen yleinen muoto SELECT...FROM...; noutaa taulusta kaikki rivit. Kun tuloksia halutaan rajata, käytetään ehtolausekkeita, jotka sijoitetaan lauseen WHERE-osaan. WHERE-osa sijoittuu FROM-osan jälkeen:
4.3.2.2.1 Vertailuoperaattorit
Vertailuoperaattoreita ovat =, <, >, >=, <=, <>, !=, joista kaksi viimeistä tarkastavat erisuuruutta. Tähteä * voidaan käyttää kuvaamaan taulun kaikkia sarakkeita alla olevan esimerkin mukaisesti.
Ehtolausekkeita voidaan yhdistää toisiinsa loogisilla operaattoreilla AND (ja) ja OR (tai) sekä edelleen sulkeilla. Jos lauseen WHERE-osassa käytetään vain AND-operaattoreita, ehtolausekkeiden järjestyksellä ei ole tulosten kannalta merkitystä.
4.3.2.2.2 Merkkijonojen vertailu
Merkkijonojen vertailuun voidaan käyttää vertailuoperaattoreita tai [NOT] LIKE -predikaattia. Vertailtava merkkijono kirjoitetaan heittomerkkien ' sisään. Kirjainkoolla heittomerkkien sisällä on tavallisesti merkitystä, kuitenkin tuotteesta ja sen asetuksista riippuen. SQLitessä oletusarvoisesti kirjainkoolla ei ole merkitystä.
LIKE-predikaattia käytettäessä voidaan käyttää lisäksi seuraavia jokerimerkkejä:
- Alaviiva
_vastaa yhtä mitä tahansa merkkiä. - Prosenttimerkki
%vastaa 0..n kappaletta mitä tahansa merkkiä. Ts. prosenttimerkki vastaa mitä tahansa merkkijonoa (myös tyhjää).
Tehtävä: Muuta yllä olevaa SQL-hakulausetta siten, että se hakee kaikkien K:lla ja L:llä alkavien asiakkaiden nimet, joiden nimi ei kuitenkaan lopu merkkijonoon Oy.
Kuten aritmeettiset operaatiot, jotkin operaattorit ovat SQL:ssä etuoikeutetumpia kuin toiset. Esimerkiksi siinä missä tulo lasketaan ennen summaa, SQL:ssä AND tarkastetaan ennen OR-operaattoria. Jos halutaan tarkastaa OR ennen AND-operaattoria, lauseen suoritusjärjestystä voidaan ohjata sulkeilla kuten matematiikassa, eli sulkeiden sisällä olevat asiat suoritetaan ensin. Oletetaan seuraava tietotarve:
Yllä olevassa lauseessa suoritusjärjestys on ohjattu sulkeilla: ensin tarkastetaan, että tuotenimi on kumpi kumpi halutuista (OR), ja sitten onko hinta jompi kumpi halutuista (OR), ja lopuksi, että sekä nimen että hinnan ehdot pätevät (AND).
Jos sulkeita ei käytettäisi, muuttuisi lauseen logiikka seuraavilla tavoilla:
- Jos jätetään pois kaikki sulkeet, hyväksytään sellaiset tuotteet, joiden nimi alkaa t-kirjaimella. Hyväksytään myös sellaiset tuotteet, joiden nimi alkaa s-kirjaimella ja joiden hinta on yli 200. Hyväksytään myös sellaiset tuotteet, joiden hinta on alle 20.
- Jos jätetään pois ainoastaan alemmat sulkeet eli hinnan tarkastukset ympäröivät sulkeet, hyväksytään sellaiset tuotteet, joiden nimi alkaa t- tai s-kirjaimella, ja joiden hinta on yli 200. Hyväksytään myös sellaiset tuotteet, joiden hinta on alle 20.
- Jos jätetään pois ainoastaan ylemmät sulkeet eli tuotenimen tarkastukset ympäröivät sulkeet, hyväksytään sellaiset tuotteet, joiden nimi alkaa t-kirjaimella. Hyväksytään myös sellaiset tuotteet, joiden nimi alkaa s-kirjaimella ja joiden hinta on yli 200 tai alle 20.
4.3.2.2.3 Tyhjäarvon vertailu
Tyhjäarvo ei ole varsinaisesti arvo, vaan merkintätapa tuntemattomalle arvolle. Jos tyhjäarvoa yritetään vertailla vertailuoperaattoreilla, palautetaan aina tyhjäarvo. Tähän asti ehtolausekkeita on tarkasteltu kaksiarvoisen logiikan mukaisesti, esim. ehtolauseke ahinta > 100 palauttaa joko arvon TRUE (tosi) tai FALSE (epätosi) riippuen siitä, mikä arvo rivin ja sarakkeen leikkauskohdassa on. Tyhjäarvon johdosta SQL toimii kolmiarvoisella logiikalla seuraavan totuustaulun mukaisesti.
| p | q | p AND q | p OR q |
|---|---|---|---|
| TRUE | TRUE | TRUE | TRUE |
| TRUE | FALSE | FALSE | TRUE |
| FALSE | FALSE | FALSE | FALSE |
| TRUE | UNKNOWN | UNKNOWN | TRUE |
| FALSE | UNKNOWN | FALSE | UNKNOWN |
SQL:ssä tyhjäarvoa kuvataan avainsanalla NULL. Tyhjäarvon esiintymistä tarkastetaan predikaatilla IS [NOT] NULL, ei koskaan vertailuoperaattorilla.
