More on GPU programming, Part 1
Kernels, threads and blocks
HIP/CUDA applications
- A GPU application is divided into
- kernels, which are executed on HIP/CUDA devices, and
- the host program, which is executed on the host device.

- A kernel can still call separate subroutines on the device side.
- The host program can only call subroutines marked as kernels.

Global index space
- The host program must define a specific index space before each kernel launch.
- After the kernel is launched, this index space defines global index numbers for a set of threads (work-items).

Blocks (work-groups)
- Threads are divided into blocks (work-groups) as defined by the host program:

- Each block gets its own block index.
- Additionally, each thread within a block gets its own local index,
- Indexing can be one-, two- or three-dimensional
Example of Thread Indexing
- Below is an example of a situation where 16 threads are divided into four blocks, each containing four threads:
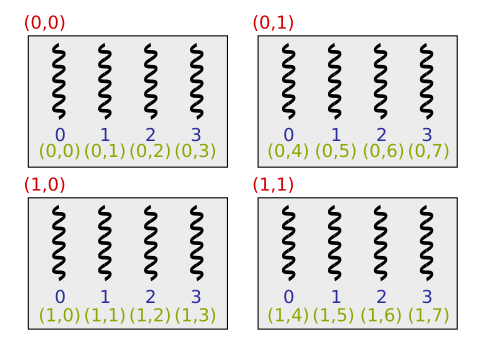
- In reality, there should be 32 or 64 multiple threads in a block.
A HIP / CUDA Kernel Example
- A simple HIP kernel as a refresher:
__global__ void add_one(int *buffer, int n) {
const int idx = threadIdx.x + blockIdx.x * blockDim.x;
if(idx < n)
buffer[idx]++;
}- The
__global__keyword designates the subroutine as a kernel. - The
__device__keyword designates the subroutine as a pure device subroutine, which can only be called from a kernel or another device subroutine. - Indexing:
blockIdx.x= The block index number in the x dimension.blockDim.x= The block size in the x dimension.threadIdx.x= The local thread index number within the block in the x dimension.
Example of a CUDA core
- A simple CUDA core as a refresher:
__global__ void add_one(int *buffer, int n) {
const int global_id = blockIdx.x * blockDim.x + threadIdx.x;
if(global_id < n)
buffer[global_id]++;
}__global__-keyword would make the subroutine a kernel__device__-keyword would make the subroutine a pure CUDA subroutine, which can be called from the kernel alone or from another CUDA subroutine- Indexing:
- blockIdx.x = Thread group index number in dimension x
- blockDim.x = Thread group size in dimension x
- threadIdx.x = Thread local index number in dimension x
delete this paragraph
—Thread Execution Paths
- The threads executed by the
add_onekernel can follow two different execution paths:

- The program code assumes that the global index space is larger than the array
buffer - Therefore, the kernel does not contain a loop, and the
if(idx < n)condition ensures that extra threads do not cause a buffer overflow:

Index management (OpenCL)
| Subprogramme | Explanation |
|---|---|
| uint get_work_dim () | The dimension of the global space |
| size_t get_global_size (uint D) | Size of global space / threads total |
| size_t get_global_id (uint D) | Global index number of the strand |
| size_t get_local_size (uint D) | Size of local space/strand group size |
| size_t get_local_id (uint D) | Local index number of the column |
| size_t get_num_groups (uint D) | Number of column groups |
| size_t get_group_id (uint D) | Seed group index number |
delete this section
—
- Example:
const int local_id = get_local_id(0);
const int local_size = get_local_size(0);
const int idx = get_group_id(0);
const int jdx = get_group_id(1);
for(int i = local_id; i < N; i += local_size)
...
// Säikeet laskevat yhdessä muuttujaan value jotain...
// Vain säieryhmän ensimmäinen säie tallentaa lopullisen tuloksen
if(local_id == 0)
A[idx*N+jdx] = value;Index management
| Variable | Explanation |
|---|---|
| dim3 gridDim | Number of seed groups |
| dim3 blockDim | Size of the column group |
| uint3 blockIdx | Seed group index number |
| uint3 threadIdx | Local index number of the thread |