4.3.2.2.4 Muita tapoja vertailuun
Vertailuoperaattoreiden ja LIKE-predikaatin lisäksi SQL-standardissa on muita, tilanteesta riippuen vaivattomampia tapoja vertailuun. [NOT] IN -predikaatilla voidaan tarkastaa, kuuluuko arvo johonkin joukkoon. Sitä käyttäen voidaan esim. kiertää tilanteita, joissa muuten jouduttaisiin kirjoittamaan lukuisia, samaa saraketta koskevia vertailuja OR-operaattoria käyttäen. [NOT] IN -predikaatille annetaan hyväksyttävä arvojoukko sulkeiden sisään pilkkulistalla. Huomaa, että jokerimerkkien käyttö ei ole sallittua.
Tehtävä: muuta yllä olevaa esimerkkilausetta muotoon: "hae kouvolalaisten ja mikkeliläisten asiakkaiden kaikki tiedot". Käytä IN-predikaattia.
[NOT] BETWEEN -predikaatti tarkastaa, onko sarakkeen arvo halutulla välillä. Syntaksi on sarake BETWEEN arvo1 AND arvo2, jossa arvo1 on pienempi ja arvo2 suurempi. Predikaatilla voidaan vertailla myös merkkijonoja ja päivämääriä. Huomaa, että myös raja-arvot hyväksytään tuloksiin.
4.3.2.3 Tulosten järjestäminen
Tähän asti käsitellyissä esimerkeissä tulostaulun rivien järjestys on ollut tietokannanhallintajärjestelmän päättämä. Tulostaulun voi järjestää mieleisekseen ORDER BY -määreellä. Se sijoittuu tähän mennessä käsiteltyjen lauseenosien jälkeen:
Tulostaulu voidaan järjestää sen kaikkien sarakkeiden mukaan, tai vain osan. Jos ORDER BY -määrettä käytetään, sarakkeen arvot järjestetään oletusarvoisesti nousevaan järjestykseen (ASC eli ascending). Järjestys voidaan kääntää laskevaan järjestykseen lisämääreellä DESC (descending).
4.3.3 Useaan tauluun kohdistuvat hakulauseet
Tähän mennessä käsitellyt hakulauseet ovat kohdistuneet yhteen tauluun kerrallaan. On kuitenkin tavallista, että tuloksia halutaan rajata edelleen, jolloin ehtolausekkeita täytyy kohdistaa useampaan kuin yhteen tauluun.
Tärkein useamman kuin yhden taulun käsittelyyn liittyvä käsite on liitosehto. Liitosehdon avulla tarkastetaan, löytyykö kahdesta eri taulusta sama sarakkeen arvo. Liitos taulujen välillä sijoitetaan lauseen WHERE-osaan, ja se voidaan toteuttaa eri tavoin. Seuraavaksi tarkastellaan erilaisia tapoja toteuttaa liitosehto.
4.3.3.1 Liitos IN-predikaattia käyttäen
Yksi tapa toteuttaa liitos on ns. alikyselyllä, jolloin lauseen WHERE-osassa aloitetaan uusi, SELECT-käskyllä alkava hakulause. Liitosehto voidaan toteuttaa IN-predikaattia käyttäen. Kiinnitä huomiota siihen, mikä taulu esitellään missäkin FROM-osassa:
Tarkastellaan tarkemmin, mitä yllä olevassa lauseessa tapahtuu. Tietokannan tuote-taulussa on listattuna kaikkien tietokannassa olevien tuotteiden tiedot. Tietokannan lasku_rivi-taulussa on puolestaan listattuna sellaisten tuotteiden tuotetunnukset, joita koskee jokin lasku, ts. joista on joskus laskutettu jotakuta asiakasta. Toisin sanoen, tuote-taulussa on tallennettuna kaikki tuotteet, mutta lasku_rivi-taulussa vain tuotteiden tuotetunnuksien osajoukko.
IN-predikaatista muistamme, että sillä tarkastetaan, kuuluuko vertailtavan sarakkeen arvo johonkin joukkoon. Tässä IN-predikaatin oikealle puolelle ei olekaan asetettu pilkkulistaa hyväksyttävistä arvoista, vaan alikysely. IN-predikaatin vasemmalla puolella on tuote-taulun tuotetun-sarakkeen arvo, oikealla puolella puolestaan lasku_rivi-taulun tuotetun-sarakkeen arvo. Kyselyn voisi lukea auki myös näin: "Hae sellaisten tuotteiden tuotenimet, joiden tuotetunnus on tallennettu myös lasku_rivi tauluun" tai "Hae sellaisten tuotteiden tuotenimet, joiden tuotetunnus esiintyy ainakin kerran lasku_rivi-taulussa" tai "Hae sellaisten tuotteiden tuotenimet, joista on laskutettu ainakin kerran".
Miten lause sitten suoritetaan? Alikyselyä voisi ajatella kahtena sisäkkäisenä silmukkana:
- Valitaan tuote-taulun ensimmäiseltä riviltä tuotetun-sarakkeen arvo x.
- Verrataan x:ää lasku_rivi-taulun ensimmäisen rivin tuotetun-sarakkeen arvoon y.
- Jos ehtolauseke x = y saa arvokseen
TRUE(ts. arvot ovat samat), sijoitetaan tuote-taulun x:ää vastaavan rivin tuotenimi-sarakkeen arvo tulostauluun. Siirrytään kohtaan 3. - Jos ehtolauseke x = y saa arvokseen jotakin muuta (
FALSEtaiUNKNOWN), tarkastetaan lasku_rivi-taulun seuraavan rivin sarakkeen tuotetun-arvo, ja verrataan sitä x:ään. Jos lasku_rivi-taulun miltään riviltä ei löydy x:ää vastaavaa arvoa, siirrytään kohtaan 3.
- Jos ehtolauseke x = y saa arvokseen
- Valitaan tuote-taulun seuraavalta riviltä tuotetun-sarakkeen arvo x ja siirrytään kohtaan 2., kunnes tuote-taulun viimeinenkin rivi on tarkastettu.
- Materialisoidaan tulostaulu.
Liitosehdoilla voidaan saman periaatteen mukaan toteuttaa monimutkaisempiakin kyselyitä. Esimerkiksi alla oleva, luonnollisella kielellä esitetty hakulause voi tietokannan rakenteesta riippuen näyttää SQL:llä esitettynä monimutkaiselta:
Yllä olevan lauseen voisi lukea auki myös näin: "Hae sellaisten asiakkaiden nimet ja tyypit, joiden asiakastunnus on tallennettu myös lasku-tauluun, ja vastaavan lasku-taulun rivin laskuno-sarakkeen arvo on tallennettu myös lasku_rivi-tauluun, ja vastaavan lasku_rivi-taulun rivin tuotetun-sarakkeen arvo on tallennettu myös tuote-tauluun, ja tuotetaulussa vastaavan rivin tuotteen väri on musta".
"Hae sellaisten asiakkaiden nimet ja tyypit,":
"…joiden asiakastunnus on tallennettu myös lasku-tauluun,":
"…ja vastaavan lasku-taulun rivin laskuno-sarakkeen arvo on tallennettu myös lasku_rivi-tauluun,":
"…ja vastaavan lasku_rivi-taulun rivin tuotetun-sarakkeen arvo on tallennettu myös tuote-tauluun,":
"…ja tuotetaulussa vastaavan rivin tuotteen väri on musta":
Miten useaa taulua käsittävää hakulausetta voisi lähteä suunnittelemaan?
- Ensin on syytä tarkastella tietokannan kaavaa ja tunnistaa ne taulut, joista tietoa halutaan tulostauluun (yllä olevassa esimerkissä asiakas-taulu).
- Seuraavaksi etsitään ne taulut, joiden sarakkeisiin täytyy kohdistaa ehtolausekkeita (tässä tapauksessa tuote-taulu), tällaisia ehtolausekkeita kutsutaan myös sisällöllisiksi ehdoiksi.
- Seuraavaksi tarkastellaan, mitä muita tauluja mahdollisesti tarvitaan, jotta jo kyselyn kannalta relevanteiksi luokitellut taulut voidaan liittää liitosehdoilla.
- Lopuksi ennen varsinaisen lauseen kirjoittamista täytyy tunnistaa, millä sarakkeilla liitosehdot voidaan tehdä. Esimerkiksi tässä tapauksessa asiakas- ja tuote-taulua ei voida edes teoriassa liittää suoraan toisiinsa, sillä niissä ei ole yhtäkään yhteistä saraketta.
4.3.3.2 Liitos EXISTS-predikaattia käyttäen
Alikyselyyn perustuva liitos voidaan tehdä myös käyttämällä EXISTS-predikaattia. Syntaksi eroaa hieman IN-predikaatista, sillä varsinainen liitosehto tehdään vasta alikyselyn WHERE-osassa. EXISTS-predikaatilla tarkastetaan, onko ehdot täyttäviä rivejä olemassa. Jos alikysely tuottaa totuusarvon TRUE edes yhdelle riville, valitaan pääkyselyssä esitellystä taulusta vastaavan rivin halutun sarakkeen arvo tulostauluun.