- Example:
const int local_id = threadIdx.x;
const int local_size = blockDim.x;
const int idx = blockIdx.x;
const int jdx = blockIdx.y;
for(int i = local_id; i < N; i += local_size)
...
// Threads collectively compute something into the variable value...
// Only the first thread of the work group saves the final result
if(local_id == 0)
A[idx*N+jdx] = value;Work Groups and Subtasks
- Dividing threads into work groups guides the programmer to break down the task into subtasks, which can be solved independently in parallel:

Execution Order of Threads and Work Groups
- The execution order of work groups and threads is not defined.
- The programmer has no control over the behavior of work groups.
- However, the programmer can use barriers to synchronize kernel execution at the work group level:

Thread Intercommunication
- Work-groups cannot communicate with each other during kernel execution.
- Threads within the same work-group can communicate with each other, for example, through shared memory.
- Kernels requiring global communication must be split into multiple kernels. Kernel launch serves as a global synchronization point.
Work-Groups and Compute Units
- A GPU comprises one or more compute units (CU) or streaming multiprocessors (SM), each of which contains one or more processing elements (PE).
- Typically, each compute unit is responsible for executing a work-group, and a single compute unit may handle multiple work-groups simultaneously.

- Only the runtime system needs to know the actual structure of the GPU:

Memory Model
- An individual thread has access to four different types of memory regions:

Global memory
- Global memory (or device memory) is a memory area, where each thread has read and write access regardless of the thread group they belong to.

- The majority of video memory is accessible in the form of global memory.
- Global memory is typically implemented outside the GPU chip, limiting memory bandwidth and resulting in latency in the order of hundreds of clock cycles.
- In modern GPUs, global memory is accessed through caching mechanisms.
Global memory in OpenCL
- Global and standard memory is managed in OpenCL using the
cl::Bufferclass:
remove this section
—cl::Buffer::Buffer(
const Context& context,
cl_mem_flags flags,
::size_t size,
void * host_ptr = NULL,
cl_int * err = NULL) - The flag (
flags)CL_MEM_READ_WRITEallocates read-write memory space - If
host_ptr != 0and the flagCL_MEM_COPY_HOST_PTRare set, the data pointing tohost_ptris automatically transferred to the GPU memory - Other interesting flags:
CL_MEM_USE_HOST_PTR,CL_MEM_ALLOC_HOST_PTR,CL_MEM_HOST_WRITE_ONLY,CL_MEM_HOST_READ_ONLYandCL_MEM_HOST_NO_ACCESS
Global memory in HIP and CUDA
All the following code works for CUDA too, simply replace the hip-prefix with cuda.
- The global memory cache can be allocated in HIP using the
hipMallocsubroutine:
- A two-dimensional \(N \times M\) array can be allocated using the
hipMallocPitchfunction.
- Here
MandNmust be provided,devptris populated with a pointer in memeory to where the 2D array was allocated, and the value ofpitchgets populated with the distance in bytes between the first element of each row. - The
pitchdistance is primary to align rows to memory words, so rows can be read in the minimum number of memory operations. The gains from using this over simplyhipMallocmight not be significant. - In any case, the elements of such an array, let's call it
A, can be accessed as follows:
size_t _pitch = pitch / sizeof(int);
int elem1 = A[3 * _pitch + 5]; // A[3][5]
int *line = A[7 * _pitch]; // 7th line
int elem2 = line[14]; // A[7][14]- A three-dimensional array can be allocated using the
hipMalloc3Dfunction. - The allocated memory is released using the
hipFreefunction.
- The HIP library also provides
hipMallocHostandhipFreeHostfunctions for allocating page-locked / pinned memory on the host device. This type of memory allocation speeds up memory transfers, but it comes with risks such as potential failures when allocating large arrays or negative impacts on overall hardware performance.
Global variables
- HIP and CUDA also supports global variables:
__device__ double devData; // Global variable visible to HIP-/CUDA-device
__device__ double* devPointer; // Global pointer visible to HIP-/CUDA-device- The values of global variables are set on the host program side:
double hostData = 6.0;
hipMemcpyToSymbol(HIP_SYMBOL(devData), &hostData, sizeof(double));
double* hostPointer;
hipMalloc(&hostPointer, 256*sizeof(double));
hipMemcpyToSymbol(HIP_SYMBOL(devPointer), &hostPointer, sizeof(hostPointer));Note HIP_SYMBOL wrapper is a macro that isn't needed in the CUDA code. For HIP compiled toward ROCm devices it doesn't appear to be necessary either, but if you want to write HIP code with cross compatibilities it might be necessary to include the wrapper.
Local memory
- Local memory, usually called shared memory, is a memory area that is visible only to threads in the same work-group:

- Local memory is typically used when threads within the same workgroup want to share data with each other.
- In modern GPUs, local memory is implemented as part of the GPU chip (typically each computing unit has its own local memory), making local memory about an order of magnitude faster than global memory.
- In both CUDA and HIP terminology, local memory is referred to as shared memory.
Local memory in OpenCL
- The local memory buffer can be statically allocated inside the kernel:
__kernel void ydin(...) {
__local float buff[256];
const int local_id = get_local_id(0);
buff[local_id] = local_id;
...
}remove this section
—- The memory area can also be allocated dynamically at kernel boot time:
ydin.setArg(0, cl::Local(256*sizeof(float));
queue.enqueueNDRangeKernel(ydin, ...);- Or alternatively, by using functors:
typedef cl::make_kernel<cl::LocalSpaceArg, ...> createKernel;
typedef std::function<createKernel::type_> KernelType;
KernelType ydin = makeKernel(...);
ydin(EnqueueArgs(...), cl::Local(256*sizeof(float), ...);- The dynamically allocated local memory buffer is thus passed as an argument:
__kernel void ydin(__local float *buff, ...) {
const int local_id = get_local_id(0);
buff[local_id] = local_id;
...
}Local memory in CUDA
- The local memory buffer can be statically allocated inside the kernel:
__global__ void kernel(...) {
__shared__ float buff[256];
const int idx = threadIdx.x;
buff[idx] = idx;
...
}Note that statically means that the size of
buffmust be known to the compiler.The memory area can also be allocated dynamically at kernel boot time:
kernel<<<WG_COUNT, LOCAL_SIZE, 256*sizeof(float)>>>(...);- The dynamically allocated local memory buffer is passed to the kernel as an external (
extern) variable:
__global__ void kernel(...) {
extern __shared__ float buff[];
const int idx = threadIdx.x;
buff[idx] = idx;
...
}Setting the width of memory banks
- Some Nvidia GPUs (e.g. CC 3.x) work more efficiently when the so-called memory bank width of the local memory is adjusted using the
cudaDeviceSetSharedMemConfigsubroutine:
- Argument
cudaSharedMemBankSizeFourBytesets the bank width to 4 bytes (float) - Argument
cudaSharedMemBankSizeEightBytesets the bank width to 8 bytes (double) - Subroutine called before placing the kernel in the command line
Note HIP similarly has hipDeviceSetSharedMemConfig(), but it only works on compatible CUDA devices as it isn't a feature on AMD's devices.
this seems like an overly technical and niche thing to include, only a thing on some NVIDIA devices and not at thing on AMD devices at all
—Constant memory
- Constant memory is a memory region visible to all threads, where the content remain the same during kernel execution.
- Constant memory is limited in size, but it is faster than global memory.

Standard memory in OpenCL
- The host program can allocate standard memory by passing the
CL_MEM_READ_ONLYflag to thecl::Bufferclass's formation function - The allocated buffer object is passed to the kernel normally, but is specified by the
__constantkeyword in the argument:
__kernel void ydin(__constant float *buff, ...) {
const int local_id = get_local_id(0);
float a = buff[local_id]; // OK
buff[local_id] = 7.0; // Virhe
}delete
—- The host program sees the
bufftable as a symbol to which data can be transferred using thehipMemcpyToSymbolmethod:
hipError_t hipMemcpyToSymbol(
const char *symbol,
const void *src,
size_t sizeBytes,
size_t offset = 0,
enum hipMemcpyKind kind = hipMemcpyHostToDevice); - Example:
__constant__ float buff[256];
float data[256];
// Fill the data array here
hipMemcpyToSymbol (buff, data, 256*sizeof(float));- Alternatively, you can also use the
hipMemcpyToSymbolAsyncmethod.
Private memory
- Private memory is an area of memory that is visible only to a single thread:

- The compiler might store data in private memory when computing unit's resources are limited.
- For instance if a thread tries to allocate more memory than is available in the registers it has been allocated.
- Typically implemented as part of video memory, so explicitly using private memory is not recommended.
Relaxed Consistency in HIP and CUDA
- The HIP and CUDA memory models are consistent from the perspective of a single thread.
- In this context, consistency means that memory operations occur in a predetermined order.
- The HIP and CUDA memory models are not consistent across different threads.
- This means that the execution order of memory operations performed by different threads is not defined.
- Achieving memory consistency in some situations is possible but requires a special synchronization command.
What is it that is trying to be said here?
—Command Queue
- Memory transfers, kernel launches, and other similar operations are placed in a command queue.
- Each GPU has its own default command queue, or a command queue must be created separately.
- A single GPU can also have multiple command queues.
- The runtime system executes the commands placed in the command queue independently.
- The host program returns immediately from functions submitted to the command queue, making them non-blocking operations.
- Some operations can also be executed in a blocking version, where the host program waits for the command to complete.
- The host program and GPU can synchronize their execution, for example by using a barrier.

Creating a command line in OpenCL
- A command string is encapsulated inside the
cl::CommandQueueclass, whose build function takes as arguments the OpenCL context and the OpenCL device to which the command string is to be attached:
cl::CommandQueue::CommandQueue(
const Context& context,
const Device& device,
cl_command_queue_properties properties = 0,
cl_int * err = NULL) delete this
—Data transfers in OpenCL
- The
enqueueWriteBuffermember function of the command line sets the command to write data from host memory Setting the blocking_writeflag on the buffer object toCL_TRUEmakes the call block i.e. the subroutine returns only when the transfer is complete
cl_int cl::CommandQueue::enqueueWriteBuffer(
const Buffer& buffer,
cl_bool blocking_write,
::size_t offset,
::size_t size,
const void * ptr,
const VECTOR_CLASS<Event> * events = NULL,
Event * event = NULL) delete this
—- The
enqueueReadBuffermember function in the command line sets the command to read data from the Buffer object to the host device memory blocking_readsetting the flag toCL_TRUEmakes the call block i.e. the subroutine will not return until the transfer is complete
cl_int cl::CommandQueue::enqueueReadBuffer(
const Buffer& buffer,
cl_bool blocking_read,
::size_t offset,
::size_t size,
const void * ptr,
const VECTOR_CLASS<Event> * events = NULL,
Event * event = NULL) Queuing the kernel in OpenCL
- In the C++ wrapper, the kernel object is encapsulated inside the
cl::Kernelclass, whose build function takes the Program object and kernel name as arguments:
cl::Kernel::Kernel(const Program& program,
const char * name,
cl_int * err = NULL) - The arguments to the kernel are set one at a time by the
setArgmember function:
template <typename T>
cl_int cl::Kernel::setArg(cl_uint index, T value)delete this
—- The kernel startup command is placed in the command line using the
enqueueNDRangeKernelmember function:
cl_int cl::CommandQueue::enqueueNDRangeKernel(
const Kernel& kernel,
const NDRange& offset,
const NDRange& global,
const NDRange& local,
const VECTOR_CLASS<Event> * events = NULL,
Event * event = NULL)- The size of the global index space is set by the
globalargument and the size of the thread group is set by thelocalargument.
Radio link
- Functors in C++11 provide a much more convenient way to manage kernels
- In the most common case, we first define a new subroutine:
typedef cl::make_kernel<...> createKernel;- The types of kernel arguments (cl::Buffer&, double, int) are passed inside
<>closures - A freely-nameable
createKernelsubroutine (actually an olion) can be used to create kernel objects whose argument list matches the list passed inside<>closures
delete this
—- A new type of core object is defined as:
typedef std::function<createKernel::type_> KernelType;- A freely-named
KernelTypetype can refer to a kernel object whose argument list matches the argument list provided in thecreateKernelsubroutine definition - The kernel can now be created using the
createKernelsubroutine:
KernelType ydin = createKernel(program, "ytimen_nimi");- The kernel can now be called almost like a normal subroutine:
kernel(
cl::EnqueueArgs(
queue,
cl::NDRange(GLOBAL_SIZE_0, GLOBAL_SIZE_1, GLOBAL_SIZE_2),
cl::NDRange(LOCAL_SIZE_0, LOCAL_SIZE_1, LOCAL_SIZE_2)),
...);- The kernel arguments come after the
cl::EnqueueArgsalias
- Example:
typedef cl::make_kernel<cl::Buffer&, int> createAddOneKernel;
typedef std::function<createAddOneKernel::type_> AddOneKernelType;
AddOneKernelType kernel = createAddOneKernel(program, "add_one");
kernel(
cl::EnqueueArgs(
queue, cl::NDRange((N/256+1)*256), cl::NDRange(256)),
deviceBuffer, N);Creating a Command Queue in HIP
- In HIP a commend queue is called a stream.
- Each device has its own default command queue, which is used when no specific command queue is defined.
- This is called the 0 stream, and it exhibits some special synchronization bahviour.
- Switching the device using
hipSetDevicechanges the currently active default command queue. - Additionally, a command queue can be created explicitly using the
hipStreamCreatefunction:
- Similarly, a command queue is destroyed using
hipStreamDestroy:
These functions allow HIP programs to manage multiple command queues for asynchronous execution of kernels and memory operations on the GPU.
Sometimes speedups can even be achieved from using multiple streams. 
Data Transfers in HIP
- A blocking data transfer is initiated using the
hipMemcpyfunction:
hipError_t hipMemcpy(
void *dst, // Destination buffer
const void *src, // Source buffer
size_t sizeBytes, // Size of the transfer in bytes
hipMemcpyKind kind); // Type of the transfer- Allowed values for the
kindargument are:hipMemcpyDefaulthipMemcpyHostToHosthipMemcpyHostToDevicehipMemcpyDeviceToHosthipMemcpyDeviceToDevice
- The default option in the list is the recommended in modern HIP. It will automatically determine the kind of transfer based on the
dstandsrcpointers. Note that this does mean that if you supply two host pointers by accident, when you actually wanted to transfer data to the device, the compiler won't know that it is a mistake and thus will not inform you of the error.
Non-blocking Data Transfers in HIP
- Non-blocking data transfer is performed using the
hipMemcpyAsyncfunction:
hipError_t hipMemcpyAsync(
void* dst, // Destination buffer
const void* src, // Source buffer
size_t sizeBytes, // Size of the transfer in bytes
hipMemcpyKind kind, // Type of the transfer
hipStream_t stream = 0 // Stream to use for the transfer
);- The command queue to be used is specified with the
streamargument. - By default, the 0 stream is used.
- When using host-side memory with
hipMemcpyAsync, it must be pinned memory. Pinned memory ensures that the buffer remains in physical RAM, allowing the DMA engine to perform asynchronous transfers efficiently. - If the host-side memory is not pinned, the copy operation will be synchronous instead.
- Pinned memory can be allocated using the
hipHostMallocfunction:
- Pinned memory is released using the
hipHostFreefunction:
Queuing the kernel in HIP and CUDA
- Starting the kernel in HIP and CUDA
gridSizedetermines the number of workgroups. Can be a number ordim3blockSizeto determine the number of threads per workgroup. May be a number ordim3sharedMemSizespecifies the amount of dynamically allocated shared memory in bytesstreamspecifies the stream to useargsspecifies the kernel arguments
Warning regarding Non-Blocking Data Transfers
- The runtime system ensures that a kernel is not launched until all preceding commands in the queue have completed execution.
- Therefore, non-blocking data transfers are safe from the kernel's perspective.
- However, on the host side, it is crucial to remember that data transfers occur asynchronously!
- The host program should use blocking transfers or synchronize its execution with the GPU before it can safely use a buffer involved in a data transfer!
- For example, the outcome of the following situation is undefined:
// Initiating non-blocking transfer hostBuffer -> deviceBuffer
hipMemcpyAsync(deviceBuffer, hostBuffer, N*sizeof(int), hipMemcpyHostToDevice);
for(int i = 0; i < N; i++)
hostBuffer[i] = i; // The i-th element of hostBuffer may have been
// transferred to GPU memory before this line executes
// or it may be transferred to GPU memory later- A similar situation occurs here as well:
Command queue synchronisation
- The host program can synchronize its execution with the HIP command queue as follows:
hipStreamSynchronize(stream); // The function returns only after all commands