Vastaava kysely näyttäisi IN-predikaatilla toteutettuna tältä:
Alikyselyt tuovat mukanaan uuden käsitteen: näkyvyysalueen. Näkyvyysalueella tarkoitetaan SQL-lauseessa sitä, missä kohdassa lausetta jonkin sarakkeen tai taulun nimeä voidaan käyttää. Alikyselyssä esiteltyihin tauluihin tai niiden sarakkeisiin ei voi viitata ylemmän tason kyselyssä, mutta ylemmän tason kyselyssä esiteltyihin tauluihin ja niiden sarakkeisiin voidaan viitata alikyselyssä. Toisin sanoen, pääkysely ei ole tietoinen lasku_rivi-taulusta, mutta alikysely on tietoinen lasku_rivi-taulun lisäksi pääkyselyssä esitellystä tuote-taulusta.
Näkyvyysalueet ja useamman kuin yhden taulun esittely tuovat mukanaan ongelman: viitattaessa tuotetun-sarakkeeseen tietokannanhallintajärjestelmä ei tiedä, tarkoitetaanko lauseessa tuote- vai lasku_rivi-taulun tuotetun-saraketta. Tästä syystä on käytettävä tarkentimia (correlation name). Tarkentimena voi käyttää taulun nimeä, kuten yllä, tai sen voi esitellä itse lauseen FROM-osassa syntaksilla:
Itse määritelty tarkennin voi olla mikä tahansa nimeämissääntöjä noudattava merkkijono. Itse määritelty tarkennin voi vähentää kirjoitustyötä huomattavasti. Esimerkiksi yllä esitetty esimerkki voitaisiin kirjoittaa myös omia tarkentimia käyttäen:
Yllä olevan esimerkin pääkyselyn SELECT-osassa tarkentimen t käyttö ei ole välttämätöntä, koska tuotenimi-niminen sarake on vain tuote-taulussa. Koska liitosehto tehdään alikyselyn WHERE-osassa, EXISTS-predikaatilla toteutetun alikyselyn SELECT-osan sisällöllä ei ole merkitystä. Tavallisesti käytetään tähtimerkkiä tai yhtä numeroa.
4.3.3.3 Liitos vertailuoperaattoria käyttäen
Kahden tai useamman taulun liitos voidaan tehdä myös ilman alikyselyä. Yksi tapa liitoksen tekemiseen ilman alikyselyä on vertailuoperaattorin käyttäminen. Tällaista liitosta kutsutaan yksitasoiseksi tai implisiittiseksi liitokseksi.
Kuten aikaisemmin esitellyissä liitoksissa IN- ja EXISTS-predikaatteja käyttäen, yllä olevassa lauseessa tarkastetaan, vastaako tuote-taulun tuotetun-sarakkeen arvo jotakin lasku_rivi-taulun tuotetun-sarakkeen arvoa. Koska lasku_rivi-taulussa sama tuotetun-sarakkeen arvo voi kertautua ja tässä tapauksessa kertautuu, tulostauluun valitaan toisteisia rivejä. Toisteiset rivit on poistettu tulostaulusta DISTINCT-lisämääreellä. DISTINCT-lisämääre sijoitetaan lauseen SELECT-osaan heti SELECT-avainsanan jälkeen kuten yllä.
4.3.3.4 Sisäliitos
Sisäliitos on SQL-standardin kolmannessa versiossa (SQL-92) lisätty tapa toteuttaa liitoksia. Sisäliitosta kutsutaan myös eksplisiittiseksi liitokseksi, ja se toteutetaan JOIN -predikaatilla seuraavan syntaksin mukaisesti:
Aikaisemmissa esimerkeissä IN- ja EXISTS-predikaateilla sekä vertailuoperaattoria käyttämällä toteutettu kysely näyttäisi eksplisiittisellä liitoksella toteutettuna seuraavalta:
Yhdisteen UNION avulla voidaan liittää kahden tai useamman hakulauseen tulostaulut toisiinsa. Hakulauseiden tulostauluissa tulee olla yhtä monta saraketta.
Edellisessä esimerkissä on myös esitelty uusi SQL-avainsana AS. Sen avulla voidaan mm. nimetä uudelleen tulostaulun sarakkeita. Yllä olevassa esimerkissä tulostaulun ainoalle sarakkeelle on annettu nimi mallit_ja_tuotenimet. AS-predikaatti on käyttökelpoinen erityisesti, kun tulostaulussa on koostefunktioiden tuottamia sarakkeita. Koostefunktioita käsitellään myöhemmin.
4.3.4 Koostefunktiot
Koostefunktioita (set tai aggregate function) käytetään laskutoimitusten suorittamiseen, niille annetaan tavallisesti yksi parametri ja ne palauttavat yhden arvon. Koostefunktiot sijoitetaan hakulauseessa SELECT- tai HAVING-osaan. HAVING esitellään myöhemmin. Seuraavaksi esitellään tavallisimmat koostefunktiot summa, lukumäärä, minimi, maksimi ja keskiarvo.
4.3.4.1 Summa ja lukumäärä
Koostefunktio summa SUM laskee ja palauttaa sarakkeessa esiintyvien arvojen summan. SUM käsittelee tyhjäarvoa NULL kuten nollaa, ts. 1 + 0 + 3 = 4 ja 1 + NULL + 3 = 4. Seuraavassa esimerkissä koostefunktiolle on annettu parametriksi tuote-taulun ahinta-sarake, ja tulostaulun ainoa sarake on nimetty AS-predikaatilla. Jos saraketta ei nimetä AS-predikaatilla, tietokannanhallintajärjestelmä nimeää sarakkeen.
Koostefunktio lukumäärä COUNT laskee ja palauttaa arvojen lukumäärän. COUNT ei laske tyhjäarvoja. Seuraavassa esimerkissä on laskettu asiakas-taulun rivien lukumäärä käyttämällä koostefunktion parametrina tähteä.
Silloin tällöin pelkkä arvojen esiintymien lukumäärän laskeminen ei tuota haluttua tulosta, sillä oletusarvoisesti COUNT-koostefunktio laskee arvot riippumatta siitä, mikä arvo on. Jos halutaan laskea erilaisten arvojen määrä, voidaan käyttää DISTINCT-lisämäärettä.
Yllä oleva esimerkki laskee toisin sanoen asiakas-taulun kaup-sarakkeessa esiintyvien erilaisten arvojen lukumäärän.
Tehtävä: kokeile ajaa yllä oleva lause ilman DISTINCT-lisämäärettä. Miksi tulos muuttuu? Mihin tulos perustuu?
4.3.4.2 Minimi, maksimi ja keskiarvo
Koostefunktio minimi MIN palauttaa sarakkeessa esiintyvän pienimmän arvon, koostefunktio maksimi MAX puolestaan suurimman. Seuraavassa esimerkissä on laskettu koostefunktioiden palauttamien arvojen erotus.
Koostefunktio keskiarvo AVG laskee sarakkeen arvojen keskiarvon. Koostefunktio AVG laskee summan kuten SUM-koostefunktio, lukumäärän kuten COUNTkoostefunktio ja palauttaa näiden osamäärän.
4.3.4.3 Ryhmittely
Edellisen esimerkin SQL-kysely siis palauttaa kaikkien tuotteiden hintojen keskiarvon. Usein koostefunktioita halutaan kuitenkin käyttää monimutkaisempiin laskutoimituksiin, esimerkiksi tuotteiden hintakeskiarvojen laskemiseen tuoteväreittäin, ts. jokaista väriä kohden. Tällöin tarvitaan ryhmittelyä, joka tapahtuu GROUP BY -määreellä:
Ryhmittely vaaditaan, jos yksikin tulostaulun sarake on muodostettu koostefunktion avulla, ja tulostaulussa on lisäksi ainakin yksi projektiolla muodostettu sarake x (yllä olevassa esimerkissä sarake vari). Tällaista saraketta x kutsutaan ryhmitteleväksi sarakkeeksi. Jokainen ryhmittelyllä saavutettu tulostaulun ryhmä koostuu riveistä, jotka ovat ryhmittelevän sarakkeensa arvon suhteen samanlaisia. Yllä olevan esimerkin mukaisesti DBMS jakaa ensin tuote-taulun rivit ryhmiksi. Kukin ryhmä koostuu riveistä, joiden vari-attribuutin arvo on sama: esim. ensimmäiseen ryhmään kuuluvat rivit, jotka kuvaavat sinisiä tuotteita, toiseen ryhmään rivit, jotka kuvaavat punaisia tuotteita jne. Lopuksi lasketaan hintakeskiarvo erikseen jokaiselle ryhmälle ja materialisoidaan tulostaulu.
Ryhmitteleviä sarakkeita voi olla useampikin kuin yksi. GROUP BY -määreen käyttö vaaditaan, jos ainakin yksi tulostaulun sarake muodostetaan koostefunktiolla, ja ainakin yksi sarake ilman koostefunktiota (ts. ainakin yksi sarake on ryhmittelevä sarake). Tässä tapauksessa ryhmittely pitäisi tehdä jokaisen ryhmittelevän sarakkeen mukaisesti. GROUP BY -määre sijoittuu SQL-hakulauseessa heti lauseen WHERE-osan jälkeen. SQL-hakulauseen yleinen syntaksi näyttää siis tähän mennessä seuraavalta:
Tehtävä: Muuta yllä olevaa SQL-hakulausetta siten, että se hakeekin tuotteiden yksikköhintojen summan väreittäin ja malleittain. Rajaa pois tuotteista sellaiset, joiden hintaa ei ole määritetty. Tulokset järjestetään ensin värin ja sitten mallin mukaiseen, laskevaan aakkosjärjestykseen.