// in the command queue have been executed.- Alternatively, the host program can wait until the active CUDA device has completed all the tasks assigned to it:
On Error Handling
- Most HIP functions return an error variable of type
hipError_t. - Enqueueing a kernel in the command queue does not return an error code in HIP, but the error code must be checked separately:
hipError_t hipGetLastError(void)returns the error code of the last command and resets it tohipSuccess.hipError_t hipPeekAtLastError(void)returns the error code of the last command.
Warning
- Asynchronous execution of commands in the command queue may also cause issues with error handling.
- The function/member function that enqueues the command returns information only about errors that occurred when the command was enqueued.
- Actual errors related to executing the command are reported later!
- Example:
// Correctly functioning memory transfer, blocking / synchronous
err = hipMemcpy(deviceBuffer, hostBuffer, N*sizeof(int), hipMemcpyHostToDevice);
if(err != hipSuccess) { ...
// Incorrectly functioning kernel, non-blocking / asynchronous
add_one<<<gridSz, blockSz>>>(deviceBuffer, N);
if(hipGetLastError() != hipSuccess) {
// The kernel launch was successful, so no error here!!!
}
// Correctly functioning memory transfer, blocking / synchronous
hipMemcpy(hostBuffer, deviceBuffer, N*sizeof(int), hipMemcpyDeviceToHost);
if(err != hipSuccess) {
// Errors caused by add_one kernel will appear here!!!
}- You can synchronize the host program execution after each asynchronous command, where
hipStreamSynchronize(hipStream_t stream), orhipDeviceSynchronize()return runtime error codes. - Example:
add_one<<<gridSz, blockSz>>>(deviceBuffer, N);
if(hipGetLastError() != hipSuccess) {
// Report errors that occurred when the command was enqueued
}
#if DEBUG
err = hipDeviceSynchronize();
if(err != hipSuccess) {
// Report runtime errors
}
#endif- Compiling the program with the
-D DEBUGflag activates the debugging code shown above.
Writing kernels
Reminder
- For workgroups and workitems, the order of execution is not well-defined.
- For example, the following code is not well-defined:
Synchronization
- However, the programmer can use barriers to synchronize the execution of kernels at the workgroup level:
Synchronisation in OpenCL
- Threads belonging to the same thread group can synchronize using the
barrierbarrier:
void barrier (cl_mem_fence_flags flags);- The
flagsflag given as an argument can be a combination of the following:CLK_LOCAL_MEM_FENCEflag guarantees that all operations in local memory have completedCLK_GLOBAL_MEM_FENCEflag guarantees that all operations in global memory have completed
- All threads must execute the same
barriercommand!
delete this
—Synchronisation in HIP and CUDA
- Threads in the same workgroup can synchronize using the
__syncthreads()function. - Additionally, HIP and CUDA provides the
__threadfence_block(),__threadfence(), and__threadfence_system()functions, which offer weaker synchronization guarantees but can be useful in some scenarios. - Note that all threads must call the same barrier!
- At the moment, the
__syncthreads()function suffices.
Examples
- For example, a previous program code could be corrected as follows:
__global__ void swap(int *buff) {
int local_id = threadIdx.x;
int local_size = blockDim.x;
// Each thread reads a number from the array
int x = buff[local_id];
// Wait until each thread has read its own number into variable x
__syncthreads();
// Write the result back to the array
buff[local_size-local_id-1] = x;
}- The following example does not work or leads to an undefined outcome:
__global__ void swap(int *buff, int n) {
int local_id = threadIdx.x;
// Only rearrange the first n elements
if (local_id < n) {
int x = buff[local_id];
// Some threads might not execute this line at all, causing the threads
// that enter the if block to wait forever for their arrival!
__syncthreads();
buff[n - local_id - 1] = x;
}
}Printf
- HIP and CUDA support the use of the
printffunction inside a kernel. - Printing from a kernel significantly slows down the program execution, so use it only for debugging purposes and avoid unnecessary prints.
- Example:
__global__ void add_one(int *buffer, int n) {
const int global_id = threadIdx.x + blockIdx.x * blockDim.x;
if(global_id < n)
buffer[global_id]++;
else
printf("Thread %d did nothing.\n", global_id);
}- You might have to set the environment variable
HCC_ENABLE_PRINTFforprintfto work in HIP
These are the current permissions for this document; please modify if needed. You can always modify these permissions from the manage page.