Silloin tällöin ryhmiteltyjä tuloksia täytyy rajata. Koostefunktion ja ryhmittelyn yhdistelmällä tuotettujen tulostaulun rivien määrää voidaan rajoittaa HAVING-predikaatilla. HAVING-osa sijoittuu lauseessa GROUP BY -osan jälkeen, mutta kuitenkin ennen mahdollista ORDER BY -osaa:
HAVING-osa toimii näennäisesti hieman samalla tavalla kuin aikaisemmin käsitelty WHERE-osa: siihen sijoitettujen ehtolausekkeiden avulla voidaan rajata kyselyn tuloksia. HAVING-osa eroaa kuitenkin WHERE-osasta seuraavilta osin:
HAVING-osaan voidaan sijoittaa koostefunktioita, toisin kuinWHERE-osaan.HAVING-osa suoritetaan vasta ryhmittelyn jälkeen, kun taasWHERE-osa suoritetaan ennen ryhmittelyä.- Edelliseen liittyen,
HAVING-osa vaatii ainaGROUP BY-osan.
4.3.5 Tyypillisiä ongelmia
Tarkastellaan ennen lisäämistä, poistamista ja muokkaamista käsittelevään osioon siirtymistä SQL-hakulauseiden tyypillisiä ongelmia, jotka vaikuttavat luonnollisella kielellä yksinkertaisilta.
4.3.5.1 Ei ole olemassa -tapaus
Silloin tällöin tuloksiin halutaan taulun sellaiset rivit, joihin viittaavia arvoja ei löydy jostakin muusta taulusta. Vertailuun voidaan käyttää NOT IN- tai NOT EXISTS -predikaattia:
NOT IN-predikaatti tarkastaa, onko yhtään vastaavaa riviä olemassa. Jos yksikin rivi täyttää alikyselyn ehdot (yllä olevassa esimerkissä siis sekä liitosehto että sisällöllinen ehto vuosi = 2011), ei pääkyselyn vastaavaa riviä hyväksytä tulostauluun. Yllä oleva lause voitaisiin lukea myös näin: "Hae sellaisten asiakkaiden asiakastunnukset ja nimet, joiden asiakastunnus ei ole lasku-taulussa yhdelläkään sellaisella rivillä, jossa laskun vuosi on 2011".
Sama kysely voidaan toteuttaa myös NOT EXISTS-predikaatilla. NOT EXISTS-predikaatin toiminta noudattaa kaksiarvoista (TRUE, FALSE) logiikkaa, ja tyhjäarvon vertailu tuottaa aina totuusarvon epätosi. Lauseiden syntaksi eroaa samoin kuin IN- ja EXISTS-predikaattien:
On syytä huomata, että ei ole olemassa -tapausta ei voida esittää ilman alikyselyä, ns. yksitasoisesti.
Alla on esitetty yleinen virhe ei ole olemassa -tapauksen käsittelystä.
Yllä oleva lause ei siis vastaa vaatimukseen "Hae sellaisten asiakkaiden asiakastunnukset ja nimet, joita ei ole koskaan laskutettu vuonna 2011." vaan vaatimukseen "Hae sellaisten asiakkaiden asiakastunnukset ja nimet, joita on laskutettu ainakin kerran jonakin muuna vuonna kuin 2011".
4.3.5.2 Alikyselyn tulosten vertailu vakioon
Alikyselyn tuloksia voidaan vertailla vakioon vertailuoperaattoria käyttämällä.
Yllä olevan esimerkin voisi lukea näin: "Hae niiden lasku_rivi-taulun laskujen numerot, joita koskevan tuotteen tuotetunnus löytyy myös tuote-taulusta ja tämän tuotteen yksikköhinta on alle 10 euroa."
Tehtävä: Pohdi, voisiko edellisen kyselyn kirjoittaa ilman alikyselyn tuloksiin perustuvaa vertailua.
Seuraavassa esimerkissä vakiota 2 verrataan alikyselyn tuloksiin. Alikyselyn tulos on koostefunktion palauttama luku.
Tietokannanhallintajärjestelmä voisi suorittaa yllä olevan esimerkkilauseen seuraavalla tavalla.
- Valitaan asiakas-taulun ensimmäinen rivi asiakas1.
- Valitaan lasku-taulun ensimmäinen rivi lasku1.
- Verrataan lasku1:n ja asiakas1:n astun-sarakkeen arvoja toisiinsa.
- Jos ehtolauseke a.astun = l.astun saa arvokseen tosi, lisätään koostefunktion palauttamaa arvoa yhdellä ja siirrytään vertailemaan asiakas1:n astun-sarakkeen arvoa lasku1:n seuraavan rivin astun-sarakkeen arvoon.
- Jos ehtolauseke saa arvokseen epätosi tai tuntematon, siirrytään vertailemaan asiakas1:n astun-sarakkeen arvoa lasku1:n seuraavan rivin astun-sarakkeen arvoon.
- Kun kaikki asiakas1-rivin astun-sarakkeen arvoa on verrattu kaikkiin lasku-taulun astun-sarakkeen arvoihin, siirrytään kohtaan 4.
- Tarkastetaan ehtolauseke, jonka vasemmalla puolella on vakio 2 ja oikealla puolella koostefunktion
COUNTpalauttama kokonaisluku.- Jos ehtolauseke on tosi, hyväksytään asiakas1-rivin halutut sarakkeet (eli asnimi, kaup) tulostauluun.
- Jos ehtolauseke on epätosi, hylätään asiakas1-rivi.
- Valitaan asiakas-taulun seuraava rivi tarkasteltavaksi.
- Jos asiakas-taulussa on rivejä tarkastelematta, siirrytään kohtaan 2.
- Jos asiakas-taulussa ei ole rivejä tarkastelematta, siirrytään kohtaan 6.
- Materialisoidaan tulostaulu.
Alikyselyn tuloksia voidaan verrata myös sarakkeeseen. Seuraavassa esimerkissä alikyselyn tuloksia verrataan sarakkeeseen ahinta.
4.3.5.3 Saman taulun usea läpikäynti
Läpikäynnillä tarkoitetaan tässä yhteydessä taulun esittelyä hakulauseen FROM-osassa. Jos taulu halutaan tarkastaa useammin kuin kerran, on käytettävä apuna joko alikyselyiden mahdollistamia näkyvyysalueita tai useita tarkentimia.
Tietokannanhallintajärjestelmä voisi suorittaa yllä olevan hakulauseen esim. seuravaalla tavalla:
- Hylätään kaikki asiakas-taulun rivit, joilla asnimi-sarakkeen arvo ei ole Kajo (alikyselyn asiakas-taulun läpikäynti).
- Hylätään kaikki asiakas-taulun rivit, joilla asnimi-sarakkeen arvo on Kajo (pääkyselyn asiakas-taulun läpikäynti).
- Verrataan kahden läpikäynnin tuloksia (ts. niitä rivejä, joita ei ole hylätty) käyttäen liitosehtona mpiiri-sarakkeen arvoja. Ne rivit, joilla mpiiri on sama molempien läpikäyntien tuloksissa, valitaan pääkyselyn asiakas-taulusta asnimi- ja mpiiri-sarakkeiden arvot tulostauluun.
- Materialisoidaan tulostaulu.
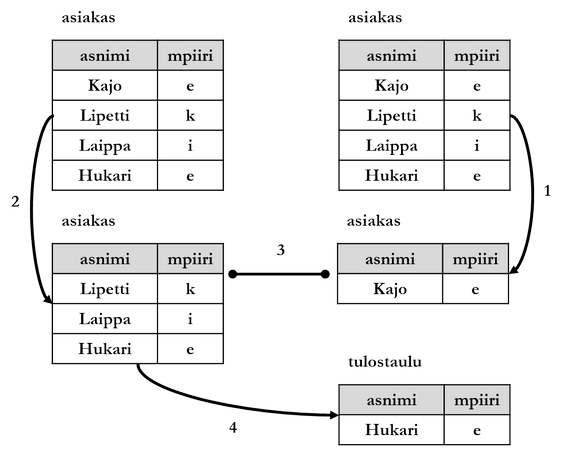
Sama voidaan saavuttaa myös yksitasoisella ratkaisulla käyttämällä eri läpikäynneille eri tarkentimia. Alla olevassa esimerkissä tarkennin a1 vastaa yllä olevan esimerkin pääkyselyä ja tarkennin a2 alikyselyä:
Jako-operaatiolle tyypillistä on tunnistaa, löytyykö liitosehdon muodostavan sarakkeen arvo liitoksen toisen puolen taulun jokaiselta riviltä. Relaatioalgebran operaatioilla jako-operaation voi toteuttaa joko NOT EXISTS-predikaatilla tai koostefunktioiden avulla. Alla esitellään tutkitusti (Matos & Grasser 2002) selkeämpi, koostefunktioilla toteutettu jako-operaatio.
Yllä oleva kysely vertaa laskunumeroittain lasku_rivi-taulun rivien määrää (ts. laskua koskevien erilaisten tuotetunnusten määrää) kaikkien tuotteiden lukumäärään.
4.3.6 Taulurivien lisääminen
Taulurivi lisätään komennolla INSERT. Komento lisää rivin tai rivejä yhteen tauluun. Komennon syntaksi on:
Alla olevassa esimerkissä lisätään tauluun asiakas uusi rivi. Rivin sarakkeiden nimet luetellaan INTO-osassa, ja VALUES-osassa määritetään uudelle riville sen sarakkeiden arvot. Sarakkeiden nimet voidaan luetella missä järjestyksessä tahansa, mutta VALUES-osan listan arvot asetetaan siinä järjestyksessä, kuin sarakkeiden nimet on INTO-osassa lueteltu. Jos lisäys (tai muokkaus tai poisto) onnistuu, SQLite ei anna mitään tulostaulua.
Sarakkeiden nimien listauksesta voidaan jättää sarakkeita pois. Tällöin tietokannanhallintajärjestelmä asettaa luettelemattomien sarakkeiden arvoksi tyhjäarvon, oletusarvon tai jonkin triggerin ennalta määräämän arvon. Sarakkeiden nimiä täytyy olla INTO-osassa lueteltuna yhtä monta kuin VALUES-listassa on sarakkeita. Poikkeuksena tähän sääntöön sarakkeiden nimien listaus voidaan jättää kokonaan pois, jolloin VALUES-osan listassa täytyy olla yhtä monta arvoa kuin taulussa on sarakkeita. Arvot listataan tässä tapauksessa siinä järjestyksessä kuin sarakkeet ovat taulussa.
Sarakkeelle voidaan antaa arvo myös alikyselyn tuloksiin perustuen. Alikyselyn täytyy tällöin palauttaa ainoastaan yksi arvo, joka voi olla myös tyhjäarvo. Lisäyslauseen syntaksi muuttuu tässä tapauksessa niin, että vakion sijaan pilkkulistalla esitetään hakulause:
Joissakin tietokannanhallintajärjestelmissä (esim. PostgreSQL) voidaan yhdellä INSERT-lauseella lisätä useita rivejä seuraavan syntaksin mukaisesti:
Taulurivejä voidaan myös lisätä toisesta taulusta, ts. uudet rivit voivat perustua aiemmin tietokantaan tallennettuun dataan. Tällöin komennon syntaksi on seuraava:
Myös tässä tapauksessa on syytä huomata, että INTO-osassa täytyy olla lueteltuna yhtä monta saraketta kuin lähdetaulusta valitaan SELECT-osassa. Hakulauseeseen voidaan asettaa miten monimutkaisia ehtoja vain: sarakkeiden arvojen tarkistuksia, alikyselyitä, koostefunktioita jne.
Se, miten tietokannanhallintajärjestelmä suoriutuu tilanteesta, jossa tietotyypit kohde- ja lähdetaulun välillä eroavat, riippuu tuotteesta. Joissakin tuotteissa lisäystä ei sallita, jos tietotyyppi, merkistökoodaus tai sarakkeen koko eroavat kun taas jotkin tuotteet yrittävät lisäystä esim. katkaisemalla merkkijonoja tai tekemällä tyyppimuunnoksia.
4.3.7 Taulurivien muokkaaminen
Yhden taulun sarakkeiden arvoja voidaan muuttaa komennolla UPDATE. Komennon syntaksi on:
Jossa SET-osassa määrätään, minkä sarakkeiden arvoja muokataan ja miten, ja WHERE-osassa määrätään, minkä rivien osalta sarakkeiden arvoja muokataan.
Jotkin tietokannanhallintajärjestelmät eivät salli itse määriteltyjen tarkentimien käyttöä UPDATE- ja DELETE-lauseissa.
Myös lausekkeeseen voidaan asettaa alikysely. Seuraavassa asetetaan sellaisten tuotteiden, joiden väriä ei ole määritelty, hinta samaksi kuin halvimman tuotteen hinta. SET-osan alikyselyssä tai WHERE-osassa voidaan asettaa miten monimutkaisia ehtoja vain.
4.3.8 Taulurivien poistaminen
Taulusta voidaan poistaa rivejä komennolla DELETE. Kuten INSERT- ja UPDATE-komennot, DELETE vaikuttaa vain yhden taulun riveihin. Komennon syntaksi on:
Esimerkiksi:
Lauseen WHERE-osassa voidaan asettaa miten monimutkaisia ehtoja vain. Jos WHERE-osa jätetään pois, poistetaan kaikki rivit. DELETE-lause ei varsinaisesti poista rivejä, vaan asettaa ne ylikirjoitettaviksi. Hakulause tauluun ei näytä DELETE-käskyllä poistettuja rivejä, mutta joutuu kuitenkin lukemaan ne.
These are the current permissions for this document; please modify if needed. You can always modify these permissions from the manage page.